In order not to reason abstractly, we consider two specific implementations:
void vector8_inc(std::vector<uint8_t>& v) { for (size_t i = 0; i < v.size(); i++) { v[i]++; } } void vector32_inc(std::vector<uint32_t>& v) { for (size_t i = 0; i < v.size(); i++) { v[i]++; } }
Let's try to guess
This question is easy to answer using the benchmark, and a little later we will do it, but first we’ll try to guess (this is called “reasoning based on basic principles” - it sounds more like a scintilla).
Firstly, it’s worth asking a question: What is the size of these vectors ?
Well, let's pick some number. Let there be 20,000 elements in each.
Further, it is known that we will test on the Intel Skylake processor - we will see the characteristics of the addition commands for 8-bit and 32-bit operands with direct addressing. It turns out that the main indicators are the same: 1 operation per cycle and a delay of 4 cycles per memory access (1). In this case, the delay does not matter, since each addition operation is performed independently, so that the calculated speed is 1 element per cycle, provided that all the rest of the work on the loop will be performed in parallel.
You can also notice that 20,000 items correspond to a data set of 20 Kbytes for the version with uint8_t and as much as 80 Kbytes for the version with uint32_t . In the first case, they ideally fit in the L1 level cache of modern x86-based computers, and in the second - no. It turns out that the 8-bit version will get a head start due to efficient caching?
Finally, we note that our task is very similar to the classic case of automatic vectorization : in a loop with a known number of iterations, an arithmetic operation is performed on elements sequentially located in memory. In this case, the 8-bit version should have a tremendous advantage over the 32-bit version, since one vector operation will process four times as many elements and, in general, Intel processors perform vector operations on single-byte elements at the same speed as over 32- bit elements.
All right, stop talking. It's time to turn to the test.
Benchmark
I got the following timings for vectors of 20,000 elements on gcc 8 and clang 8 compilers with different optimization levels:
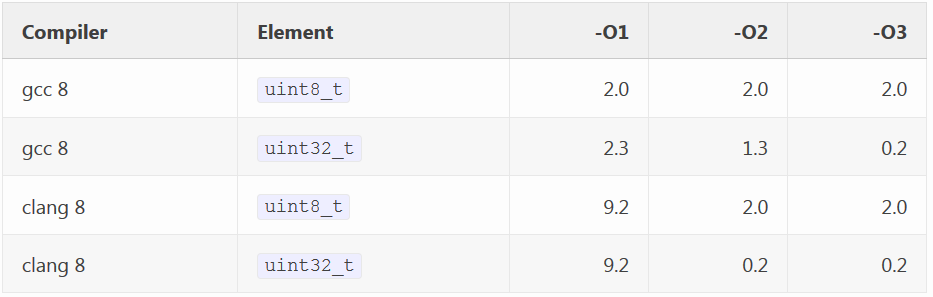
It turns out that, with the exception of the -O1 level, the version with uint32_t is faster than the version with uint8_t , and in some cases it is significant: 5.4 times on gcc at the level -O3 and exactly 8 times on clang on both levels, -O2 and - O3 . Yes, the increment of 32-bit integers in std :: vector is up to eight times faster than the increment of 8-bit integers on the popular compiler with standard optimization settings.
As usual, let us turn to the assembler listing in the hope that it will shed light on what is happening.
Here is a listing for gcc 8 at the -O2 level, where the 8-bit version is “only” 1.5 times slower than the 32-bit version (2):
8-bit:
.L3: inc BYTE PTR [rdx+rax] mov rdx, QWORD PTR [rdi] inc rax mov rcx, QWORD PTR [rdi+8] sub rcx, rdx cmp rax, rcx jb .L3
32-bit:
.L9: inc DWORD PTR [rax] add rax, 4 cmp rax, rdx jne .L9
The 32-bit version looks exactly as we expected from an undeployed (3) loop: an increment (4) with an address, then three loop control commands: add rax , 4 - an increment of the inductive variable (5) and a couple of cmp and jne commands to check the conditions for exit from the loop and conditional jump on it. Everything looks great - the deployment would compensate for the cost of incrementing the counter and checking the condition, and our code would almost reach the maximum possible speed of 1 element per clock cycle (6), but for an open-source application it will do. And what about the 8-bit version? In addition to the inc command with the address, two additional commands for reading from memory are executed, as well as the sub command, which is taken from nowhere.
