
मेरी परियोजना लगभग तैयार है, यह केवल प्रक्रिया का परीक्षण करने के लिए बनी हुई है और आप अपने आप को धड़ पर एक पायदान बना सकते हैं।
इस लेख में मैं अपने क्लस्टर के "ड्राइविंग बल" को बढ़ाने के बारे में बात करूंगा - दास , साथ ही संक्षेप में और उन संसाधनों के लिए उपयोगी लिंक प्रदान करूंगा जो मैंने अपने पूरे प्रोजेक्ट में उपयोग किए थे। शायद, कुछ के लिए, लेख स्रोत कोड और कार्यान्वयन विवरणों पर बहुत कम लग रहा था, इसलिए लेख के अंत में मैं गितुब का लिंक प्रदान करूंगा
खैर, आदत से बाहर, शुरुआत में मैं उस वास्तुकला का एक चित्र दूंगा जिसे मैंने क्लाउड पर तैनात करने में कामयाब रहा।
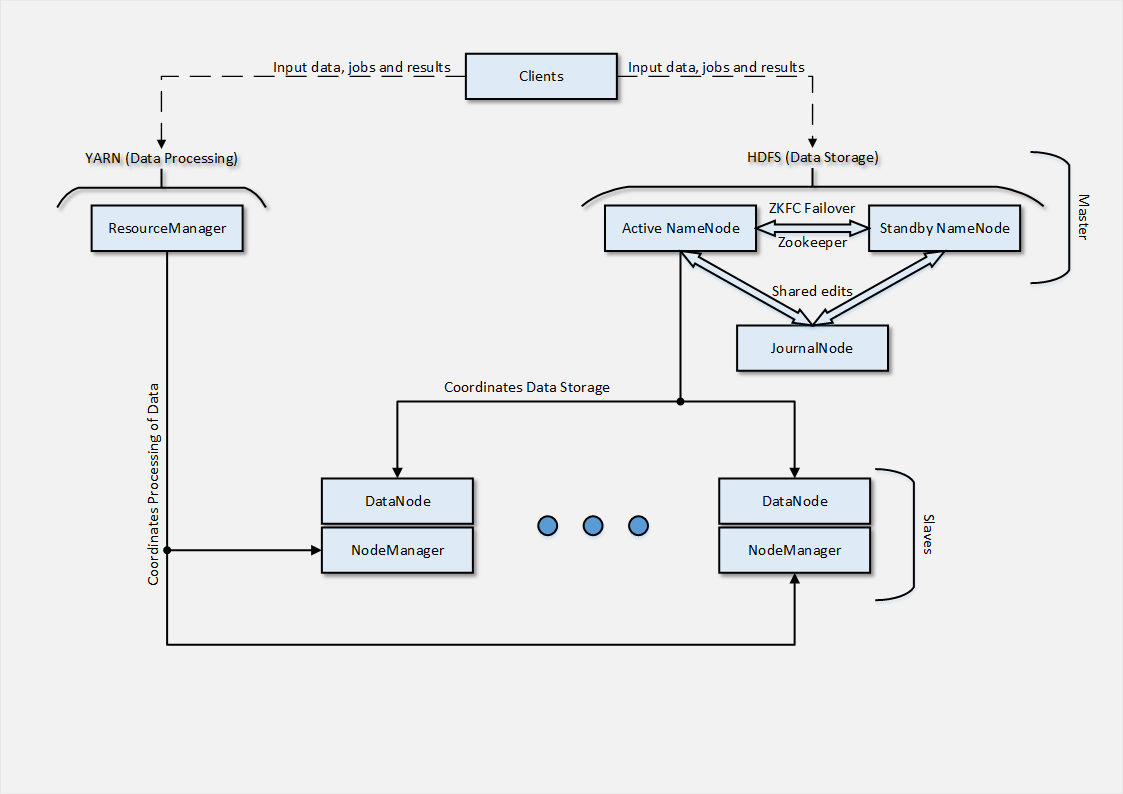
हमारे मामले में, रन की टेस्ट प्रकृति को देखते हुए, केवल 2 स्लेव नोड्स का उपयोग किया गया था, लेकिन वास्तविक परिस्थितियों में उनमें से दर्जनों होंगे। अगला, मैं संक्षेप में वर्णन करूंगा कि उनकी तैनाती कैसे आयोजित की गई थी।
दासों की तैनाती
जैसा कि आप वास्तुकला से अनुमान लगा सकते हैं, स्लेव नोड में 2 भाग होते हैं, जिनमें से प्रत्येक मास्टर्स वास्तुकला के हिस्सों से जुड़े कार्यों के लिए जिम्मेदार है। DataNode NameNode के साथ स्लेव नोड के इंटरैक्शन का बिंदु है, जो डेटा के वितरित भंडारण का समन्वय करता है।
DataNode प्रक्रिया NameNode नोड पर सेवा से जुड़ती है, जिसके बाद ग्राहक सीधे फ़ाइल संचालन के साथ DataNode नोड का उपयोग कर सकते हैं। यह भी ध्यान देने योग्य है कि DataNode नोड्स डेटा प्रतिकृति के मामले में एक दूसरे के साथ संवाद करते हैं , जो बदले में आपको RAID सरणियों का उपयोग करने से दूर होने की अनुमति देता है, क्योंकि प्रतिकृति तंत्र पहले से ही सॉफ्टवेयर में रखा गया है।
DataNode को तैनात करने की प्रक्रिया काफी सरल है:
- जावा के रूप में आवश्यक शर्तें स्थापित करना;
- Hadoop वितरण के पैकेज के साथ रिपॉजिटरी जोड़ना;
- DataNode सेट करने के लिए आवश्यक निर्देशिकाओं की रीढ़ बनाना;
- टेम्पलेट और कुकबुक विशेषताओं के आधार पर कॉन्फ़िगरेशन फ़ाइलों की पीढ़ी
