
Optical character recognition (OCR) technology has been developing in the world for decades. We at Yandex began to develop our own OCR technology to improve our services and give users more options. Pictures are a huge part of the Internet, and without the ability to understand them, searching on the Internet will be incomplete.
Image analysis solutions are becoming increasingly popular. This is due to the proliferation of artificial neural networks and devices with high-quality sensors. It is clear that in the first place we are talking about smartphones, but not only about them.
The complexity of tasks in the field of text recognition is constantly growing - it all started with the recognition of scanned documents. Then recognition of Born-Digital-images with text from the Internet was added. Then, with the growing popularity of mobile cameras, the recognition of good camera shots ( Focused scene text ). And the farther, the more complicated the parameters: the text can be fuzzy ( Incidental scene text ), written with any bend or in a spiral, of various categories - from photographs of receipts to store shelves and signboards.
Which way we went
Text recognition is a separate class of computer vision tasks. Like many computer vision algorithms, before the popularity of neural networks, it was largely based on manual features and heuristics. However, recently, with the transition to neural network approaches, the quality of technology has grown significantly. Look at the example in the photo. How this happened, I will tell further.
Compare today's recognition results with the results at the beginning of 2018:
 |  |
| 2018
Moisturizing n HO - micellar luxurious smoothness water. gentle multifunctional formula use as a means Sl FOR instead of a cleansing lotion or tonic No alcohol, colorants, parabens ... | 2019
MOISTURIZING THERMAL-MICELLAR WATER LUXURY SMOOTHness AUBY Soft and gentle multifunctional formula for daily use in as a means to make-up remover instead of cleansing lotion or tonic. No alcohol, colorants, parabens ... |
What difficulties did we encounter at first?
At the beginning of our journey, we made recognition technology for Russian and English, and the main use cases were photographed pages of text and pictures from the Internet. But in the course of the work, we realized that this is not enough: the text on the images was found in any language, on any surface, and the pictures sometimes turned out to be of very different quality. This means that recognition should work in any situation and on all types of incoming data.
And here we are faced with a number of difficulties. Here are just a few:
- Details For a person who is used to getting information from text, the text in the image is paragraphs, lines, words and letters, but for a neural network everything looks different. Due to the complex nature of the text, the network is forced to see both the picture as a whole (for example, if people joined hands and built an inscription), and the smallest details (in the Vietnamese language, similar symbols and ừ change the meaning of words). Separate challenges are recognizing arbitrary text and non-standard fonts.
- Multilingualism . The more languages we added, the more we came across their specifics: in Cyrillic and Latin words consist of separate letters, in Arabic they are written together, in Japanese there are no separate words. Some languages use spelling from left to right, some from right to left. Some words are written horizontally, some vertically. A universal tool should take into account all these features.
- The structure of the text . To recognize specific images, such as checks or complex documents, a structure that takes into account the layout of paragraphs, tables and other elements is crucial.
- Performance . The technology is used on a wide variety of devices, including offline, so we had to take into account the stringent performance requirements.
Detection Model Selection
The first step to recognizing the text is to determine its position (detection).
Text detection can be considered as an object recognition task, where individual characters , words or lines can act as an object.
It was important for us that the model subsequently scaled to other languages (now we support 45 languages).
Many research articles on text detection use models that predict the position of individual words . But in the case of a universal model, this approach has several limitations - for example, the concept of a word for the Chinese language is fundamentally different from the concept of a word, for example, in English. Individual words in Chinese are not separated by a space. In Thai, only single sentences are discarded with a space.
Here are examples of the same text in Russian, Chinese and Thai:
. .
今天天气很好 这是一个美丽的一天散步。
สภาพอากาศสมบูรณ์แบบในวันนี้ มันเป็นวันที่สวยงามสำหรับเดินเล่นกันหน่อยแล้ว
Lines , in turn, are very variable in aspect ratio. Because of this, the possibilities of such common detection models (for example, SSD or RCNN-based) for line prediction are limited, since these models are based on candidate regions / anchor boxes with many predefined aspect ratios. In addition, the lines can have an arbitrary shape, for example, curved, therefore for a qualitative description of the lines it is not enough exclusively to describe the quadrangle, even with a rotation angle.