Here is a listing with comments:
8-bit:
.L3: inc BYTE PTR [rdx+rax] ; v[i] mov rdx, QWORD PTR [rdi] ; v.begin inc rax ; i++ mov rcx, QWORD PTR [rdi+8] ; v.end sub rcx, rdx ; end - start (.. vector.size()) cmp rax, rcx ; i < size() jb .L3 ; . i < size()
Here vector :: begin and vector :: end are the internal std :: vector pointers that it uses to indicate the beginning and end of the sequence of elements contained within the area selected for it (7), these are essentially the same values which are used to implement vector :: begin () and vector :: end () (although they are of a different type). It turns out that all additional commands are just a consequence of the calculation of vector.size () . It seems nothing unusual? But after all, in the 32-bit version, of course, size () is also calculated, however, these commands were not in that listing. The calculation of size () happened only once - outside the loop.
So what's the deal? The short answer is pointer aliasing . I will give a detailed answer below.
Detailed response
Vector v is passed to the function by reference, which, in fact, is a masked pointer. The compiler must refer to the members v :: begin and v :: end of the vector to calculate its size size () , and in our example, size () is computed at each iteration. But the compiler is not obliged to blindly obey the source code: it may well carry the result of calling the size () function outside the loop, but only if it knows for sure that the semantics of the program will not change . From this point of view, the only problematic place in the loop is the increment v [i] ++ . Recording takes place at an unknown address. Can such an operation change the value of size ()?
If the record occurs in std :: vector <uint32_t> (i.e. by the uint32_t * pointer), then no, it cannot change the size () value. Writing to objects of type uint32_t can only modify objects of type uint32_t , and the pointers involved in calculating size () have a different type (8).
However, in the case of uint8_t , at least on popular compilers (9), the answer will be this: yes, theoretically the value of size () can change , since uint8_t is an alias for unsigned char , and arrays of the unsigned char (and char ) type can Alias with any other type . This means that, according to the compiler, writing to uint8_t pointers can modify the contents of memory of unknown origin at any address (10). Therefore, it assumes that each increment operation v [i] ++ can change the value of size () , and therefore is forced to re-calculate it at each iteration of the loop.
We all know that writing to the memory pointed to by std :: vector will never change its own size () , because this would mean that the vector itself was somehow allocated inside its own heap, and that’s practically impossible and akin to the problem of chicken and eggs (11). But unfortunately this is not known to the compiler!
What about the rest of the results?
Well, we found out why the version with uint8_ is slightly slower than the version of uint32_t on gcc at the -O2 level. But why explain the huge difference - up to 8 times - on clang or the same gcc on -O3 ?
Everything is simple here: in the case of uint32_t, clang can perform loop auto-vectorization:
.LBB1_6: ; =>This Inner Loop Header: Depth=1 vmovdqu ymm1, ymmword ptr [rax + 4*rdi] vmovdqu ymm2, ymmword ptr [rax + 4*rdi + 32] vmovdqu ymm3, ymmword ptr [rax + 4*rdi + 64] vmovdqu ymm4, ymmword ptr [rax + 4*rdi + 96] vpsubd ymm1, ymm1, ymm0 vpsubd ymm2, ymm2, ymm0 vpsubd ymm3, ymm3, ymm0 vpsubd ymm4, ymm4, ymm0 vmovdqu ymmword ptr [rax + 4*rdi], ymm1 vmovdqu ymmword ptr [rax + 4*rdi + 32], ymm2 vmovdqu ymmword ptr [rax + 4*rdi + 64], ymm3 vmovdqu ymmword ptr [rax + 4*rdi + 96], ymm4 vmovdqu ymm1, ymmword ptr [rax + 4*rdi + 128] vmovdqu ymm2, ymmword ptr [rax + 4*rdi + 160] vmovdqu ymm3, ymmword ptr [rax + 4*rdi + 192] vmovdqu ymm4, ymmword ptr [rax + 4*rdi + 224] vpsubd ymm1, ymm1, ymm0 vpsubd ymm2, ymm2, ymm0 vpsubd ymm3, ymm3, ymm0 vpsubd ymm4, ymm4, ymm0 vmovdqu ymmword ptr [rax + 4*rdi + 128], ymm1 vmovdqu ymmword ptr [rax + 4*rdi + 160], ymm2 vmovdqu ymmword ptr [rax + 4*rdi + 192], ymm3 vmovdqu ymmword ptr [rax + 4*rdi + 224], ymm4 add rdi, 64 add rsi, 2 jne .LBB1_6
The cycle was deployed 8 times, and this is in general the maximum performance that you can get: one vector (8 elements) per clock cycle for L1 cache (this will no longer work due to the limitation of one write operation per clock cycle (12)).
