परिचय
हेडिंग के रूप में डेटा को व्यवस्थित करने पर पिछले लेखों में ( शीर्षकों के किसी भी रचनाकार की प्रतीक्षा में समस्याओं और शीर्षकों के लिए एक ग्राफ के रूप में उपयोग करना ), हेडिंग के आयोजन पर सामान्य विचारों का वर्णन किया गया था। इस लेख में, मैं पहले से तैयार शीर्ष लेख के आधार पर पाठ के विषय को स्वचालित रूप से निर्धारित करने के लिए संभावित एल्गोरिदम में से एक का वर्णन करूंगा। उसी समय, मैं जानबूझकर जटिल सूत्रों से बचता हूं ताकि इस विचार को व्यक्त किया जा सके कि एल्गोरिथ्म जितना संभव हो उतना सरल है।
शीर्ष डेटा की तैयारी
शुरू करने के लिए, हम यह निर्धारित करेंगे कि हम रूब्रिकेटर के लिए डेटा किस रूप में तैयार करेंगे।
- 1. शीर्षक एक ग्राफ है, न कि एक पेड़
- 2. पाठ, जिसका विषय निर्धारित किया गया है, एक साथ कई श्रेणियों को सौंपा जा सकता है
- 3. शीर्ष के साथ प्रत्येक सहसंबंध के लिए, शीर्ष निर्धारण के लिए सटीकता गुणांक इंगित किया गया है
- 4. पाठ का विषय प्रत्येक पाठ के लिए अलग-अलग निर्धारित किया गया है, और यह इस बात पर निर्भर नहीं करता है कि अन्य ग्रंथों के शीर्षक पहले कैसे निर्धारित किए गए थे
अंतिम बिंदु को थोड़ा स्पष्टीकरण की आवश्यकता है। पाठ के विषय की परिभाषा की स्वतंत्रता बहुत अच्छी है जब परिणामों की बाद की छंटाई की आवश्यकता नहीं होती है। जब ग्रंथों को केवल वर्गीकृत किया जाता है या नहीं। लेकिन यदि शीर्षासन में कई पाठ हैं, तो संभवतः शीर्षक में सर्वश्रेष्ठ फिट की कसौटी पर उन्हें छाँटने की आवश्यकता होगी। यह लेख स्पष्टता के लिए छोड़ा गया है।
पाठ के विषय को निर्धारित करने के लिए एल्गोरिदम, संक्षेप में
हम रूब्रिकेटर का वर्णन करते हैं। हम अध्ययन के तहत पाठ से शीर्षक में वर्णित कीवर्ड निकालते हैं। निष्कर्षण के परिणामस्वरूप, हमें एक टूटे हुए और सबसे अधिक बार असंगत ग्राफ के टुकड़े मिलते हैं। हम "सब कुछ" के शीर्ष पर ग्राफ के निकाले गए टुकड़ों तक पहुंचने के लिए लहर (या किसी अन्य, यदि वांछित हो) का उपयोग करते हैं। हम परिणामों का विश्लेषण और प्रदर्शन करते हैं।
