In VC, it usually looks like this:
A typical comment looks like this:
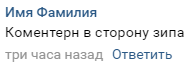
The structure is extremely simple. In the commentary there are names of the stop where the controllers were currently noticed, there is also the direction they are standing:
The comment, as a result, is an object with a stop, time and date, as well as a unique id by which we can identify it. With this, you can calculate the most likely location of where the controllers are now.
Training
First you need to determine the target public, from which we will parse the data. The group should have quite a lot of activity in the comments, otherwise we risk getting too little data
In my case, this is the “Control Gomel” group.
We will parse comments using the official VKontakte API for Python
We authenticate with the user's access key, as some groups may be closed, and access to their comments can only be obtained if you were accepted into the group.
After that, you can begin to extract comments:
Receive comments
To get started, we get the last available post in the group to pull out comments through vk.wall.getComments, and initialize the DataFrame, into which we will save the data.
Each commentary post has the inscription “Have a nice day, pay the fare and do not fall under control”, so download the comments, check the contents of the post and get an array of comments from which you can take data.
I took comments from posts over the past 3 months, given that 1 post is posted every day (now the end of November, the school year begins in September, and the supervisors most likely take this into account and change their ordinary places). In principle, other signs can be taken into account, such as, for example, the time of year.
Some comments are clogged with messages like “Is there anyone on Barykin?” If you look at such (unnecessary) comments, you can highlight some signs:
- The text contains the words “clean”, “left”, “nobody” and the like
- The words “tell me”, “who”, “what”, “how”
- Symbols, such as emoticons, for example
After that, we go through an array of comments and pull out a unique id, text, time, date and day of the week from them, which we put in the already created DataFrame.
Receive comments
import re import time import pandas as pd import lp import vk_api import check_correctness def auth(): vk_session = vk_api.VkApi(lp.login, lp.password) vk_session.auth() vk = vk_session.get_api() return vk def getDataFromComments(vk, groupID): # posts = vk.wall.get(owner_id=groupID, offset=1, count=90) print("\n") data = pd.DataFrame(columns=['text', 'post_id', "date", "day_in_week", "hour","minute", "day_in_month"]) for post in posts.get("items"): # id postID = post.get("id") if " , " not in post.get("text"): continue # commentary comments = vk.wall.getComments(owner_id=groupID, post_id=postID, count=200) # dataframe for comment in comments.get("items"): text = comment.get("text") text = re.sub(r"A-Za-z--0123456789 ", "", str(text)) commentaryIsNice = check_correctness.detection(text) if commentaryIsNice: print(text) date = comment.get("date") time_struct = time.gmtime(date) post_id = comment.get("post_id") data = data.append({"text": text, "post_id" : post_id, "date": date,"day_in_week" : time_struct.tm_wday, "hour": (time_struct.tm_hour+3), "minute": time_struct.tm_min, "day_in_month": time_struct.tm_mday}, ignore_index=True) # print(data[:10]) # print(data.info()) print("dataset is ready") return data
Thus, we received a DataFrame with the text of comments, their id, day of the week, hour and minute in which the comment was written. We need only the day of the week, the hour of writing and the text. It looks something like this:
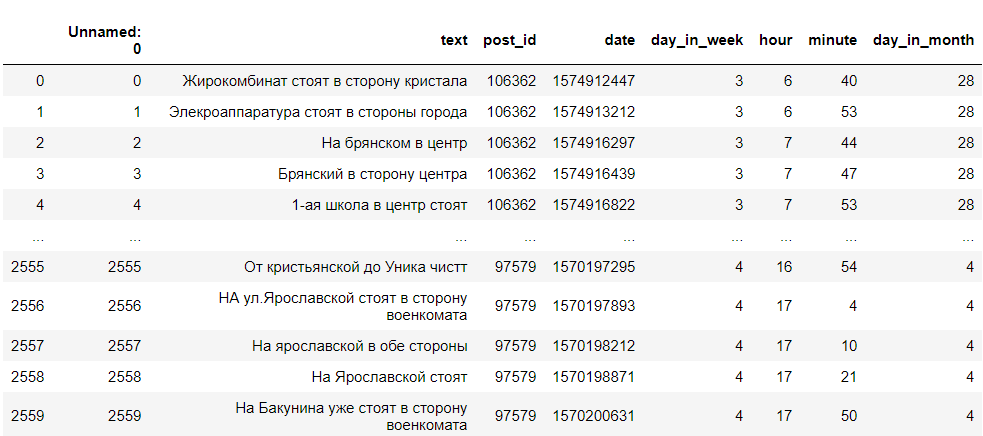
Data cleansing
Now we need to clear the data. It is necessary to remove the direction from the commentary in order to make less mistakes when searching for the Levenshtein distance. We find the expressions “to the side”, “go”, “how”, “near”, as they are usually followed by the name of the second stop, and delete them along with what comes after them, as well as replace some jargon names of the stops with the usual ones .
