
पिछले कुछ हफ़्ते से मैं एक दिलचस्प (मेरे दृष्टिकोण से) व्यवसाय पर काम कर रहा हूं, जो हमारी कंपनी के निजी क्लाउड के लिए एक Hadoop-as-a-Service समाधान का निर्माण था। सबसे पहले, मैं सोच रहा था कि किस प्रकार का जानवर हैडोप है , बिग डेटा और हडोप के शब्दों का संयोजन क्यों अक्सर सुना जाता है। मेरे लिए, Hadoop से शुरुआत करना खरोंच से शुरू हुआ। बेशक, मैं बिग डेटा एक विशेषज्ञ नहीं था और नहीं था, इसलिए मैं सार में चला गया जितना कि क्लस्टर तैनाती स्वचालन के संदर्भ में प्रक्रियाओं को समझना आवश्यक था।
यह मेरे काम की सुविधा देता है कि कार्य काफी स्पष्ट रूप से तैयार किया गया था - एक क्लस्टर वास्तुकला है , एक Hadoop वितरण है , एक बावर्ची स्वचालन उपकरण है। यह केवल क्लस्टर के कुछ हिस्सों की स्थापना और कॉन्फ़िगरेशन के साथ-साथ इसके उपयोग के लिए विकल्पों से परिचित होने के लिए बना रहा। लेखों में आगे मैं क्लस्टर वास्तुकला, उसके भागों के उद्देश्य, साथ ही साथ कॉन्फ़िगरेशन और स्टार्टअप प्रक्रिया के विवरण को सरल बनाने का प्रयास करूंगा।
क्लस्टर वास्तुकला
अंत में मुझे क्या करने की आवश्यकता थी? यहाँ वास्तुकला के साथ एक योजना मेरे लिए उपलब्ध थी।
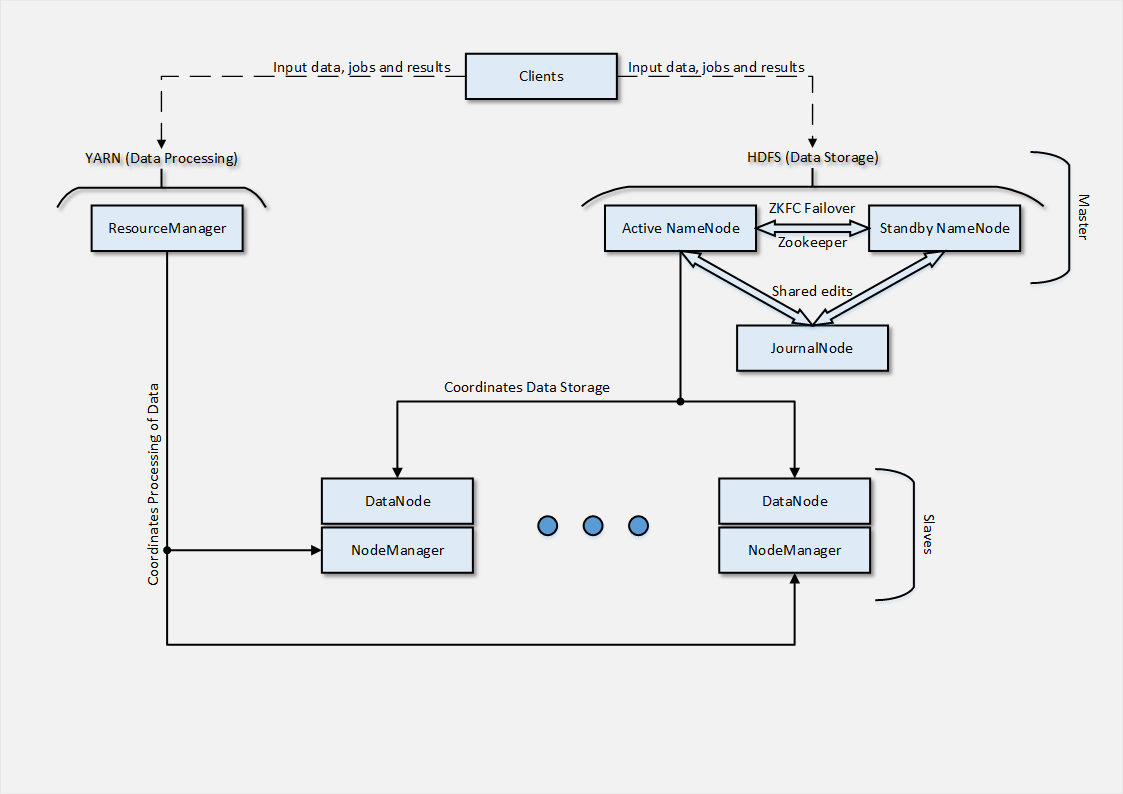
जैसा कि मैंने बाद में महसूस किया - एक काफी सरल नंगे क्लस्टर वास्तुकला ( Hbase , Hive , सुअर और Hado से संबंधित अन्य तृतीय-पक्ष उत्पादों के बिना)। लेकिन, पहली नज़र में - सब कुछ समझ से बाहर था। ठीक है, Google मदद करने के लिए है, और जो समाप्त हो गया है ...
