 दोस्तों, यह मेरे लिए आपको बताने के लिए नहीं है, और आप स्वयं जानते हैं कि सर्वर / क्लाइंट-सर्वर अनुप्रयोगों के लिए बैकएंड कैसे करना है। हमारे आदर्श दुनिया में, यह सब वास्तुकला के डिजाइन से शुरू होता है, फिर हम साइट का चयन करते हैं, फिर हम मशीनों की आवश्यक संख्या का अनुमान लगाते हैं, दोनों आभासी और नहीं। फिर विकास / परीक्षण के लिए वास्तुकला को बढ़ाने की प्रक्रिया होती है। क्या सब कुछ तैयार है? ठीक है, चलो लिखने का कोड बनाते हैं, पहले कमिट करते हैं, रिपॉजिटरी से सर्वर पर कोड अपडेट करते हैं। कंसोल / ब्राउज़र को खोला और बंद किया। अब तक, सब कुछ सरल है, लेकिन आगे क्या है?
दोस्तों, यह मेरे लिए आपको बताने के लिए नहीं है, और आप स्वयं जानते हैं कि सर्वर / क्लाइंट-सर्वर अनुप्रयोगों के लिए बैकएंड कैसे करना है। हमारे आदर्श दुनिया में, यह सब वास्तुकला के डिजाइन से शुरू होता है, फिर हम साइट का चयन करते हैं, फिर हम मशीनों की आवश्यक संख्या का अनुमान लगाते हैं, दोनों आभासी और नहीं। फिर विकास / परीक्षण के लिए वास्तुकला को बढ़ाने की प्रक्रिया होती है। क्या सब कुछ तैयार है? ठीक है, चलो लिखने का कोड बनाते हैं, पहले कमिट करते हैं, रिपॉजिटरी से सर्वर पर कोड अपडेट करते हैं। कंसोल / ब्राउज़र को खोला और बंद किया। अब तक, सब कुछ सरल है, लेकिन आगे क्या है?
समय के साथ, वास्तुकला अनिवार्य रूप से बढ़ती है, नई सेवाएं, नए सर्वर दिखाई देते हैं, और अब यह स्केलेबिलिटी के बारे में सोचने का समय है। सर्वर 1 से थोड़ा अधिक हैं; -, यह आवश्यक होगा कि किसी तरह लॉग को एक साथ इकट्ठा किया जाए। लॉग एग्रीगेटर के बारे में तुरंत एक विचार मेरे दिमाग में आया।
और जब कुछ होता है, भगवान मना करते हैं, गिर जाते हैं, निगरानी के विचार तुरंत आते हैं। परिचित, है ना? इसलिए मैंने अपने दोस्तों के साथ इसे खाया। और जब आप एक टीम में होते हैं, तो अन्य संबंधित समस्याएं दिखाई देती हैं।
आप तुरंत सोच सकते हैं कि हमने aws, jelastic, heroku, digitalocean, कठपुतली / चीफ, ट्रैविस, गिट-हुक, zabbix, datadog, loggly ... के बारे में कुछ नहीं सुना है ... मैं आपको विश्वास दिलाता हूं कि ऐसा नहीं है। हमने इनमें से प्रत्येक सिस्टम के साथ दोस्त बनाने की कोशिश की। अधिक सटीक रूप से, हम इनमें से प्रत्येक प्रणाली को अपने लिए स्थापित करते हैं। लेकिन उन्हें अपेक्षित प्रभाव नहीं मिला। कुछ नुकसान हमेशा दिखाई दिए और काम का हिस्सा वांछनीय होगा, कम से कम, स्वचालित करने के लिए।
