आइए देखें कि उपयोगकर्ता को डेटा का एक बड़ा ढेर दिखाने के लिए और क्या तरीके मौजूद हैं, और यह परिणामों को फ़िल्टर करने और खोज करने के साथ वांछनीय है, और यहां तक कि यह बहुत धीमा नहीं करता है :)।
आमतौर पर ब्रेक "दृश्य", लेकिन "मॉडल" नहीं
एक नियम के रूप में, यदि आप HTML तालिका के रूप में परिणाम प्रदर्शित करते हैं, तो हम प्रदर्शन प्रदर्शन में भाग लेते हैं - संपूर्ण परिणाम एक ही बार में प्रस्तुत किया जाता है। जैसा कि अभ्यास से पता चलता है, मोज़िला फ़ायरफ़ॉक्स और इंटरनेट एक्सप्लोरर में, एक बड़ी तालिका के प्रारंभिक प्रतिपादन पर खर्च किया गया समय बहुत बड़ा है, और मैं किसी तरह इस समस्या को हल करना चाहूंगा।
आमतौर पर इस समस्या को पृष्ठांकन के द्वारा बाईपास कर दिया जाता है और एक बार में तालिका का केवल एक छोटा सा हिस्सा प्रदान किया जाता है, लेकिन उपयोगकर्ता को पृष्ठों को मैन्युअल रूप से स्विच करना होगा, जो बहुत सुविधाजनक नहीं है। यदि आप पृष्ठांकन का उपयोग करते हैं, तो संभवतः डेटा सैंपलिंग की गति इसके प्रतिपादन की तुलना में बहुत तेज है, और इस तथ्य का उपयोग ग्रिड बनाने के लिए किया जाता है।
सबसे आम मामला एक निश्चित पंक्ति ऊंचाई है
यदि हमारे पास उन पंक्तियों की ऊँचाई है, जिन्हें हम दिखाना चाहते हैं, तो निश्चित है, तो कई तैयार समाधान हैं, उदाहरण के लिए SlickGrid , और वे सभी एक बहुत ही सरल विचार का उपयोग करते हैं, जिससे आप परिणामी तालिका की ऊंचाई अग्रिम में गणना कर सकते हैं और जब उपयोगकर्ता स्क्रॉल करता है तो पंक्तियों को आकर्षित कर सकता है। उपयुक्त क्षेत्र में।
इसी तरह के ग्रिड लगभग सभी जीयूआई पुस्तकालयों और रूपरेखाओं में मौजूद हैं, उदाहरण के लिए, कोको, डब्ल्यूपीएफ, स्विंग, आदि में। कुछ कार्यान्वयन में, स्क्रॉलिंग को केवल लाइन द्वारा लाइन की अनुमति दी जाती है (विंडोज के लिए अधिकांश समाधान), दूसरों में, आप लाइन के मध्य तक स्क्रॉल कर सकते हैं (कोको)
 |  |
जैसा कि हो सकता है, मौजूदा समाधान इस का एक बहुत अच्छा काम करते हैं।
एक कम विशिष्ट और अधिक जटिल मामला चर पंक्ति ऊंचाइयों है।
आइए अब एक और दिलचस्प विकल्प पर विचार करें - मान लें कि लाइनों की ऊंचाई परिवर्तनशील हो सकती है, और हम प्रत्येक पंक्ति की ऊंचाई का पता लगाने के बाद ही इसका पता लगा सकते हैं। कुछ मामलों में, ऊंचाई को बिना प्रतिपादन के भी हमें जाना जा सकता है, लेकिन किसी भी मामले में, यह तथ्य कि कोशिकाओं की ऊंचाई बदल सकती है, महत्वपूर्ण है। ताकि जीवन रास्पबेरी नहीं लगता है, हमने यह भी शर्त रखी है कि ऊँचाई को कैश करने से मना किया जाता है, क्योंकि हम तालिका में स्तंभों की चौड़ाई भी बदल सकते हैं, जो शब्द लपेट के साथ मिलकर चर ऊंचाई का मतलब है :)।
यहाँ 2 दृष्टिकोण हैं, जिनमें से एक का उपयोग नंबर में किया गया है। आई-कॉर्क से नंबर में, और दूसरा ओपनऑफिस.ऑल कैल्क और माइक्रोसॉफ्ट एक्सेल में। आइए दोनों को देखें और फायदे और नुकसान का विश्लेषण करें।
आसान तरीका है। पूर्ण तालिका प्रतिपादन
पूर्ण तालिका प्रतिपादन के साथ, हम 3 चीजें करते हैं:
1. हम पूरी तालिका प्रस्तुत करते हैं, इसकी ऊंचाई निर्धारित करते हैं और उपयोगकर्ता के लिए एक वास्तविक स्क्रॉल बनाते हैं
2. हर समय हम संपादित लाइन की ऊँचाई को पढ़ते हैं और स्क्रॉल की स्थिति को अपडेट करते हैं