Clear data
from fuzzywuzzy import process def clear_commentary(text): """ - """ index = 0 splitted = text.split(" ") for i, s in enumerate(splitted): if len(splitted) == 1: return np.NaN if ((("" in s) or ("" in s) or ( "" in s) or ( "" in s)) and s is not ""): index = i if index is not 0 and index < len(splitted) - 2: for i in range(1, 4): splitted.remove(splitted[index]) string = " ".join(splitted) text = (string.lower()) elif index is not 0: splitted = splitted[:index] string = " ".join(splitted) text = string.lower() else: text = " ".join(splitted).lower() return text def clean_data(data): data.dropna(inplace=True) data["text"] = data["text"].map(lambda s: clear_commentary(s)) data.dropna(inplace=True) print("cleaned") return data
Converting using Levenshtein distance
We directly proceed to the Levenshane distance. A little help: Levenshtein distance - the minimum number of operations to insert one character, delete one character and replace one character with another, necessary to turn one line into another.
We will find it using the fuzzywuzzy library. It helps you quickly and easily calculate the Levenshtein distance. To speed up the work, the authors of the library also recommend installing the python-Levenshtein library.
In order to get stops from comments, we need a list of stops. It was kindly provided to me by the developer of the GoTrans application, Alexander Kozlov.
The list had to be expanded, adding there some stops that were not there, and changing part of the names so that they were better located.
Stops
stops = ['supermarket', 'meadow', 'remybtekhnika', 'Leningrad', 'Yaroslavl', 'Polesskaya',
'Yaroslavl', 'timofeenko', 'March 8',
'Rechitsky trading house', 'Rechitsky avenue', 'circus', 'department store', 'Chongarskaya',
'jongarka', 'ggu', 'skorina', 'university', 'appliance', '1000 little things', 'maya', 'station',
'graduate park', 'trade and economic', 'anniversary', 'microdistrict 18', 'airport', 'oncoming',
'Gomelgeodezcentr', 'crystal', 'Lake Lyubenskoye', 'Davydovsky market', 'Davydovka',
'river sozh', 'gomeldrev',
'Sevruki', 'gmu No. 1', 'etc. Rechitsky', 'costume', 'infectious diseases hospital', 'gull camp',
'volotova', 'coral', 'gomeltorgmash', 'gomelproekt', 'Vneshomelstroy', 'newspaper',
'Kalenikova', 'Eremino', 'distillery', 'special industrial automation', '2nd School', 'Barykina',
'machine units', 'youth', 'casting body', 'chemists', 'golovatsky', 'budenny',
'spu67', '35th', 'gagarin', '50 years to the gomselmash plant', 'hill', 'radio factory',
'grandmother', 'glassworks', 'chestnut', 'starting engines', 'astronauts',
'rtsrm initial', 'bykhovskaya', 'institute of the ministry of emergency situations', 'dk gomselmash', 'store', 'rechitsky',
'Sevruks', 'Osovtsy', 'tourist', 'meat factory', 'Holy Trinity', 'medical town', 'October',
'tank farm', 'gomeloblavtotrans', 'milkavita', 'bakunina', 'zip', 'ohma', 'resin',
'construction market ksk', 'road builder', 'field', 'kamenetskaya', 'bolshevik', 'jakubovka',
'Borodina', 'hippo hypermarket', 'underground heroes', 'May 9', 'chestnut', 'prosthetist',
'iput station', 'comintern', 'music pedagogical college', 'agricultural firm', 'bypass road', 'victory',
'western', 'pearl', 'Vladimir', 'dry', 'dispensary', 'Ivanova',
'machine-building', 'birches', '60 years', 'power engineer', 'centrolite',
'oncological clinic', 'shooting range', 'golovintsy', 'coral', 'southern', 'spring',