- वितरण पैकेजों को स्थापित करना ( हडूप-एचडीएफ़-डेटानोड )
-
service hadoop-hdfs-datanode start
प्रक्रिया कोservice hadoop-hdfs-datanode start
; - तैनाती प्रक्रिया की स्थिति का पंजीकरण।
परिणामस्वरूप, यदि सभी डेटा सही है और कॉन्फ़िगरेशन लागू किया गया है, तो आप NameNode नोड्स के वेब इंटरफ़ेस पर जोड़े गए दास नोड्स देख सकते हैं। इसका अर्थ है कि वितरित डेटा संग्रहण से संबंधित फ़ाइल संचालन के लिए DataNode नोड अब उपलब्ध है। फ़ाइल को एचडीएफएस में कॉपी करें और अपने लिए देखें।
NodeManager , बदले में, ResourceManager के साथ बातचीत करने के लिए जिम्मेदार है, जो उन्हें निष्पादित करने के लिए उपलब्ध कार्यों और संसाधनों का प्रबंधन करता है। NodeManager की परिनियोजन प्रक्रिया DataNode के मामले में प्रक्रिया के समान है, स्थापना और सेवा के लिए पैकेज के नाम में अंतर के साथ ( हैडूप-यार्न-नोडमैनगर )।
दास- नोड्स की तैनाती के सफल समापन के बाद - हम अपने क्लस्टर को तैयार मान सकते हैं। यह पर्यावरण चर (hadoop_env, यार्न_नेव, आदि) को सेट करने वाली फ़ाइलों पर ध्यान देने योग्य है - चर में डेटा क्लस्टर में वास्तविक मूल्यों के अनुरूप होना चाहिए। इसके अलावा, यह चर के मूल्यों की शुद्धता पर ध्यान देने योग्य है जिसमें डोमेन नाम और पोर्ट जिस पर यह या वह सेवा चल रही है, संकेत दिए गए हैं।
हम एक क्लस्टर के स्वास्थ्य को कैसे सत्यापित कर सकते हैं? सबसे किफायती विकल्प ग्राहक नोड्स में से एक से कार्य शुरू करना है। उदाहरण के लिए, इस तरह:
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar pi 2 5
हडॉ-मैप्रेड्यूज़-उदाहरण-2.2.0.jar कार्य विवरण फ़ाइल (मूल स्थापना में उपलब्ध) का नाम है, pi कार्य के प्रकार (इस मामले में MapReduce Task) को इंगित करता है, और 2 और 5 कार्यों के वितरण मापदंडों के लिए जिम्मेदार हैं ( अधिक विस्तार से - यहाँ )।