3. यदि कॉलम (एस) की चौड़ाई बदल जाती है, तो सभी पंक्तियों की ऊंचाई को पुन: निर्धारित करें और स्क्रॉल की स्थिति को अपडेट करें
नंबर.app ने इस पथ को स्वयं के लिए चुना, और ब्राउज़र में सामान्य HTML तालिकाओं को प्रस्तुत करते समय उसी पथ का उपयोग किया जाता है (कुछ परिवर्धन के बाद से, ब्राउज़र भी तालिका को कंटेनर की चौड़ाई में फिट करने का प्रयास करते हैं)।
यह दृष्टिकोण क्यों बुरा है, मुझे लगता है कि आप एक ब्राउज़र में या Numbers.app में एक काफी बड़ी तालिका (10 कॉलम के साथ 10,000 रिकॉर्ड) खोलने की कोशिश करके आसानी से समझ सकते हैं। सब कुछ लोड होता है और बहुत धीरे-धीरे काम करता है और सामग्री के साथ काम करते समय एप्लिकेशन को लटका देता है, साथ ही साथ टेबल को लोड करते समय भी।
यह दृष्टिकोण अच्छा है कि सामग्री द्वारा स्क्रॉल करना बहुत तेज़ी से किया जा सकता है (चूंकि सभी सामग्री पहले ही प्रदान की जा चुकी है) और सुचारू रूप से, और उपयोगकर्ता को दिखाई जाने वाली स्क्रॉल ऊंचाई प्रदर्शित सामग्री की वास्तविक ऊंचाई से मेल खाती है।
जैसा कि आप अनुमान लगा सकते हैं, एक और तरीका है:
मुश्किल तरीका है। एक नकली स्क्रॉल के साथ दृश्य भाग का प्रतिपादन
विचार यह है कि, यदि तालिका में बहुत अधिक डेटा है, तो उपयोगकर्ता को इस तथ्य पर ध्यान देने की संभावना नहीं है कि स्क्रॉल ऊंचाई सभी कोशिकाओं की ऊंचाई के अनुरूप नहीं है। इसका क्या मतलब है, और हम इसका उपयोग कैसे कर सकते हैं? और यह बहुत आसान है:
हम स्क्रॉल की ऊँचाई का पता लगाने के लिए किसी भी चीज़ को प्रस्तुत नहीं करेंगे - हम इसकी गणना करेंगे, साथ ही एक निश्चित पंक्ति की ऊँचाई के मामले में, इस सरल सूत्र का उपयोग करके:
SCROLL_HEIGHT = N * ROW_HEIGHT
जहां SCROLL_HEIGHT स्क्रॉल की ऊंचाई है (यानी, "सामग्री" की ऊंचाई जिसे हम स्क्रॉल के साथ स्क्रॉल करते हैं), N लाइनों की संख्या है, ROW_HEIGHT एक लाइन की ऊंचाई है (उदाहरण के लिए 30px)
एक तार्किक सवाल उठता है - हम कैसे समझ सकते हैं कि हमें स्क्रॉल स्थिति (SCROLL_TOP) के दिए गए मूल्य पर क्या आकर्षित करना चाहिए, क्योंकि यह सामग्री की वास्तविक ऊंचाई के अनुरूप नहीं है? उत्तर उस सूत्र से मिलता है जिसका उपयोग हम ऊंचाई की गणना करने के लिए करते थे:
CURRENT_POSITION = [SCROLL_TOP / ROW_HEIGHT]
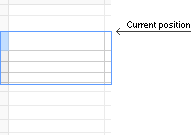 जहां [...] का अर्थ संख्या का पूर्णांक भाग है, CURRENT_POSITION वर्तमान में दिखाई देने वाली पहली पंक्ति का सूचकांक है, यदि अंकन खरोंच से है
जहां [...] का अर्थ संख्या का पूर्णांक भाग है, CURRENT_POSITION वर्तमान में दिखाई देने वाली पहली पंक्ति का सूचकांक है, यदि अंकन खरोंच से है
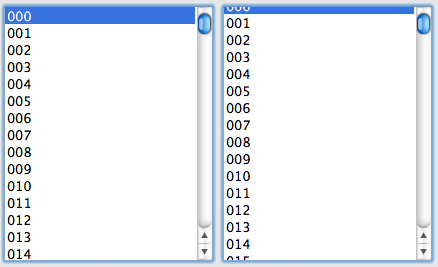
हमें इस नंबर के साथ क्या करना चाहिए :)? हमें CURRENT_POSITION से शुरू होने वाली सभी दृश्य रेखाएँ खींचनी होंगी। यही है, हम CURRENT_POSITION से शुरू करके और जब तक हम कोशिकाओं की सीमाओं से परे नहीं जाते हैं, तब तक सभी रेखाओं को मिलाकर रेखा खींचते हैं।
स्क्रॉल करने का यह तरीका लाइन-बाय-लाइन स्क्रॉलिंग से मेल खाता है, यानी हम लाइन के बीच में स्क्रॉल नहीं कर पाएंगे, क्योंकि हम हमेशा एक निश्चित लाइन से खींचते हैं, और बीच से नहीं। इसका मतलब यह होगा कि यदि रेखा की ऊंचाई उस क्षेत्र की ऊंचाई से अधिक है जिसमें हम आकर्षित करते हैं, तो हम बाकी सामग्री को देखने की क्षमता के बिना केवल रेखा का हिस्सा देखेंगे ! जब आप इस मामले में स्क्रॉल करने का प्रयास करते हैं, तो हम तुरंत अगली पंक्ति में पहुंच जाते हैं, और पिछली सेल पूरी तरह से दायरे से छिप जाती है। आप इस व्यवहार की जाँच कर सकते हैं, कहते हैं, Microsoft Excel में, यदि आप इसे नहीं मानते हैं :)।
