It happens that you watch a movie, and in your head there is only one question - “Am I caught on clickbait again?” We will solve this problem and we will watch only suitable films. I suggest experimenting with the data a bit and writing a simple neural network to evaluate the film.
Our experiment is based on sentiment analysis technology to determine the audience’s mood for a product. As the data we take a dataset of user reviews on IMDb films. The Google Colab development environment will allow you to quickly train your neural network thanks to free access to the GPU (NVidia Tesla K80).
I use the Keras library, with the help of which I will build a universal model for solving similar machine learning problems. I will need the backend TensorFlow, the default version in Colab 1.15.0, so just upgrade to 2.0.0.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
Next, we import all the necessary modules for data preprocessing and model building. In previous articles, the emphasis is on libraries, you can look there.
%matplotlib inline import matplotlib import matplotlib.pyplot as plt
import numpy as np from keras.utils import to_categorical from keras import models from keras import layers from keras.datasets import imdb
Parsing IMDb Data
The IMDb dataset consists of 50,000 movie reviews from users marked positive (1) and negative (0).
- Reviews are pre-processed, and each of them is encoded by a sequence of word indices in the form of integers
- Words in reviews are indexed by their total frequency in the dataset. For example, the integer “2” encodes the second most frequently used word
- 50,000 reviews are divided into two sets: 25,000 for training and 25,000 for testing.
Download the dataset that is built into Keras. Since the data are divided into training and test in the proportion of 50-50, I will combine them, so that later I will divide by 80-20.
from keras.datasets import imdb (training_data, training_targets), (testing_data, testing_targets) = imdb.load_data(num_words=10000) data = np.concatenate((training_data, testing_data), axis=0) targets = np.concatenate((training_targets, testing_targets), axis=0)
Data exploration
Let's look at what we are working with.
print("Categories:", np.unique(targets)) print("Number of unique words:", len(np.unique(np.hstack(data))))

length = [len(i) for i in data] print("Average Review length:", np.mean(length)) print("Standard Deviation:", round(np.std(length)))

You can see that all the data fall into two categories: 0 or 1, which represents the mood of the review. The entire dataset contains 9998 unique words, the average review size is 234 words with a standard deviation of 173.
Let's look at the first review from this dataset, which is marked as positive.
print("Label:", targets[0]) print(data[0])

index = imdb.get_word_index() reverse_index = dict([(value, key) for (key, value) in index.items()]) decoded = " ".join( [reverse_index.get(i - 3, "#") for i in data[0]] ) print(decoded)