ऐसी दुनिया में अधिक समय तक रहना, हमने सोचा, "ठीक है, हम डेवलपर्स हैं, चलो इसके साथ कुछ करते हैं।" परियोजना के निर्माण और विकास के हर चरण में हमारे साथ आने वाली समस्याओं का अनुमान लगाते हुए, हमने उन्हें एक अलग पृष्ठ पर लिखा और भविष्य की सेवा की विशेषताओं में बदल दिया।
और 2 महीने बाद इस से एक सेवा का जन्म हुआ - lastbackend.com :

डिज़ाइन
हमने सर्वर सिस्टम बनाते समय, पहली प्रॉब्लम से शुरू किया था, अर्थात् प्रोजेक्ट का एक दृश्य आरेख बनाना। मुझे आपके बारे में पता नहीं है, लेकिन मेरे लिए यह देखना आश्चर्यजनक है कि डेटा स्ट्रीम कैसे प्रवाहित होती है, सर्वर की सूची और विकी या Google डॉक में कॉन्फ़िगर किए गए वातावरण की तुलना में किस तत्व के साथ जुड़ा हुआ है। लेकिन आपको जज करने के लिए।
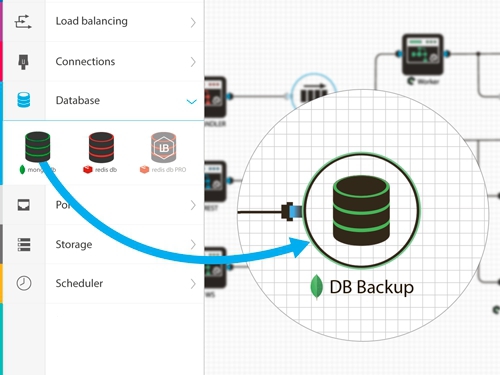
सर्किट को स्वयं डिजाइन करने की प्रक्रिया दर्दनाक रूप से सरल और सहज है: बाईं ओर बैकएंड तत्वों की एक सूची है, दाईं ओर एक कार्य क्षेत्र है। यहां हम सिर्फ और सिर्फ खींचते हैं। Mongodb से जुड़ने के लिए node.js तत्व को सक्षम करने की आवश्यकता है? कृपया - कनेक्शन बनाने के लिए माउस का उपयोग करें और उसका उपयोग करें।

समायोजन और स्केलिंग
सिस्टम में प्रत्येक तत्व अद्वितीय है, इसे कॉन्फ़िगर किया जाना चाहिए, और यदि आप इसके ऑटो-स्केलिंग को सक्षम करना चाहते हैं। यदि तत्व एक लोड बैलेंसर है, तो एक जगह है जहां अपस्ट्रीम चयन नियम इंगित किए गए हैं। यदि तत्व में स्रोत कोड है, तो हम इसके भंडार, पर्यावरण चर, निर्भरता को इंगित करते हैं। सिस्टम इसे डाउनलोड करेगा, इसे इंस्टॉल करेगा, और इसे लॉन्च करेगा।
और निश्चित रूप से, हमने ऑटो-परिनियोजन के बारे में भी सोचा था - एक निश्चित शाखा में स्रोत कोड - चालाक और जल्दी से तत्व को अपडेट किया। हमने सब कुछ सुविधाजनक बनाने की कोशिश की, क्योंकि हम खुद इसका उपयोग करते हैं और हम सभी कमियों को देखने वाले पहले व्यक्ति हैं।
परिनियोजित
और यहां सबसे दिलचस्प क्षण है। जब सर्किट तैयार और कॉन्फ़िगर किया जाता है, तो इसकी तैनाती में कई सेकंड लगते हैं। कभी-कभी यह लंबा होता है, और कभी-कभी तुरंत भी। यह सभी तत्वों के प्रकार और इसके स्रोत कोड पर निर्भर करता है। हम मुख्य रूप से नोड.जेएस पर कार्यक्रम करते हैं और हमारी योजनाओं को कुछ सेकंड में तैनात किया जाता है। सबसे रोमांचक क्षण यह देखना है कि आरेख में सभी कॉन्फ़िगर किए गए तत्व "जीवन में कैसे आते हैं" और संकेतक प्रकाश में आते हैं, तत्व की वर्तमान स्थिति का संकेत देते हैं।
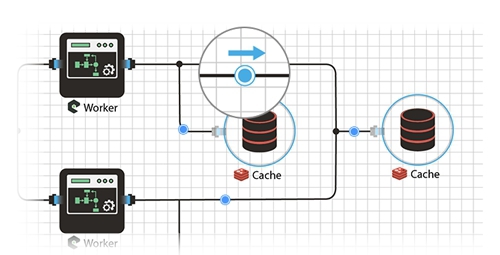