Hadoop क्लस्टर को 3 भागों में विभाजित किया जा सकता है: मास्टर्स , दास और ग्राहक ।
मास्टर्स क्लस्टर के दो मुख्य कार्यों को नियंत्रित करता है - डेटा प्लेसमेंट और कम्प्यूटेशन / प्रोसेसिंग जो इस डेटा से जुड़ा है।
HDFS - Hadoop डिस्ट्रिब्यूटेड फाइल सिस्टम - हमारे आर्किटेक्चर में दर्शाया गया है NameNode और JournalNode डेटा प्लेसमेंट के लिए जिम्मेदार है।
YARN , जिसे MapReduce v.2 के रूप में भी जाना जाता है, कार्यों के असाइनमेंट के समन्वय और वितरित कंप्यूटिंग का संचालन करने के लिए जिम्मेदार है।
दास सभी " गंदे " काम करते हैं, यह वह है जो कंप्यूटिंग से संबंधित कार्यों को प्राप्त करता है और करता है। प्रत्येक स्लेव में क्रमशः एक एचडीएफएस भाग ( डेटानोड ) और एक यार्न भाग ( नोडमैनमैन ) होता है। प्रत्येक भाग संबंधित फ़ंक्शन के लिए ज़िम्मेदार है, चाहे वह डेटा संग्रहण वितरित किया गया हो या वितरित कंप्यूटिंग।
और अंत में, ग्राहक , क्लस्टर के एक प्रकार के राजा जो कुछ भी नहीं करते हैं, लेकिन डेटा और कार्यों को क्लस्टर में आपूर्ति करते हैं, साथ ही परिणाम प्राप्त करते हैं ।
Hadoop जावा में लिखा गया है , इसलिए किसी भी घटक को इसकी आवश्यकता होती है। क्लस्टर के हिस्सों के बीच की बातचीत जावा कक्षाओं के आंतों में छिपी हुई है, लेकिन क्लस्टर कॉन्फ़िगरेशन का केवल एक हिस्सा हमारे लिए सही जगह पर आवश्यक सेटिंग्स बनाकर उपलब्ध है।
डिफ़ॉल्ट रूप से, कॉन्फ़िगरेशन फ़ाइलें पथ / etc / hadoop / conf पर स्थित होती हैं और उन मापदंडों का प्रतिनिधित्व करती हैं जिन्हें क्लस्टर में पुन: असाइन किया जा सकता है:
- hadoop-env.sh और यार्न-env.sh - में पर्यावरण चर के लिए विशिष्ट सेटिंग्स शामिल हैं, यह वह जगह है जहां Hadoop द्वारा आवश्यक पथ और विकल्पों के लिए सेटिंग्स बनाने की सिफारिश की जाती है;
- core-site.xml - इसमें ऐसे मान होते हैं जो क्लस्टर के लिए डिफ़ॉल्ट मानों के बजाय पुन: असाइन किए जा सकते हैं, जैसे कि रूट FS का पता, Hadoop , आदि के लिए विभिन्न निर्देशिकाओं का संकेत;
- hdfs-site.xml - में HDN के लिए सेटिंग्स होती हैं, जैसे NameNode , DataNode , JournalNode , और Zookeeper के लिए भी, जैसे कि डोमेन नाम और पोर्ट जिस पर यह या वह सेवा चल रही है, या निर्देशिका वितरित डेटा को बचाने के लिए आवश्यक है;
- यार्न- site.xml - में रिसोर्स मैनजर और नोडमनेजर के लिए यार्न के लिए सेटिंग्स शामिल हैं, जैसे कि डोमेन नाम और पोर्ट जिस पर यह या वह सेवा चल रही है, प्रसंस्करण के लिए संसाधन आवंटन सेटिंग्स, आदि;
- mapred-site.xml - MapReduce नौकरियों के लिए कॉन्फ़िगरेशन में शामिल है, साथ ही JobHistory MapReduce सर्वर के लिए सेटिंग्स;
- log4j.properties - अपाचे कॉमन्स लॉगिंग फ्रेमवर्क का उपयोग करके लॉगिंग प्रक्रिया का कॉन्फ़िगरेशन शामिल है;
- hadoop-metrics.properties - इंगित करता है कि Hadoop अपनी मीट्रिक कहां भेजेगा, चाहे वह फ़ाइल हो या निगरानी प्रणाली;
- hadoop-policy.xml - क्लस्टर के लिए सुरक्षा और ACL सेटिंग्स;
- क्षमता-अनुसूचक। xml - क्षमतासुधार के लिए सेटिंग्स, जो समयबद्धन कार्यों के लिए जिम्मेदार है और उन्हें निष्पादन कतार में रखने के साथ-साथ कतार में क्लस्टर संसाधनों को वितरित करना है;
तदनुसार, हमारी स्वचालन प्रक्रिया के लिए, न केवल एक स्वचालित स्थापना आवश्यक है, बल्कि इस कॉन्फ़िगरेशन को वास्तव में नोड्स पर संपादित किए बिना इस कॉन्फ़िगरेशन को बदलने और बनाने की क्षमता भी है।