Efremova, Border, Belgut, Gomelstroy, Borisenko, Athletics Palace,
'Michurinsky', 'solar', 'gastello', 'military', 'auto center', 'plumbing', 'uza',
'medical college', 'kindergarten 11', 'Bolshevik', 'puppies', 'Davydovsky', 'ocean', 'progress',
'Dobrushskaya', 'white', 'GSK', 'davydovka', 'electrical equipment', 'friendship',
'70 years', 'car repair', 'swedish hill', 'race track', 'water canal', 'machine gomel',
Volotova, Pioneer, RCM, Khimtorg, 2nd Meadow Lane, Bochkina, Baths,
'oncology clinic', 'square', 'Lenin', '1st school', 'south store',
'gomelagrotrans', 'millers', 'lyubensky', 'military enlistment office', 'hospital', 'uza', 'rtsrm',
'lysyukovy', 'shop iput', 'raton', 'gas station', 'randovsky', 'farmhouse', 'chestnut', 'ropovsky',
'Romanovichi', 'Ilyich', 'rowing', 'construction enterprise', 'infectious',
'fat factory', 'car service', 'agroservice', 'sticky', 'Nikolskaya',
'self-propelled harvesters', 'masons', 'building materials', 'repair machinery', 'administration',
'October', 'forest fairy tale', 'Tatiana', 'Boris Tsarikov', 'Zharkovsky', 'Zaitseva',
'relocation', 'Karpovich', 'house-building plant', 'city electric transport', 'zlin',
'stadium gomselmash', 'ap 6', 'hydraulic drive', 'locomotive depot', 'car market osovtsy',
'new life', 'Zhukova', 'military unit', '3rd school', 'forest', 'red lighthouse',
'regional', 'Davydovskaya', 'Karbysheva', 'satellite of the world', 'youth', 'stadium locomotive',
'solar', 'Ladaservice', 'μR 21', 'Aresa', 'internationalists', 'Kosareva',
'Bogdanova', 'Gomel iron-concrete', 'μR 20a', 'μR Rechitsky', 'medical equipment', 'Juraeva',
'college of art crafts', 'ice', 'dk festival', 'shopping center',
'Kuibyshevsky', 'festival', 'garage coop 27', 'seismic engineering', 'milcha', '' hospital ',
'ptu179', 'chemical products', 'fire department', 'hospital', 'bus depot',
'newspaper complex', 'victory', 'Klenkovsky', 'diamond', 'engine repair', 'μR 19']
'Yaroslavl', 'timofeenko', 'March 8',
'Rechitsky trading house', 'Rechitsky avenue', 'circus', 'department store', 'Chongarskaya',
'jongarka', 'ggu', 'skorina', 'university', 'appliance', '1000 little things', 'maya', 'station',
'graduate park', 'trade and economic', 'anniversary', 'microdistrict 18', 'airport', 'oncoming',
'Gomelgeodezcentr', 'crystal', 'Lake Lyubenskoye', 'Davydovsky market', 'Davydovka',
'river sozh', 'gomeldrev',
'Sevruki', 'gmu No. 1', 'etc. Rechitsky', 'costume', 'infectious diseases hospital', 'gull camp',
'volotova', 'coral', 'gomeltorgmash', 'gomelproekt', 'Vneshomelstroy', 'newspaper',
'Kalenikova', 'Eremino', 'distillery', 'special industrial automation', '2nd School', 'Barykina',
'machine units', 'youth', 'casting body', 'chemists', 'golovatsky', 'budenny',
'spu67', '35th', 'gagarin', '50 years to the gomselmash plant', 'hill', 'radio factory',
'grandmother', 'glassworks', 'chestnut', 'starting engines', 'astronauts',
'rtsrm initial', 'bykhovskaya', 'institute of the ministry of emergency situations', 'dk gomselmash', 'store', 'rechitsky',
'Sevruks', 'Osovtsy', 'tourist', 'meat factory', 'Holy Trinity', 'medical town', 'October',
'tank farm', 'gomeloblavtotrans', 'milkavita', 'bakunina', 'zip', 'ohma', 'resin',
'construction market ksk', 'road builder', 'field', 'kamenetskaya', 'bolshevik', 'jakubovka',
'Borodina', 'hippo hypermarket', 'underground heroes', 'May 9', 'chestnut', 'prosthetist',