Despite the fact that the positions of individual characters are local and described, their drawback is that a separate post-processing step is required - you need to select heuristics for gluing characters into words and lines.
Therefore, we took the SegLink model as the basis for detection, the main idea of which is to decompose lines / words into two more local entities: segments and relations between them.
Detector architecture
The architecture of the model is based on SSD, which predicts the position of objects on several scales of features. Only in addition to predicting the coordinates of individual “segments” are also predicted “connections” between neighboring segments, that is, whether two segments belong to the same line. “Connections” are predicted both for neighboring segments on the same scale of features, and for segments located in adjacent areas on adjacent scales (segments from different scales of features may vary slightly in size and belong to the same line).
For each scale, each feature cell is associated with a corresponding “segment”. For each segment s (x, y, l) at the point (x, y) on a scale l, the following is trained:
- p s whether the given segment is text;
- x s , y s , w s , h s , θ s - the offset of the base coordinates and the angle of inclination of the segment;
- 8 score for the presence of “connections” with segments adjacent to the l-th scale (L w s, s ' , s' from {s (x ', y', l) } / s (x, y, l) , where x –1 ≤ x '≤ x + 1, y – 1 ≤ y' ≤ y + 1);
- 4 score for the presence of “connections” with segments adjacent to the l-1 scale (L c s, s' , s' from {s (x ', y', l-1) }, where 2x ≤ x '≤ 2x + 1 , 2y ≤ y '≤ 2y + 1) (which is true due to the fact that the dimension of features on neighboring scales differs exactly 2 times).
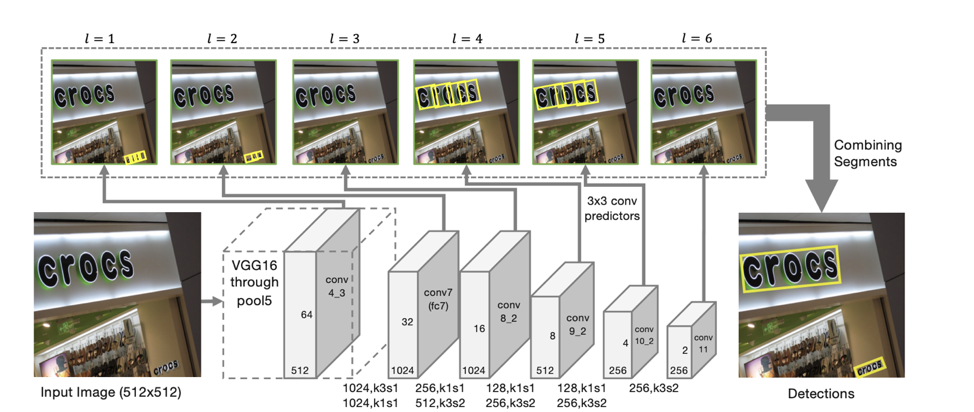
SegLink Detector Operational Illustration from Detecting Oriented Text in Natural Images by Linking Segments
According to such predictions, if we take as vertices all segments for which the probability that they are text is greater than threshold α, and as edges all bonds whose probability is greater than threshold β, then the segments form connected components, each of which describes a line of text .
The resulting model has a high generalizing ability : even trained in the first approaches on Russian and English data, it qualitatively found Chinese and Arabic text.
Ten scripts
If for detection we were able to create a model that works immediately for all languages, then for the recognition of lines found such a model is much more difficult to obtain. Therefore, we decided to use a separate model for each script (Cyrillic, Latin, Arabic, Hebrew, Greek, Armenian, Georgian, Korean, Thai). A separate general model is used for Chinese and Japanese due to the large intersection in hieroglyphs.