Vectorization is not performed for uint8_t , because it is hampered by the need to calculate size () to check the loop condition at each iteration. The reason for the lag is still the same, but the lag itself is much larger.
The lowest timings are explained by auto-vectorization: gcc applies it only at the -O3 level, and clang applies both at the -O2 level and at -O3 level by default. The -cc level gcc compiler generates slightly slower code than clang because it does not expand the autovectorized loop.
Correct the situation
We found out what the problem is - how can we fix it?
First, let's try one way that, however, will not work, namely, we will write a more idiomatic cycle based on an iterator:
for (auto i = v.begin(); i != v.end(); ++i) { (*i)++; }
The code that gcc generates at the -O2 level will be slightly better than the size () option:
.L17: add BYTE PTR [rax], 1 add rax, 1 cmp QWORD PTR [rdi+8], rax jne .L17
Two extra read operations turned into one, since i now we compare with the end pointer of the vector, rather than recalculating size () , subtracting the vector start pointer from the end pointer. In terms of the number of commands, this code caught up with uint32_t , since the extra read operation merged with the comparison operation. However, the problem has not gone away and auto-vectorization is still unavailable, so uint8_t is still significantly behind uint32_t - more than 5 times on both gcc and clang at the levels where auto-vectorization is provided.
Let's try something else. We won’t succeed again, or rather, we will find another non-working method.
In this version, we calculate size () only once before the loop and put the result in a local variable:
for (size_t i = 0, s = v.size(); i < s; i++) { v[i]++; }
It should seem to work? The problem was size () , and now we ordered the compiler to commit the result of size () to the local variable s at the beginning of the loop, and the local variables, as you know, do not intersect with other data. We actually did what the compiler could not do. And the code that it will generate will actually be better (compared to the original):
.L9: mov rdx, QWORD PTR [rdi] add BYTE PTR [rdx+rax], 1 add rax, 1 cmp rax, rcx jne .L9
There is only one extra read operation and no sub command. But what does this extra command ( rdx, QWORD PTR [rdi] ) do if it is not involved in the size calculation? It reads the data () pointer from v !
The expression v [i] is implemented as * (v.data () + i) , and the member returned by data () (and, in fact, a regular begin pointer) gives rise to the same problem as size () . True, I did not notice this operation in the original version, because there it was "free", because it still had to be performed in order to calculate the size.
Bear with a little more, we almost found a solution. You just need to remove from our loop all the dependencies on the contents of std :: vector . The easiest way to do this is to modify our idiom with an iterator a bit:
for (auto i = v.begin(), e = v.end(); i != e; ++i) { (*i)++; }
Now everything has changed dramatically (here we compare only versions with uint8_t - in one we save the end iterator in a local variable before the loop, in the other - no):

This small change gave us a 20-fold increase in speed at levels with auto-vectorization. Moreover, the code with uint8_t did not just catch up with the code with uint32_t - it overtook it almost exactly 4 times by gcc -O3 and clang -O2 and -O3 , as we expected at the very beginning, relying on vectorization: in the end, exactly four times more elements can be processed by a vector operation and we need four times less bandwidth - regardless of cache level (13).
If you read to this place, you must have exclaimed to yourself all this time:
But what about the range loop for-loop introduced in C ++ 11?
I hasten to please you: it works! This is, in fact, syntactic sugar, behind which our version with an iterator hides in almost the same form, where we fixed the end pointer in a local variable before the start of the loop. So his speed is the same.
If we suddenly decided to go back to ancient cave times and write a C-like function, such a code would work just as well:
void array_inc(uint8_t* a, size_t size) { for (size_t i = 0; i < size; i++) { a[i]++; } }
Here, the pointer to the array a and the variable size are passed to the function by value, so they cannot be changed as a result of writing to the pointer a (14) - just like local variables. The performance of this code is the same as that of the previous options.
Finally, on compilers where this option is available, you can declare a vector with __restrict (15):
void vector8_inc_restrict(std::vector<uint8_t>& __restrict v) { for (size_t i = 0; i < v.size(); i++) { v[i]++; } }
The __restrict keyword is not part of the C ++ standard, but part of the C standard since C99 (as restrict ). If it is implemented as a C ++ extension in the compiler, then most likely it will obey the semantics of C. Of course, there are no links in C, so you can mentally replace the vector link with a vector pointer.
Note that restrict does not have a transitive property : the action of the __restrict specifier, with which the link to std :: vector is declared, applies only to the members of the vector itself, and not to the heap region referenced by v.data () . In our case, more is not required, because (as is the case with local variables) it is enough to convince the compiler that the terms themselves, pointing to the beginning and end of the vector, do not intersect with anything. The clause about restrict , however, is still relevant, since writing via v.data () can still lead to other objects in your function changing due to aliasing.