'iput station', 'comintern', 'music pedagogical college', 'agricultural firm', 'bypass road', 'victory',
'western', 'pearl', 'Vladimir', 'dry', 'dispensary', 'Ivanova',
'machine-building', 'birches', '60 years', 'power engineer', 'centrolite',
'oncological clinic', 'shooting range', 'golovintsy', 'coral', 'southern', 'spring',
Efremova, Border, Belgut, Gomelstroy, Borisenko, Athletics Palace,
'Michurinsky', 'solar', 'gastello', 'military', 'auto center', 'plumbing', 'uza',
'medical college', 'kindergarten 11', 'Bolshevik', 'puppies', 'Davydovsky', 'ocean', 'progress',
'Dobrushskaya', 'white', 'GSK', 'davydovka', 'electrical equipment', 'friendship',
'70 years', 'car repair', 'swedish hill', 'race track', 'water canal', 'machine gomel',
Volotova, Pioneer, RCM, Khimtorg, 2nd Meadow Lane, Bochkina, Baths,
'oncology clinic', 'square', 'Lenin', '1st school', 'south store',
'gomelagrotrans', 'millers', 'lyubensky', 'military enlistment office', 'hospital', 'uza', 'rtsrm',
'lysyukovy', 'shop iput', 'raton', 'gas station', 'randovsky', 'farmhouse', 'chestnut', 'ropovsky',
'Romanovichi', 'Ilyich', 'rowing', 'construction enterprise', 'infectious',
'fat factory', 'car service', 'agroservice', 'sticky', 'Nikolskaya',
'self-propelled harvesters', 'masons', 'building materials', 'repair machinery', 'administration',
'October', 'forest fairy tale', 'Tatiana', 'Boris Tsarikov', 'Zharkovsky', 'Zaitseva',
'relocation', 'Karpovich', 'house-building plant', 'city electric transport', 'zlin',
'stadium gomselmash', 'ap 6', 'hydraulic drive', 'locomotive depot', 'car market osovtsy',
'new life', 'Zhukova', 'military unit', '3rd school', 'forest', 'red lighthouse',
'regional', 'Davydovskaya', 'Karbysheva', 'satellite of the world', 'youth', 'stadium locomotive',
'solar', 'Ladaservice', 'μR 21', 'Aresa', 'internationalists', 'Kosareva',
'Bogdanova', 'Gomel iron-concrete', 'μR 20a', 'μR Rechitsky', 'medical equipment', 'Juraeva',
'college of art crafts', 'ice', 'dk festival', 'shopping center',
'Kuibyshevsky', 'festival', 'garage coop 27', 'seismic engineering', 'milcha', '' hospital ',
'ptu179', 'chemical products', 'fire department', 'hospital', 'bus depot',
'newspaper complex', 'victory', 'Klenkovsky', 'diamond', 'engine repair', 'μR 19']
Using .map and fuzzywuzzy.process.extractOne, we find the stop with the minimum Levenshtein distance in the list, after which we replace the comment text with the name of the stop, which allows us to get a dataset with the names of the stops.
The resulting dataset looks something like this:
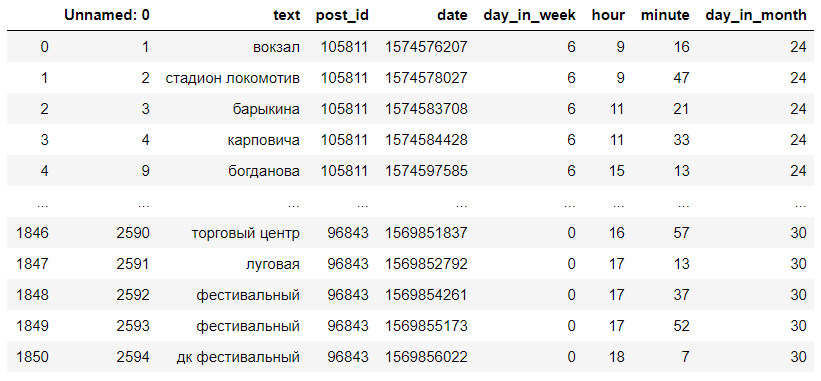
Comments transform into stops
def get_category_from_comment(text): """ """ dict = process.extractOne(text.lower(), stops) if dict[1] > 75: text = dict[0] else: text = np.nan print("wait") return text def get_category_dataset(data): """ """ print("remap started. wait") data.text = data.text.map(lambda comment: get_category_from_comment(str(comment))) print("remap ends") data.dropna(inplace=True) data["text"] = data.text.map(lambda s: "" if s=="" else s) data["text"] = data.text.map(lambda s: "" if s=="" else s) data["text"] = data.text.map(lambda s: " " if s=="" else s) data["text"] = data.text.map(lambda s: " " if s=="" else s) return data
Data output
Now we can guess where the controllers will most likely be at the given hour.