क्लस्टर को HortonWorks (HDP) वितरण संस्करण 2.0 का उपयोग करके उबंटू में तैनात किया गया था।
क्लस्टर बनाने के लिए, मास्टर्स के प्रत्येक भाग के लिए 1 वर्चुअल मशीन, 1 क्लाइंट वर्चुअल मशीन और 2 वर्चुअल मशीनों को स्लेव्स के रूप में आवंटित किया गया था।
रैपर रसोई की किताब लिखते समय , मैंने समुदाय की उपलब्धियों का उपयोग किया, अर्थात् इस परियोजना क्रिस गियानेलोनी , जो एक बहुत सक्रिय डेवलपर बन गया, जल्दी से कुकबुक में पाए जाने वाले कीड़े का जवाब दे रहा था। इस रसोई की किताब ने Hadoop क्लस्टर के विभिन्न हिस्सों को स्थापित करने की क्षमता प्रदान की, मूल क्लस्टर कॉन्फ़िगरेशन को Cookbook विशेषताओं को सेट करके और उनके आधार पर कॉन्फ़िगरेशन फ़ाइलों को उत्पन्न करने के साथ-साथ यह सत्यापित करने के लिए कि क्लस्टर शुरू करने के लिए पर्याप्त कॉन्फ़िगरेशन है।
ग्राहकों की तैनाती स्वचालन
ग्राहक वर्चुअल मशीनें हैं जो एक हडोप क्लस्टर के लिए डेटा और कार्य प्रदान करती हैं, साथ ही वितरित कंप्यूटिंग के परिणामों को कैप्चर करती हैं।
उबन्टू रिपॉजिटरी में होर्टनवर्क्स रेपो के बारे में प्रविष्टियाँ जोड़ने के बाद, क्लस्टर के एक या दूसरे हिस्से के लिए जिम्मेदार विभिन्न एकत्रित डिब पैकेज उपलब्ध हो गए।
हम, इस मामले में, हडूप-क्लाइंट पैकेज में रुचि रखते थे, जिसकी स्थापना निम्नानुसार की गई थी:
package "hadoop-client" do action :install end
बस? यह आसान नहीं हो सकता है, HortonWorks के सहकर्मियों का धन्यवाद जिन्होंने सिस्टम प्रशासकों को स्रोत से Hadoop बनाने से बचाया।
विशेष रूप से ग्राहकों के लिए कॉन्फ़िगरेशन की आवश्यकता नहीं है, वे परास्नातक / दासों के लिए कॉन्फ़िगरेशन पर आधारित हैं ( अगले लेख में विशेषताओं के आधार पर कॉन्फ़िगरेशन फ़ाइलों को बनाने की प्रक्रिया कैसे लागू की गई है)।
परिणामस्वरूप, स्थापना पूर्ण होने के बाद, हम अपने क्लस्टर के लिए कार्य भेज पाएंगे। Hadoop कक्षाओं का उपयोग करते हुए नौकरियां .jar फ़ाइलों में वर्णित हैं। मैं लेखों की एक श्रृंखला के अंत में कार्यों को शुरू करने के उदाहरणों का वर्णन करने का प्रयास करूंगा जब हमारा क्लस्टर पूरी तरह से चालू हो जाएगा।
क्लस्टर ऑपरेशन के परिणाम कार्य की शुरुआत में या कॉन्फ़िगरेशन फ़ाइलों में निर्दिष्ट निर्देशिकाओं में जोड़े जाते हैं।
आगे क्या होना चाहिए? इसके अलावा, जब हम अपने क्लस्टर को कार्य भेजते हैं, तो हमारे मास्टर्स को कार्य (YARN) और इसे पूरा करने के लिए आवश्यक फ़ाइलों (HDFS) को प्राप्त करना चाहिए, और दासों के माध्यम से प्राप्त संसाधनों को वितरित करने की प्रक्रिया को पूरा करना चाहिए। इस बीच, हमारे पास न तो मास्टर्स है और न ही दास । यह क्लस्टर के इन हिस्सों को स्थापित करने और कॉन्फ़िगर करने की विस्तृत प्रक्रिया के बारे में है जो मैं भविष्य के लेखों में बताना चाहता हूं।
भाग 1 एक प्रकाश, परिचयात्मक भाग के रूप में सामने आया, जिसमें मैंने वर्णन किया कि मुझे क्या करने की आवश्यकता है और किस पथ को मैंने कार्य को पूरा करने के लिए चुना।
आगे के हिस्से कोड और हाडोअप क्लस्टर को शुरू करने और कॉन्फ़िगर करने के पहलुओं से अधिक भरे होंगे।
गलतियाँ और विवरण में त्रुटियां स्वागत योग्य हैं, मुझे स्पष्ट रूप से बिग डेटा के क्षेत्र में कुछ सीखना है।
आपका ध्यान देने के लिए आप सभी का धन्यवाद !