
Talk about Natural Language Processing
So, the analysis of texts in natural languages, or Natural Language Processing, is a wide plan of tasks that can be divided into 3 parts. Natural Language Understanding - understanding, Natural Language Generation - generation, all this relates to texts. And finally, spoken language - recognition and synthesis. In the article we will talk in detail about understanding the text. Natural Language Understanding is of independent value when we create a system that automatically analyzes textual content and extracts facts about organizations, products, and people we are interested in.
To understand the text, first of all, it is necessary to highlight the semantics: to determine what is written, the class of signatures, user intention, intonation, tonality and, finally, what the text is all about, what real world objects, people, organizations, places, data . The task of distinguishing objects is called the recognition of named entities (Natural Entity Recognition), determining what a person wants, a classification of user intentions, or Classification Intent. And finally, tone recognition is Sentiment Analysis. The tasks are fairly well-known; approaches to their solution have existed for a long time.
Recognized named entities. There is some text generated by the client from which Named Entities must be selected. First of all, these are the names of people, the names of organizations and geolocations. There are also social entities: more detailed addresses, telephones, geopolitical entities.
When we talk with a chat bot, it is important for him to know what we want from him. Understanding user intentions will help determine the place in the column of the dialogue and the most appropriate response of the chat bot. Intents (user intentions) can be expressed in different ways. Here are fragments of real chats with bot clients: “Simka, I say, block!” Or “Can I disconnect the number for a while?” It would seem that the classification of intentions can be done by keywords. But, as you can see, even these two simple examples related to the same intent - blocking a SIM card - do not contain intersecting words at all. Therefore, it is best to create a machine-learning-based system that would classify texts itself, build and configure the chatbot for a new set of classes of intentions, depending on where this chatbot will be operated.
And finally, the classic task of analyzing tonality. In a certain sense, everything is simpler here than in the classification of intentions. If for each chatbot a set of intentions is different, depending on whether it communicates with telecommunication providers, ordering pizza or banking issues, then in the field of tonality analysis, the set of tonality classes is standard: 3 (neutral emotion) or 2 class (negative or positive ) However, the task of highlighting the tonality itself is more complex, because often people write sarcastically or implicitly express emotion.
For all these tasks, it is most effective to build a model that is trained with a teacher. Man is not a slave to his things. Accordingly, if we use a person for marking up a dataset, he can highlight which emotions are mentioned in the text, which classes include these or other user texts, and to which tonality are requests to the call center operator. After that, you can come up with a characteristic description and on its basis receive vector text or word text and further train the system. The theme is classic, proven. It works great, but it’s not without problems.
How to prepare data
For the preparation of various textual corpus there are many tools. In the image below, I gave a screenshot of one of the most popular tools — the brat an notation tool. We can load a set of texts into it, and the teachers themselves use the mouse to select words from the text: for example, the name of the organization of the named entity of class org, the named entity of class money. The interface is quite convenient, intuitive, however, to distinguish large volumes of texts here is very long and tiring.

What to do? Usually in real tasks when designing chat bots or when creating content analysis systems, it is not possible to use various large cases. The volume of corps is 100, 200, maybe 1000, 2000 texts, not more. But you need to learn. At the same time, the classical statement of the problem of teaching with a teacher involves a fairly large number of texts - tens of thousands. You can build a system with good training ability and solve problems, but here it is impossible to do. A modern approach to machine learning comes to the rescue, called Transfer Learning — training a large neural network.
Due to its multilayer structure, a neural network is both a classifier and an illustrator of features. The younger layers extract elementary features of the image: dashes, graphic primitives. And the closer to the exit from the neural network, the more high-level, abstract image elements are extracted. If we train the image recognition network with ImageNet (a site with more than 14 million different images on which you can build a very cool deep neural network), then we remove the last few layers, “cut off” her head and leave only the “body” - the initial layers, then the knowledge accumulated in the form of initial layers already allows obtaining elementary response images. And since any layer consists of elementary ones, we solve the problem of training a neural network not from scratch. We take the usual “body” for any task in the same field, for example, in computer vision, we sew on a new “head” and train its entire structure together.
The revolution of ELMo
However, the question arises: what about text analysis? After all, the texts are different for each language, and making such a giant labeled collection is problematic.
Starting in 2017, a kind of revolution began to occur in the field of computer linguistics and text analysis. Effective Transfer Learning methods have come here. Using two models: ELMo (Embeddings from Language Models) and BERT (Bidirectional Encoder Representations from Transformers) TransferLearning in the field of linguistics has reached a completely new level.