पाठ के विषय को निर्धारित करने के लिए एल्गोरिदम, विस्तार से
रूब्रिकेटर के निर्माण का वर्णन पिछले लेखों में विस्तार से किया गया था। इस स्तर पर, हम मानते हैं कि हमारे पास एक खींचा हुआ स्तंभ शीर्षक है, जिसके पत्तों में कीवर्ड हैं, और नोडल शीर्षक में।
हम अध्ययन के तहत पाठ में शीर्षक के कीवर्ड के पूरे सेट की खोज करते हैं। चूँकि ऐसे कई शब्द हो सकते हैं जिन्हें ढूंढने की आवश्यकता है, मैं सुझाव देता हूं कि आप एक विशिष्ट कार्यान्वयन के लिए पाठ में स्ट्रिंग के सरणियों की त्वरित खोज के लिए एल्गोरिदम का उल्लेख करें। शुरुआत के लिए, मैं उनमें से सबसे लोकप्रिय लिंक प्रदान करूंगा:
अहो अल्गोरिदम - कोरसिक
एल्गोरिथ्म में एक पेड़ बनाने और "रिटर्न" को संसाधित करने के बजाय जटिल तर्क की विशेषता है, कार्यान्वयन के कई उदाहरण हैं। एक हब्र पर इस एल्गोरिथम का अच्छा वर्णन था ।
राबिन-कार्प एल्गोरिथ्म। एल्गोरिथ्म की एक विशिष्ट विशेषता शब्दों के बहुत बड़े सेट के साथ प्रभावी काम है।
सिद्धांत रूप में, ऊपर प्रस्तावित दो एल्गोरिदम के विवरणों को पढ़ने के बाद, उनके आधार पर उनके स्वयं के कार्यान्वयन के साथ आना मुश्किल नहीं है, कुछ अतिरिक्त स्थितियों को ध्यान में रखने में सक्षम है। उदाहरण के लिए, किसी पाठ की केस सेंसिटिविटी की आवश्यकता, आकृति विज्ञान का विचार आदि।
हेडिंग डिस्क्रिप्शन में उपयोग किए जाने वाले कीवर्ड को अध्ययन किए जा रहे टेक्स्ट से निकाला जाता है, आप सीधे टेक्स्ट के विषय को निर्धारित करने के लिए आगे बढ़ सकते हैं।
लहर
शीर्षक में एक शीर्ष है "सब कुछ।" पाठ में पाए जाने वाले कीवर्ड भी मौजूद हैं। इस चरण का लक्ष्य "सभी" शीर्ष के लिए प्रत्येक पाए गए कीवर्ड से रास्ता खोजना है।
"सैंड" कीवर्ड के लिए, हेडिंग के हेडिंग का रास्ता इस तरह दिखेगा:
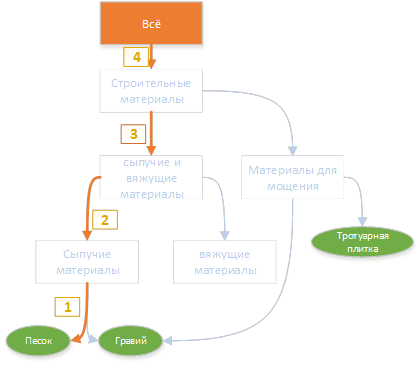
इसी प्रकार, शिखर के मार्ग पिछले चरण में पाए गए सभी शब्दों के अनुसार निर्मित होते हैं।