Data preparation
It's time to prepare the data. We need to vectorize each survey and fill it with zeros so that the vector contains exactly 10,000 numbers. This means that every review that is shorter than 10,000 words is filled with zeros. I do this because the largest overview is almost the same size, and each input element of our neural network should have the same size. You also need to convert the variables to a float type.
def vectorize(sequences, dimension = 10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1 return results data = vectorize(data) targets = np.array(targets).astype("float32")
Next, I divide the dataset into training and test data as agreed 4: 1.
test_x = data[:10000] test_y = targets[:10000] train_x = data[10000:] train_y = targets[10000:]
Create and train a model
The thing is small, it remains only to write a model and train it. Start by choosing a type. Two types of models are available in Keras: sequential and with a functional API. Then you need to add input, hidden and output layers.
To prevent retraining, we will use an “dropout” between them. On each layer, the “dense” function is used to completely connect the layers to each other. In hidden layers we will use the “relu” activation function, this almost always leads to satisfactory results. On the output layer, we use a sigmoid function that renormalizes the values in the range from 0 to 1.
I use the adam optimizer, it will change weights during the training process.
We use binary cross-entropy as a loss function, and accuracy as a measure metric.
Now you can train our model. We will do this with a batch size of 500 and only three epochs, since it was revealed that the model begins to retrain if it is trained longer.
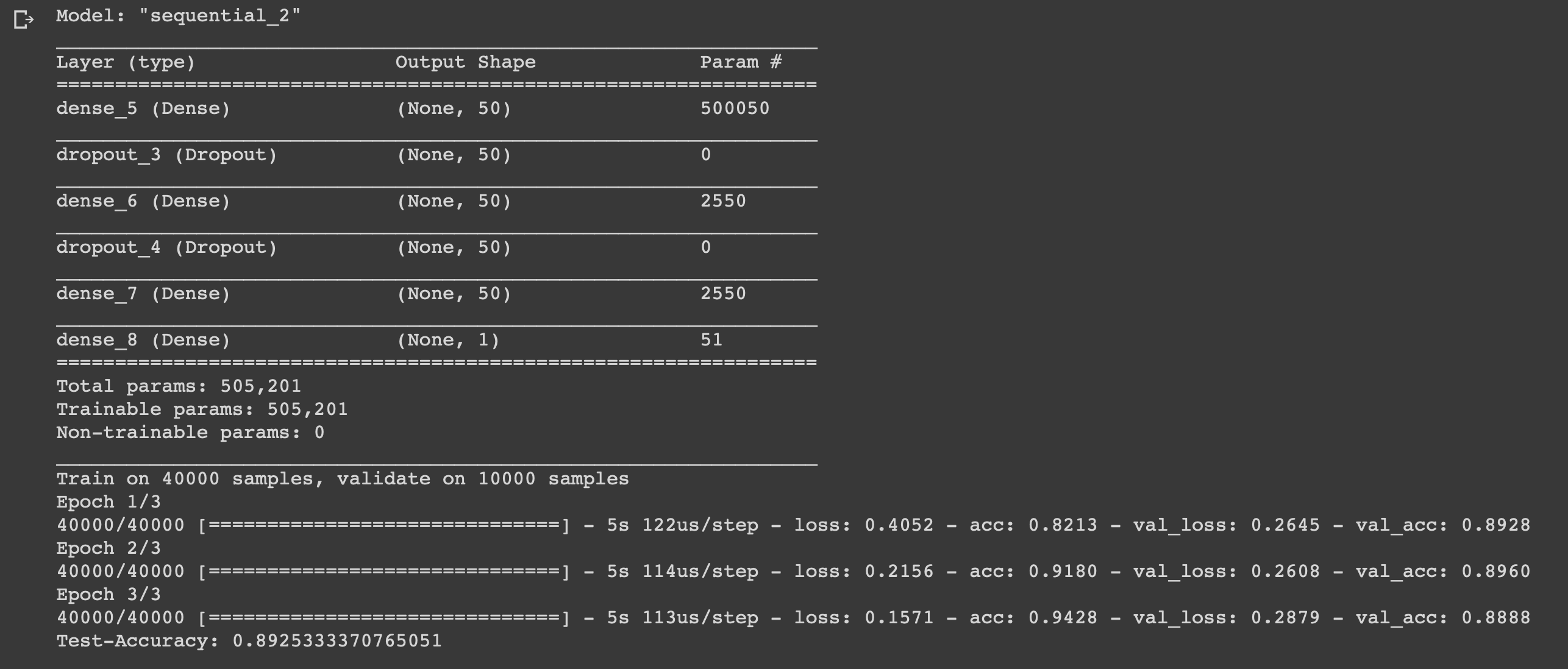
model = models.Sequential() # Input - Layer model.add(layers.Dense(50, activation = "relu", input_shape=(10000, ))) # Hidden - Layers model.add(layers.Dropout(0.3, noise_shape=None, seed=None)) model.add(layers.Dense(50, activation = "relu")) model.add(layers.Dropout(0.2, noise_shape=None, seed=None)) model.add(layers.Dense(50, activation = "relu")) # Output- Layer model.add(layers.Dense(1, activation = "sigmoid")) model.summary() # compiling the model model.compile( optimizer = "adam", loss = "binary_crossentropy", metrics = ["accuracy"] ) results = model.fit( train_x, train_y, epochs= 3, batch_size = 500, validation_data = (test_x, test_y) ) print("Test-Accuracy:", np.mean(results.history["val_acc"]))
Conclusion
We created a simple neural network with six layers, which can calculate the mood of filmmakers with an accuracy of 0.89. Of course, to watch cool films it’s not at all necessary to write a neural network, but this was just another example of how you can use the data and benefit from it, because you need it for that. The neural network is universal due to the simplicity of its structure, by changing some parameters you can adapt it for completely different tasks.
Feel free to write your ideas in the comments.