We are looking in the resulting data records for a specific hour and day of the week. For example, on Tuesday, 9 a.m.:
<code>data[(data["day_in_week"] == day) & (data["hour"] == hour)]</code>
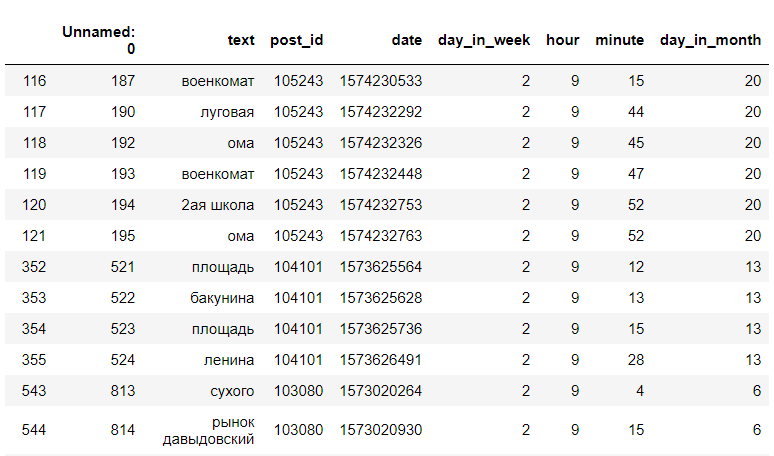
(this is not all data)
After that, we find the number of unique stops, and display only the stops, and their number:
df[(df["day_in_week"] == 2) & (df["hour"] == 9)]["text"].value_counts()

Now we can say that at 9 o’clock in the morning, on Tuesdays, the controllers will most likely be spotted at the stops Myasokombinat, ul. Lugovaya, BelGUT, TD “Oma”.
The main flaw in this method is the lack of data. Not for all days and hours there are entries in the comments given during rush hour, when people use public transport more than the data in less popular hours, but if you add data, for example, not only from the comments of one group, but also from alternative groups, or telegram chats, with the number of entries everything will become easier.
Bot with VK LongPoll API
To give the opportunity to receive data on the location of the controllers, depending on the time, and without being tied to a computer, I made a bot for a group on VKontakte that responds to any message by sending the number of stops in the records, given the current hour and day of the week.
Bot code
from random import randint import vk_api from requests import * from get_stops_from_data import get_stops_by_time def start_bot(data, token): vk_session = vk_api.VkApi(token=token) vk = vk_session.get_api() print("bot started") longPoll = vk.groups.getLongPollServer(group_id=183524419) server, key, ts = longPoll['server'], longPoll['key'], longPoll['ts'] while True: # : ts longPoll = post('%s' % server, data={'act': 'a_check', 'key': key, 'ts': ts, 'wait': 25}).json() if longPoll['updates'] and len(longPoll['updates']) != 0: for update in longPoll['updates']: if update['type'] == 'message_new': # vk.messages.markAsRead(peer_id=update['object']['user_id']) user = update['object']["user_id"] text = get_stops_by_time(data) if text is None or text == {}: message = "íåò çàïèñåé" vk.messages.send(user_id=user, random_id=randint(-2147483648, 2147483647), message=message) print(message) ts = longPoll['ts'] continue message = " - \n" \ "\n \n" for i in text.items(): message += i[0] + " " message += str(i[1]) message += "\n" # vk.messages.send(user_id=user, random_id=randint(-2147483648, 2147483647), message=message) ts = longPoll['ts']
Conclusion
The quality of such hypotheses has been tested by me more than once in practice, and everything works fine. It turned out that the controllers, basically, are at the same stops, although absolutely correct forecasts cannot be given, and the probability of success is not 100%. The Levenshtein distance has dozens of different applications, from correcting errors in a word, to comparing genes, chromosomes and proteins, but it also has potential in such applied problems.
Have a nice day, and pay the fare.
All bot code and data manipulations are published here .