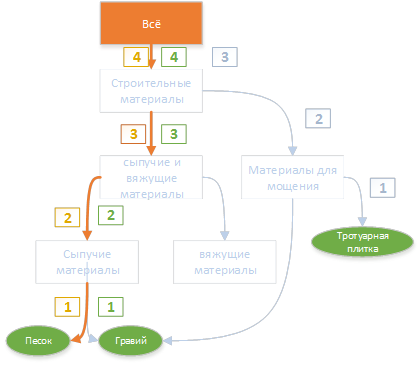
इस तरह के निर्माण के परिणामस्वरूप, प्रत्येक कीवर्ड के लिए शीर्ष पर एक पथ पाया जाता है।
विषयों की पहचान
आइए अब विचार करें कि लेख के उदाहरण का उपयोग करके शीर्षक का स्वचालित निर्धारण कैसे किया गया था: " स्लेबिंग स्लैब कैसे बिछाएं?" "। एक व्यक्ति, यहां तक कि लेख को पढ़े बिना, यह सुझाव दे सकता है कि हम टाइल बिछाने और संबंधित सामग्रियों और प्रौद्योगिकियों के संभावित तरीकों के बारे में बात करेंगे।
हम यह जांचेंगे कि इस लेख के लिए स्वचालित शीर्षक का पता कैसे चलता है।
चलिए शुरू करते हैं, पारंपरिक रूप से, लेख में पाए जाने वाले खोजशब्दों और शीर्षक में प्रदर्शन के साथ।
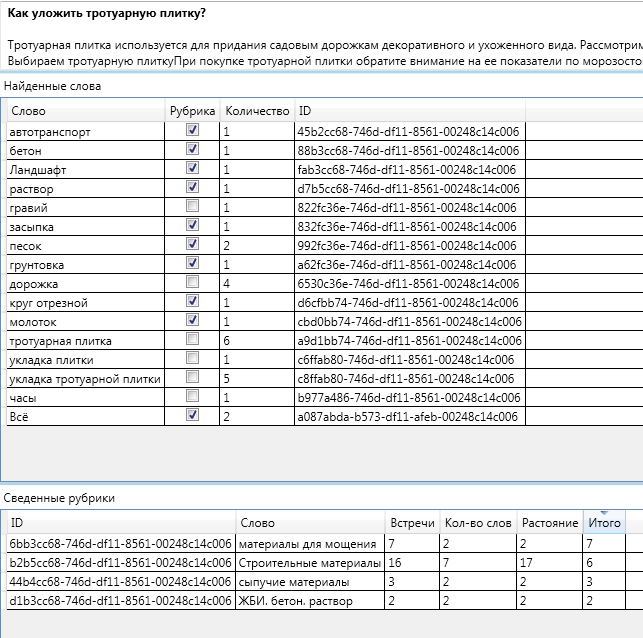
आकृति में, "शीर्षक" चिह्न का अर्थ है कि यह शीर्षक आइटम पत्तेदार नहीं है। यह आपको शीर्षक और उसके वर्णन करने वाले कीवर्ड के नाम को "संयोजित" करने की अनुमति देता है।
लेख में सबसे लोकप्रिय शब्द " कैसे फ़र्श स्लैब रखना है?" "फ़र्श स्लैब" है, जिसकी उम्मीद की जानी है।
नीचे, शीर्षक का वह भाग जो उदाहरण में शामिल था:
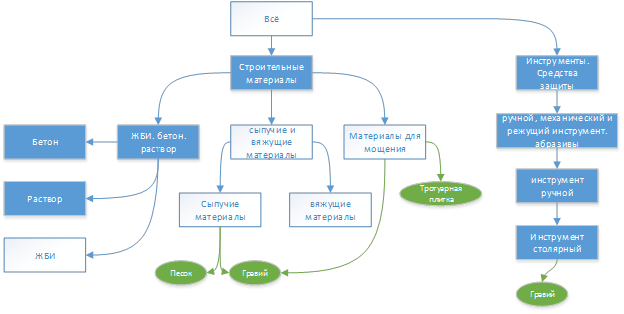
उदाहरण के लिए, यह दिखाया गया है कि कीवर्ड "बजरी" को दो खंडों में सौंपा गया है, और कीवर्ड "फ़र्शिंग स्लैब" केवल एक को सौंपा गया है। हेडिंग को प्रकाश पाठ में भी हाइलाइट किया जाता है, जिनके नाम टेक्स्ट में नहीं मिलते हैं। (याद रखें कि कीवर्ड और हेडिंग का एक ही नाम हो सकता है। पिछले लेखों में विवरण)।
अब आइए उन लेखों को देखें जिनमें लेख को सौंपा गया था:

पहला शीर्षक जिसके लिए यह लेख सौंपा गया है, शीर्षक है "पाविंग मटीरियल"।
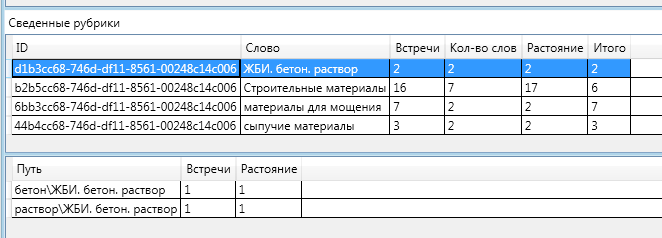
आकृति में - हाइलाइट की गई रेखा योग के साथ एक शीर्षक है और नीचे प्रत्येक शब्द के लिए डेटा के साथ एक प्लेट है।
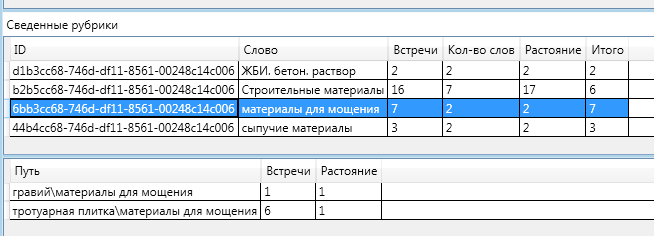