The model common to the entire script differs from the separate model for each language by less than 1 p.p. quality. At the same time, the creation and implementation of one model is simpler than, for example, 25 models (the number of Latin languages supported by our model). But due to the frequent presence of English in all languages, all our models are able to predict, in addition to the main script, Latin characters.
To understand which model should be used for recognition, we first determine whether the lines received belong to one of the 10 scripts available for recognition.
It should be noted separately that it is not always possible to uniquely determine its script along the line. For example, numbers or single Latin characters are contained in many scripts, so one of the output classes of the model is an "undefined" script.
Script definition
To define the script, we made a separate classifier. The task of defining a script is much simpler than the task of recognition, and the neural network is easily retrained on synthetic data. Therefore, in our experiments, a significant improvement in the quality of the model was given by pre-training on the string recognition problem . To do this, we first trained the network for the recognition problem for all available languages. After that, the resulting backbone was used to initialize the model to the script classification task.
While a script on an individual line is often quite noisy, the picture as a whole most often contains text in one language, either in addition to the main interspersed with English (or in the case of our Russian users). Therefore, to increase stability, we aggregate the predictions of lines from the image in order to obtain a more stable prediction of the image script. Lines with the predicted class of "indefinite" are not taken into account in aggregation.
Line recognition
The next step, when we have already determined the position of each line and its script, we need to recognize the sequence of characters from the given script that is shown on it, that is, from the sequence of pixels to predict the sequence of characters. After many experiments, we came to the following sequence2sequence attention based model:

Using CNN + BiLSTM in the encoder allows you to get signs that capture both local and global contexts. For text, this is important - often it is written in one font (distinguishing similar letters with font information is much easier). And in order to distinguish two letters written with a space from consecutive ones, we also need global statistics for the line.
An interesting observation : in the resulting model, the outputs of the attention mask for a particular symbol can be used to predict its position in the image.
This inspired us to try to clearly “focus” the model’s attention . Such ideas have been found in articles, for example, in the article Focusing Attention: Towards Accurate Text Recognition in Natural Images .
Since the attention mechanism gives a probability distribution over the feature space, if we take as an additional loss the sum of the attention outputs inside the mask corresponding to the letter predicted at this step, we get the part of the “attention” that focuses directly on it.
By introducing loss-log (∑ i, j∈M t α i, j ), where M t is the mask of the tth letter, α is the output of attention, we will encourage “attention” for focusing on a given character and thus help neural networks learn better.
For those training examples for which the location of individual characters is unknown or inaccurate (not all training data has markings at the level of individual characters, not words), this term was not taken into account in the final loss.
Another nice feature: this architecture allows you to predict the recognition of right-to-left lines without additional changes (which is important, for example, for languages such as Arabic, Hebrew). The model itself begins to issue recognition from right to left.
Fast and slow models
In the process, we encountered a problem: for “tall” fonts , that is, fonts elongated vertically, the model worked poorly. This was caused by the fact that the dimension of signs at the attention level is 8 times smaller than the dimension of the original image due to strides and pullings in the architecture of the convolutional part of the network. And the locations of several neighboring characters in the source image may correspond to the location of the same feature vector, which may lead to errors in such examples. The use of architecture with a smaller narrowing of the dimension of features led to an increase in quality, but also to an increase in processing time.