मैं यह जोड़ना भूल गया कि हमारे पास अलग-अलग होस्ट / डेटा सेंटर में प्रत्येक आइटम को चलाने की क्षमता है। उदाहरण के लिए, देशों के बीच यातायात को संतुलित करने के लिए, एक तत्व को एक देश में, दूसरे में एक डेटाबेस और एक डेटाबेस में लॉन्च किया जा सकता है, उदाहरण के लिए, केंद्र में कहीं रखा जाए। उदाहरण निश्चित रूप से बहुत अच्छा नहीं है, लेकिन सामान्य तौर पर, मुझे लगता है कि अवसर काफी उपयोगी है, खासकर यदि आप जानते हैं कि इसे कैसे और कहां लागू करना है।
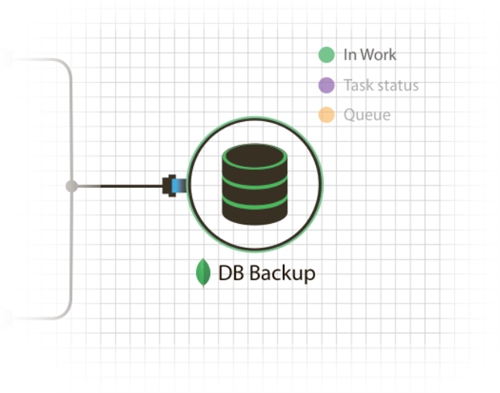
यहां, सिद्धांत रूप में, मुख्य भाग है, जो आपको जल्दी, खूबसूरती से और बिना किसी समस्या के एक परियोजना के सर्वर भाग को बढ़ाने की अनुमति देता है, लेकिन हमने तुरंत आगे की समस्याओं के बारे में याद किया, अर्थात्:
लॉग एग्रीगेशन
प्रत्येक तत्व लॉग को लॉग के एकल भंडार में एकत्रित करता है, जहां आप उन्हें देख और विश्लेषण कर सकते हैं, खोज और चयन कर सकते हैं। अब किसी भी छिपी हुई जानकारी की तलाश करने के लिए ssh और grep के माध्यम से कनेक्ट करने की आवश्यकता नहीं है, या केवल डेटा का विश्लेषण करें
निगरानी और चेतावनी प्रणाली
स्वाभाविक रूप से, हम और शिकार स्वयं मछली पकड़ने जाते हैं या बस यह जानकर आराम करते हैं कि अगर कुछ गलत होता है, तो आपको निश्चित रूप से इस बारे में सूचित किया जाएगा। इसलिए हम ऐसा करते हैं ताकि सभी विफलताओं के बारे में तुरंत जानकारी मिल जाए। अब मेरे सिर में चोट नहीं लगी है, कि आप कुछ महत्वपूर्ण याद कर सकते हैं।
सारांश
यहां, सिद्धांत रूप में, मुख्य समस्याएं जो हमने कोशिश की और हमारी सेवा के साथ हल करने की कोशिश कर रहे हैं और कम से कम किसी तरह भाई-डेवलपर के लिए जीवन को आसान बनाते हैं।
स्वाभाविक रूप से, मैंने सभी विशेषताओं को सूचीबद्ध करने का प्रबंधन नहीं किया, मैंने केवल मुख्य लोगों को उजागर करने की कोशिश की, लेकिन टिप्पणियों में मैं सभी सवालों और इच्छाओं का अधिक विस्तार से उत्तर दे सकता हूं।
आपका ध्यान देने के लिए धन्यवाद। मैं बहुत पहले आपकी राय पढ़ना चाहूंगा , आपके सवालों का जवाब दूंगा, अपनी सलाह और इच्छाएं लिखूंगा, साथ ही सभी को सेवा के बंद बीटा परीक्षण तक पहुंच प्रदान करूंगा, जो प्रारंभिक योजनाओं के अनुसार, मई की छुट्टियों पर शुरू होगा।
आपको यहाँ बीटा का निमंत्रण मिल सकता है। परीक्षण के शुरुआती दिन - एक पत्र एक्सेस डेटा के साथ आएगा।
पुनश्च
इसके अलावा, दोस्तों, अगर दिलचस्पी है, तो हम उपयोग की जाने वाली प्रौद्योगिकियों के ढेर पर तकनीकी लेखों की एक श्रृंखला शुरू कर सकते हैं, अर्थात् नोड। जेएस, मोंगोडब, रेडिस, सॉकेट्स, कोणीय, एसवीजी, आदि।