इस खंड में सदस्यता के लिए अंतिम रेटिंग 7. यह उच्चतम रेटिंग है। इस खंड से, पाठ में 2 शब्द हैं, 7 की कुल दूरी पर 7 बार। मुझे याद है कि एक ग्राफ के दो कोने के बीच की दूरी कम से कम पथ में किनारों की संख्या है।
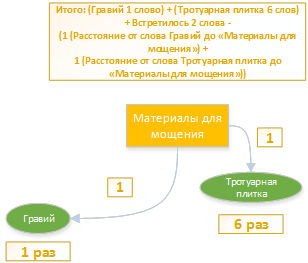
अर्थात्, पाठ कीवर्ड "बजरी" से मिला - एक बार। और कीवर्ड "फ़र्शिंग स्लैब" 6 बार। ये दोनों शब्द रूब्रिक "फ़र्शिंग सामग्री" से संबद्ध हैं।
कुल: (बजरी 1 शब्द) + (पाव स्लैब 6 शब्द) + मेट 2 शब्द - (1 (बजरी शब्द से "फ़र्श सामग्री") +
1 (फ़र्श शब्द से दूरी "फ़र्श सामग्री"))
पूर्णता के लिए, मैं शेष खंडों के लिए जानकारी का एक आरेख दूंगा:
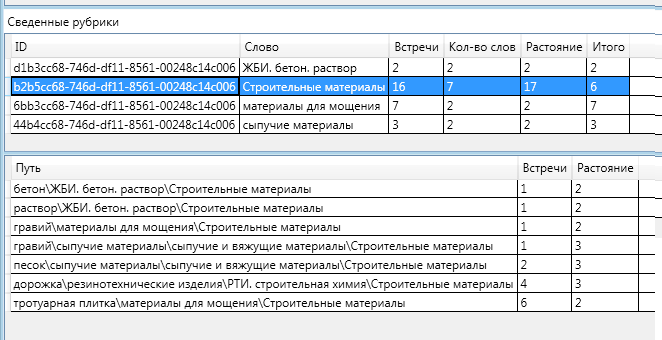
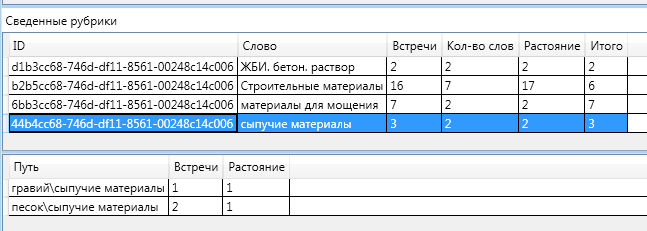
इस तथ्य पर ध्यान देना दिलचस्प है कि "बिल्डिंग मटेरियल" पर "रास्ते में" दो शीर्षक थे: "थोक सामग्री" और "थोक और सीमेंट सामग्री"। उनमें से एक अंतिम परिभाषा में गिर गया, और दूसरा नहीं हुआ।
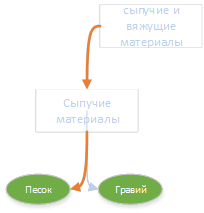
रेत और बजरी को एक साथ "बल्क सामग्री" शीर्षक के लिए जिम्मेदार ठहराया जा सकता है। "थोक सामग्री" को "बल्क और सीमेंटेड सामग्री" के लिए जिम्मेदार ठहराया जा सकता है। एक अधिक सामान्य (ऊपरी) शीर्ष की दूरी एक अधिक विशिष्ट (कम) की दूरी से अधिक है, फिर "कुल" की प्रासंगिकता की गणना करने के सूत्र द्वारा यह बहुत छोटा (नकारात्मक तक) हो जाता है।
सूत्र
तालिका में "कुल" कॉलम निर्धारित करने का सूत्र निम्नानुसार है:
कुल = "बैठक" + "शब्दों की संख्या" - "दूरी"
बैठकें - कई बार कीवर्ड पाए गए।
शब्द गणना - कितने अलग-अलग शब्द पाए गए।
दूरी - प्रत्येक शब्द से चयनित श्रेणी के लिए कुल दूरी।
और यह सूत्र एक मौलिक आसन से दूर है। और, सुनिश्चित करने के लिए, इसे बेहतर किया जा सकता है, अतिरिक्त तत्वों से लैस किया जा सकता है, आदि। (मैं टिप्पणियों में इस पर चर्चा करने का सुझाव देता हूं)।
आगे देखते हुए, मैं यह नोट करना चाहता हूं कि इस प्रणाली के विकास के दौरान हमने विशेष रूप से किसी भी स्पष्ट गुणांक से बचने की कोशिश की, ताकि ठीक ट्यूनिंग के ज्ञान में भ्रमित न हों।