To solve this problem and avoid increasing the processing time , we made the following refinements to the model:
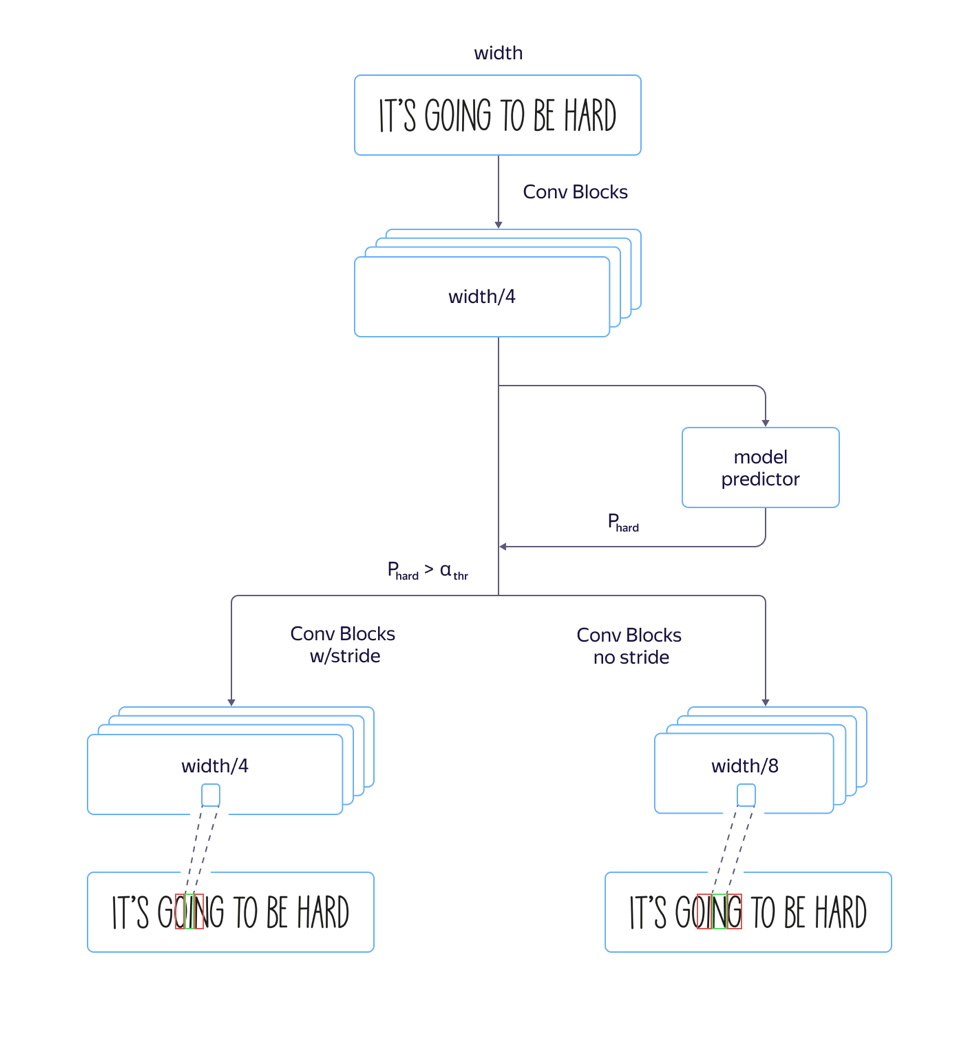
We trained both a fast model with a lot of strides and a slow one with less. On the layer where the model parameters began to differ, we added a separate network output that predicted which model would have less recognition error. The total loss of the model was composed of L small + L big + L quality . Thus, on the intermediate layer, the model learned to determine the “complexity” of this example. Further, at the application stage, the general part and the prediction of the “complexity” of the example were considered for all lines, and depending on its output, either the fast or the slow model was used in the future according to the threshold value. This allowed us to get a quality that is almost no different from the quality of a long model, while the speed increased by only 5% percent instead of the estimated 30%.
Training Data
An important stage in creating a high-quality model is the preparation of a large and varied training sample. The "synthetic" nature of the text makes it possible to generate large quantities of examples and get decent results on real data.
After the first approach to the generation of synthetic data, we carefully looked at the results of the obtained model and found that the model does not recognize single letters 'I' well due to the bias in the texts used to create the training set. Therefore, we clearly generated a set of “problematic” examples , and when we added it to the initial data of the model, the quality increased significantly. We repeated this process many times, adding more and more complex slices, on which we wanted to improve the quality of recognition.
The important point is that the generated data should be diverse and similar to real ones . And if you want the model to work on photographs of text on sheets of paper, and the entire synthetic dataset contains text written on top of landscapes, then this may not work.