उपयोगकर्ता द्वारा स्क्रॉल जारी करने के बाद, आप पहले सूत्र के अनुसार, इसे संरेखित कर सकते हैं:
SCROLL_TOP = CURRENT_POSITION * ROW_HEIGHT
वास्तव में, वर्तमान लाइन संख्या का निर्धारण अलग-अलग तरीकों से किया जा सकता है, यह सिर्फ उन तरीकों में से एक है जो स्क्रॉल के अनावश्यक "चिकोटी" के लिए नेतृत्व नहीं करता है।
Microsoft Excel और OpenOffice.org Calc में, सटीक समान रेंडरिंग तंत्र का उपयोग न केवल पंक्तियों के लिए किया जाता है, बल्कि कॉलम के लिए भी किया जाता है - इस मामले में, लाइन द्वारा लाइन का प्रतिपादन नहीं किया जाता है, लेकिन एक अधिक जटिल एल्गोरिथ्म के अनुसार, जिसके बारे में मैं विवरण में नहीं गया था
शुरुआती गाइड
मैंने अपने स्वयं के फ़ाइल प्रबंधक सहित कई परियोजनाओं में स्वयं इन रेंडरिंग तंत्रों का उपयोग किया, जिनकी साइट अब भुगतान न करने के लिए अक्षम है :)। किसी भी मामले में, यदि कोई उपरोक्त एल्गोरिदम को अपने दम पर लागू करना चाहता है, तो यहां अभ्यास से कुछ सुझाव दिए गए हैं:
1. वर्चुअल स्क्रॉल के साथ एक ग्रिड को खींचने का सबसे आसान तरीका है एक बिल्कुल तैनात <div> जो कि कुछ कंटेनर के ऊपर दिखाएगा जिसकी स्थिति jQuery का उपयोग करके आसानी से निर्धारित की जा सकती है () विधि
2. <div> का खुद को 2 बनाया जा सकता है - एक सामग्री के साथ, दूसरा विशेष रूप से स्क्रॉल के साथ, ताकि ब्राउज़र अपने आप सामग्री के साथ <div> को स्क्रॉल करने का प्रयास न करे, अन्यथा यह रिडर्व करते समय अप्रिय प्रभाव पैदा करेगा। आप स्थिति का उपयोग करके भी प्रयास कर सकते हैं: फिक्स्ड, लेकिन यह IE 7 में अजीब तरह से काम करता है
3. स्क्रॉल की स्थिति सबसे अच्छा है संरेखित न करें, क्योंकि ब्राउज़र स्क्रॉल पर विशेष नियंत्रण नहीं देते हैं
4. IE 7 में अधिकतम तत्व ऊंचाई लगभग 1 मिलियन पिक्सेल है, इसलिए यदि आप वर्चुअल लाइन ऊंचाई के लिए 30px लेते हैं, तो आपको लगभग 30,000 लाइनों की सीमा मिलती है। इससे निपटने के लिए, आप ब्राउज़र की संख्या में वृद्धि के साथ वर्चुअल रो की ऊंचाई कम कर सकते हैं, यदि ब्राउज़र IE है
5. माउस व्हील के साथ स्क्रॉल करने पर लाइनों को स्क्रॉल करने के लिए, आप गेको-आधारित ब्राउज़रों में DOMMouseScroll घटना को संभाल सकते हैं और बाकी सभी में माउसव्हील कर सकते हैं।
6. यदि आप एक पूरी तरह से दिखाई देने वाले क्षेत्र (यानी, उदाहरण के लिए, गतिशील रूप से हटाने और छोटी लाइनों की संख्या में स्क्रॉल करते समय नई लाइनें जोड़ते हैं) की तुलना में अधिक होशियार करते हैं, तो कृपया मुझे परिणामों के बारे में बताएं :)
ठीक है, यदि आप अभी भी अपने ग्रिड को लागू करते हैं, तो कोको में ग्रिड एपीआई के लिए प्रलेखन को देखें, कहते हैं - यह आपको बेहतर तरीके से समझने में मदद करेगा कि एक अच्छी तरह से मापनीय समाधान कैसे बनाया जाए।
मैं अपने फैसले पोस्ट नहीं करना चाहता, सब कुछ जल्दी और विशिष्ट कार्यों के लिए लिखा गया था, इसलिए यह संभावना नहीं है कि आप में से कोई भी फिट होगा। अंत तक पढ़ने के लिए धन्यवाद :))