वृद्धि अंक
इसके मूल में, रूब्रिकेटर तुरंत समान रूप से संकलित नहीं किया जा सकता है। निश्चित रूप से, इसका कुछ भाग दूसरों की तुलना में अधिक विस्तृत होगा। इससे ग्राफ का एक "तिरछा" और एक भाग में "शीर्ष पर पत्ते" से दूरी में वृद्धि हो सकती है और दूसरे में एक महत्वपूर्ण कमी हो सकती है। यह असंतुलन ग्राफ में दूरी की "सही" गणना पर प्रतिकूल प्रभाव डाल सकता है। यहां आप ग्राफ़ के प्रत्येक नोड में बच्चों की संख्या को ध्यान में रखने की कोशिश कर सकते हैं।

पाठ के विषय को निर्धारित करने की प्रक्रिया के अनुकूलन के लिए दूसरा दिलचस्प विचार परिणामों के बाद की रचना के साथ पाठ के विभिन्न वर्गों के लिए विषय के चयनात्मक निर्धारण का विचार है।
यह विचार इस तथ्य पर आधारित है कि, एक नियम के रूप में, किसी भी लेख की शुरुआत में विभिन्न कीवर्ड के साथ "परिचय" खंड होता है, निम्नलिखित अनुभागों में लेख के विचार का परिशोधन होता है, जो हमें प्रत्येक व्यक्तिगत अध्याय को और मज़बूती से वर्गीकृत करने की अनुमति देता है।
दूसरे कैसे करते हैं
यह देखना दिलचस्प है कि अन्य ऑनलाइन विषय निर्धारण सेवाओं में एक ही उदाहरण कैसा दिखता है।
साइट http://www.linkfeedator.ru/index.php?task=tematika निम्नलिखित परिणाम देता है:

वेबसाइट: http://sm.ashmanov.com/demo/

निष्कर्ष
खोज इंजन, और ज्ञान प्रसंस्करण और निष्कर्षण प्रणालियों के लिए ग्रंथों के स्वचालित वर्गीकरण-शीर्षक का विषय बहुत प्रासंगिक है। मुझे उम्मीद है कि यह लेख न केवल उन लोगों के लिए उपयोगी होगा जो केवल स्वत: वर्गीकरण की प्रौद्योगिकियों का अध्ययन करना शुरू कर रहे हैं, बल्कि उन लोगों के लिए भी हैं जिन्होंने इस पर एक से अधिक कुत्ते खाए हैं।
धन्यवाद
मैं उन लोगों के प्रति आभार व्यक्त करता हूं, जिन्होंने पहले दो लेख पढ़े और प्रतिक्रिया साझा की, साथ ही अंड्रे बेन्कोव को व्यक्तिगत रूप से संख्याओं के साथ सुंदर तालिकाओं को प्राप्त करने में मदद के लिए।