Another important step is to use for training those examples on which the current recognition is mistaken. If there are a large number of pictures for which there is no markup, you can take those outputs of the current recognition system in which she is not sure, and mark only them, thereby reducing the cost of markup.
For complex examples, we asked users of the Yandex.Tolok service to photograph and send us images of a certain “complex” group for a fee, for example, photos of packages of goods:


Quality of work on "complex" data
We want to give our users the opportunity to work with photographs of any complexity, because it may be necessary to recognize or translate the text not only on the page of a book or a scanned document, but also on a street sign, advertisement or product packaging. Therefore, while maintaining the high quality of work on the flow of books and documents (we will devote a separate story to this topic), we pay special attention to “complex sets of images”.
In the way described above, we have compiled a set of images containing text in the wild that may be useful to our users: photographs of signboards, announcements, tablets, book covers, texts on household appliances, clothes, and objects. On this data set (the link to which is below), we evaluated the quality of our algorithm.
As a metric for comparison, we used the standard metric of accuracy and completeness of word recognition in the dataset, as well as the F-measure. A recognized word is considered correctly found if its coordinates correspond to the coordinates of the marked-up word (IoU> 0.3) and the recognition coincides with the marked out exactly to the case. Figures on the resulting dataset:
| Recognition system | Completeness | Accuracy | F-measure |
| Yandex Vision | 73.99 | 86.57 | 79.79 |
Dataset, metrics and scripts for reproducing the results are available here .
Upd. Friends, comparing our technology with a similar solution from Abbyy caused a lot of controversy. We respect the opinions of the community and industry peers. But at the same time we are confident in our results, so we decided this way: we will remove the results of other products from the comparison, discuss the testing methodology with them again and return to the results in which we come to a general agreement.
Next steps
At the junction of individual steps, such as detection and recognition, problems always arise: the slightest changes in the detection model entail the need to change the recognition model, so we are actively experimenting with creating an end-to-end solution.
In addition to the already described ways to improve the technology, we will develop a direction of analysis of the document structure, which is fundamentally important when extracting information and is in demand among users.
Conclusion
Users are already accustomed to convenient technologies and without hesitation turn on the camera, point at a store’s sign, a menu in a restaurant or a page in a book in a foreign language and quickly receive a translation. We recognize text in 45 languages with proven accuracy, and opportunities will only expand. The set of tools inside Yandex.Cloud enables anyone who wants to use the best practices that Yandex has been doing for themselves for a long time.
Today you can just take the finished technology, integrate it into your own application and use it in order to create new products and automate your own processes. The documentation for our OCR is available here .
What to read:
- D. Karatzas, SR Mestre, J. Mas, F. Nourbakhsh, and PP Roy, “ICDAR 2011 robust reading competition-challenge 1: reading text in born-digital images (web and email),” in Document Analysis and Recognition (ICDAR ), 2011 International Conference on. IEEE, 2011, pp. 1485-1490.
- Karatzas D. et al. ICDAR 2015 competition on robust reading // 2015 13th International Conference on Document Analysis and Recognition (ICDAR). - IEEE, 2015 .-- S. 1156-1160.
- Chee-Kheng Chng et. al. ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT) [ arxiv: 1909.07145v1 ]
- ICDAR 2019 Robust Reading Challenge on Scanned Receipts OCR and Information Extraction rrc.cvc.uab.es/?ch=13
- ShopSign: a Diverse Scene Text Dataset of Chinese Shop Signs in Street Views [ arxiv: 1903.10412 ]
- Baoguang Shi, Xiang Bai, Serge Belongie Detecting Oriented Text in Natural Images by Linking Segments [ arxiv: 1703.06520 ].
- Zhanzhan Cheng, Fan Bai, Yunlu Xu, Gang Zheng, Shiliang Pu, Shuigeng Zhou Focusing Attention: Towards Accurate Text Recognition in Natural Images [ arxiv: 1709.02054 ].