Whether it happened specifically or not is unknown, but these abbreviations are consonant with the names of the characters from the series Sesame Street. ELMo has historically become the first model. It allows you to take into account the deep semantics in the text. Recognition of named entities, classification of text, analysis of tonality — all these tasks are based on the semantics of the text and the extraction of meaning. Thus, we teach a deep neural network language modeling, the search for dependencies in texts.
For example, the picture below illustrates how we can solve the anaphora: “The programmer Vasya loves beer. Every evening after work, he goes to Jonathan and misses a glass or two. ” The programmer Vasya is a person who loves beer. Every evening after work, he goes to the Jonathan and misses a glass or two. Who is he? Is he this evening, is he a beer? Beer is it. Is he a programmer Vasya? Most likely, the programmer Vasya.
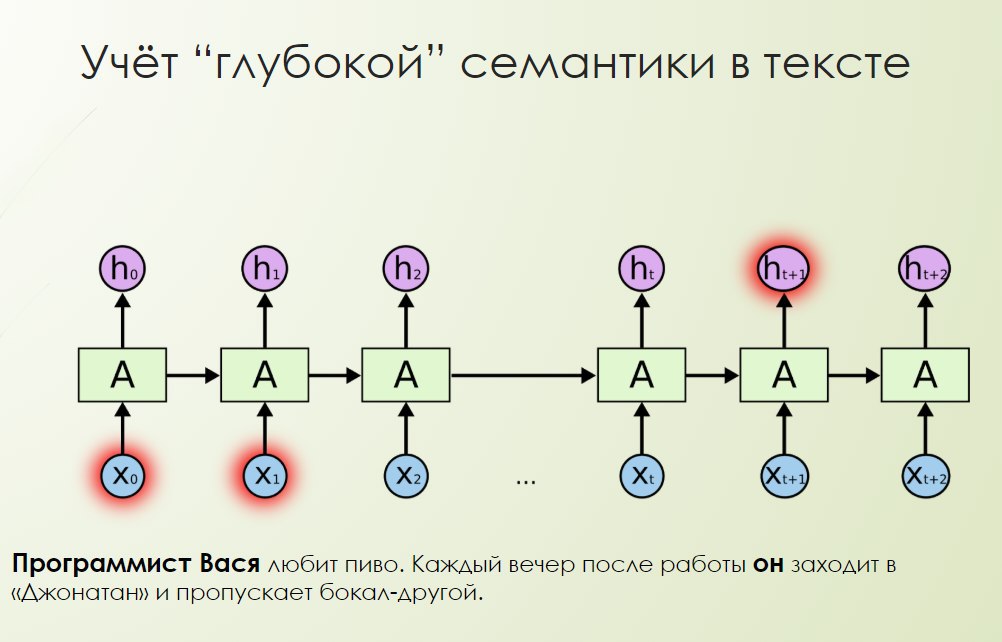
Thanks to feedback, recurrent neural networks have memory and can take into account the dependence as many times and in anything. Based on these patterns, it is possible to solve the problems of language modeling. No matter how long the text is, we are trying to get the neural network to predict the next word in, say, two, three, four words, in a whole paragraph. These types of language models are more effective.
It turns out that you do not need to make markup for each language for a long time — you can generate language models for any languages very easily using a computer. After training the model in operation mode, the text is input, and when processing each word in the text, the model tries to predict the next word. The latent states are taken at all levels of the neural network, the inverse of the recurrent neural network, and thus a vector representation of the word in the text is obtained. This is how ELMo works.
With forward language model and backward language model, a chain of words is supplied, the model is trained, and when it is necessary to get embedding (for example, the word stick in this text is “Let’s stick to”), the state of the recurrent neural network on the first word, on the second and at this moment of time is taken . The inverse model is on the first, on the second, and a large vector representation is obtained. The advantage of such models is that context will be taken into account when generating a vector representation of words: embedding is generated taking into account the environment of other words.
ELM takes into account deep semantics, solves the problem of homonymy, however this model is not without drawbacks. Recursive neural networks, on the one hand, can take into account light dependencies, and on the other, they learn very hard and cannot always analyze long sequences well, anyway, they have a problem with forgetting.
Bert
Let's say a decisive “no” to recurrent neural networks and use a different architecture — BERT. Instead of recurrent neural networks, we will use the Transformer model, based not on feedback, but on the so-called attention mechanism. When reading a text, keywords that carry the greatest semantic load are involuntarily highlighted.
You can localize some objects in the image or in the text. The attention mechanism is present in neural networks and is based on approximately the same principle. A particular layer weighs each element of the sequence, then each sequence at each moment in time. It turns out that you can see which elements of the sequence at this step are most or least important. Transformer uses a special version of attention - Multi-Head Attention. Moreover, Transformer entirely and completely does not use whole words, but quasimorphisms — BPE, because it turned out to be more efficient and convenient. What's the point? The most stable combinations of characters in the text are highlighted and words from characters are created. The problem of the dictionary is very acute for languages such as Russian, which have many word forms: "mother", "mother", "mother", "mother" - cases, diminutive forms, etc.