परिणाम , सभी गणनाओं को पूरा करने के बाद, आंकड़ों के साथ टर्मिनल पर आउटपुट और गणनाओं का परिणाम होगा, या वहां डेटा के आउटपुट के साथ आउटपुट फ़ाइल का निर्माण (डेटा की प्रकृति और उनके आउटपुट का प्रारूप .jar फ़ाइल में वर्णित कार्य पर निर्भर करता है)।
<अंत />
ये क्लस्टर और पाई हैं, प्रिय हब्रज़िटेली । इस स्तर पर - मैं इस समाधान के लिए आदर्श होने का दिखावा नहीं करता, क्योंकि कुकबुक कोड में अभी भी परीक्षण / सुधार / संपादन के चरण हैं। मैं अपना अनुभव साझा करना चाहता था और एक हडोप क्लस्टर को तैनात करने के लिए एक और दृष्टिकोण का वर्णन करता हूं - दृष्टिकोण सबसे सरल और सबसे रूढ़िवादी नहीं है, मैं कहूंगा। लेकिन यह ऐसी अपरंपरागत स्थिति में है कि "स्टील" को तड़पाया जाता है। मेरा अंतिम लक्ष्य हमारे निजी क्लाउड के लिए Amazon MapReduce सेवा का एक मामूली प्रतिपक्ष है।
मैं वास्तव में उन सभी से सलाह का स्वागत करता हूं जिन्होंने लेखों की इस श्रृंखला पर ध्यान दिया है और ध्यान दिया है ( विशेषकर मित्र के लिए धन्यवाद जिन्होंने ध्यान दिया और प्रश्न पूछे, जिनमें से कुछ ने मुझे नए विचारों की ओर अग्रसर किया)।
सामग्री लिंक
जैसा कि वादा किया गया था, यहां उन सामग्रियों की एक सूची है, जिन्होंने मेरे सहयोगियों के साथ, परियोजना को स्वीकार्य रूप में लाने में मदद की:
- एचडीपी वितरण पर विस्तृत दस्तावेज - docs.hortonworks.com
- विकी इन द फादर्स, अपाचे हडोप - wiki.apache.org/hadoop
- उनसे दस्तावेज़ीकरण - hadoop.apache.org/docs/current
- वास्तुकला विवरण लेख के संदर्भ में थोड़ा पुराना ()
- 2 भागों में एक अच्छा ट्यूटोरियल - यहाँ
- Martsen से अनुकूलित अनुवाद ट्यूटोरियल - habrahabr.ru/post/206196
- सामुदायिक रसोई की किताब " Hadoop ", जिसके आधार पर मैंने अपनी परियोजना बनाई - Hadoop रसोई की किताब
- अंत में - मेरी विनम्र परियोजना के रूप में यह (अद्यतन से आगे) है - गिटहब
आपका ध्यान देने के लिए आप सभी का धन्यवाद ! टिप्पणियों का स्वागत है! अगर मैं किसी चीज़ में मदद कर सकता हूँ - संपर्क करें! फिर मिलते हैं।
युपीडी। ट्यूटोरियल के अनुवाद, Habré पर एक लेख के लिए एक लिंक जोड़ा गया।