If you keep a dictionary of all word forms, it will result in several million, which, of course, is very inconvenient. As a result, a compromise solution was found. The most stable subwords in the word are distinguished statistically, the most frequency bigrams (repetition of characters) and are replaced by special characters BPE. The result is a BPE dictionary.
Consider the example of BPE — a text with a biography of Ivan Pavlov: “In the spring of 1890, Warsaw and Tomsk universities elect him as professor.” In general, words are “spring”, “1890”, “Warsaw”, but we highlight fragments of words - “In ## natural”; "In ## ar ## sha ## vsky" and so on. Thus, it is possible to effectively reduce the size of the dictionary to several tens of thousands of BPE, moreover, you can make systems that work with several languages at the same time. Looking ahead, I will say that one of the options was trained in 105 languages, and the BERT dictionary amounted to just over 100 thousand BPE.
What do we teach BERT?
Suppose there is some text: “Let's stick to improvisation in this skit.” It starts with a quasitoken, which means the beginning, and in each text 10-15% of the words are randomly replaced with mask - a special character. This is an input signal. That is, we are making BERT learn to recover missing words that are disguised as mask — what words should be in the text, in the sentence, in the paragraph in context.
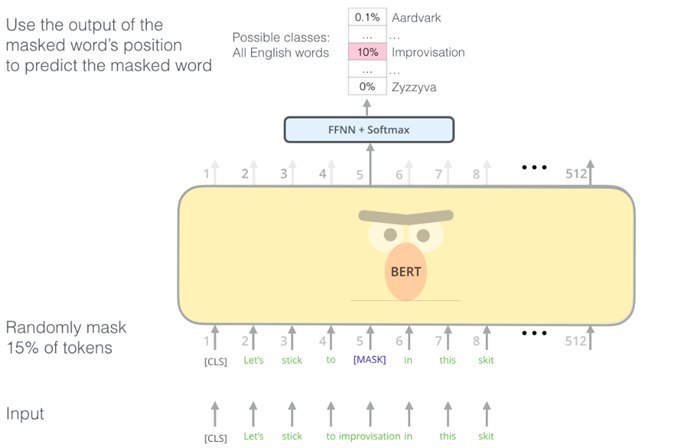
For this dataset, no markup is needed, the text itself is markup in this case, and BERT learns to model the semantics inside the text. The second task is to teach BERT to determine whether the second sentence is a logical development of the first, Multi-task learning. “Every evening Vasya goes to the bar. He loves beer very much, ”the second sentence is the logical development of the first. In this case, BERT should set the unit for this task: “Every evening Vasya goes to the bar. Squirrels change their fur in winter, ”- the second sentence is in no way connected, does not follow from the first, and BERT should show zero.
The first results in the case of both BERT and ELMo were obtained for the English language, and they were really impressive. However, what if we want to analyze the Russian language? The first option is Multilingual BERT, prepared by Google specialists, trained on Wikipedia texts. Wikipedia is not just an encyclopedia, but also a source of texts in many languages. The result is a Multilingual BERT with 110 million parameters. A more detailed description is here . A pre-trained model is on tfhub . It is very simple to use and generate features.
Multilingual BERT is good, but there are BERTs and localized ones. In particular, for the Russian language, you can take Multilingual BERT and adapt it specifically for Russian texts. IPavlov is currently undergoing such work, and the first results have already been obtained. BERT was adapted on news texts in Russian, and turned out to be more adapted for our language. It can be downloaded from the link within the framework of the iPavlov project and used to solve various problems.
Deep ner
After conducting a series of experiments, I decided to make an object that could not only be used for research purposes, but put into practice, solving specific problems of recognizing named entities. I created Deep NER - a deep neural network that is trained on the basis of transferlearning, you can specify an object of the ELMo or BERT class as the basis. Deep NER is a kind of repository with an extremely simple interface.
Finally about transfer learning
First of all, it is worth saying that the transfer of training allows you to effectively solve various problems, especially when there is no way to create large analytical centers. The second point: with fine and deep semantics in texts, complex models lead in comparison with simple ones with a wide margin. And finally, NER and the classification of texts for the Russian language can now be made simpler, because there are models and a well-developed database that can be used for your tasks and get effective, working, useful solutions.
Posted by Ivan Bondarenko , Leading Scientific Developer of the Laboratory of Business Solutions based on the NTI Competence Center for Artificial Intelligence MIPT.