Disappointment
Here we come to the last - and very disappointing - conclusion. The fact is that all the solutions shown above are applicable only to this specific case, when the vector can theoretically interfere with itself. The solution was to get out of the loop or isolate the result of calling the size () or end () of the vector, and not to tell the compiler that writing to the vector's data does not affect other data. Such code will be difficult to scale as the function grows.
The aliasing problem has not gone away, and the write commands can still go "anywhere" - there is simply no other data in this function that can be affected ... for now. As soon as a new code appears in it, everything will be repeated. Here is an example offhand . If you write to arrays of elements of the uint8_t type in small loops, you have to fight with the compiler to the end (16).
Comments
I will be glad to any feedback. I do not yet have a commenting system (17), so, as usual, we will discuss in this thread on HackerNews .
- By accessing the memory here, it is understood that the chain of dependencies passes through the memory: write commands at the same address should read the last value written there, therefore such operations are dependent (in practice, redirection for loading (STLF) will be used if recording is enough often). Dependencies of the add command when accessing memory can occur in other ways, for example, by calculating the address, but for our case this is irrelevant.
- Only a small cycle is shown here; The installation code is simple and it works fast. To see the full listing, upload the code to godbolt .
- Maybe it should be called simply "minimized"? Be that as it may, the gcc compiler does not usually loop around even at the -O2 and -O3 levels, except in special cases where the number of iterations is small and is known at the compilation stage . Because of this, gcc shows lower test results compared to clang, but it saves a lot on code size. You can force gcc to unroll loops by applying profile optimization or by turning on the -funroll-loops flag.
- Actually, the inc DWORD PTR [rax] command in gcc is a missed optimization: it is almost always better to use the add [rax], 1 command, since it consists of only 2 combined microoperations versus 3 for inc . In this case, the difference is only about 6%, but if the cycle were slightly expanded so that only the recording operation was repeated, the difference would be more significant (further expansion would no longer play a role, since we would reach the limit of 1 recording operation per cycle, which does not depend on the total number of micro-operations).
- I call this variable inductive , and not just i , as in the source code, because the compiler converted the unit operations of the increment i to 4-byte increments of the pointer stored in the rax register, and accordingly corrected the loop condition. In its original form, our loop addresses the elements of the vector, and after this conversion, it increments the pointer / iterator, which is one way to reduce the cost of operations .
- In fact, if you enable -funroll-loops , on gcc the speed will be 1.08 measures per element with an 8x roll- out. But even with this flag, he will not expand the loop for the version with 8-bit elements, so the lag in speed will be even more noticeable!
- These members have a private modifier, and their names are implementation dependent, but in stdlibc ++ they are not really called start and finish , as in gcc. They are called _Vector_base :: _ Vector_impl :: _ M_start and _Vector_base :: _ Vector_impl :: _ M_finish respectively , i.e. enter the _Vector_impl structure, which is a member of _M_impl (and the only one) of the _Vector_base class, and that, in turn, is the base class for std :: vector . Well well! Fortunately, the compiler easily copes with this pile of abstractions.
- The standard does not prescribe what the internal types of std :: vector members should be, but in the libstdc ++ library they are simply defined as Alloc :: pointer (where Alloc is the allocator for the vector), and for the default std :: allocated object they will simply pointers of type T * , i.e. regular pointers to an object - in this case, uint32_t * .
- I am making this reservation for a reason. There is a suspicion that uint8_t may be regarded as a type other than char , signed char and unsigned char . Since aliasing works with character types , this does not in principle apply to uint8_t and should behave like any other non-character type. However, none of the compilers I know think so: in all of them typedef uint8_t is an alias of unsigned char , so that compilers do not see the difference between them, even if they wanted to use it.
- By “unknown origin” I mean here only that the compiler does not know where the contents of the memory are pointing or how it appeared. This includes arbitrary pointers passed to the function, as well as global and static variables. , , , , , ( - ). , malloc new , , , , : , , . , malloc new .
- , std::vector - ? , std::vector<uint8_t> a a.data() placement new b . std::swap(a, b) , – , b ? , b . : - (, ), , .
- 8 , .. 32 . , std::vector .
- - 4 : , , – . : 8- L1, 32- – L2 , .
- , – : . , , «».
- v[i] , .
- . , «» , uint8_t . , , , uint8_t , . , clang, gcc , , uint8_t . - gcc , . , , - __restrict .
- - , , ( Disqus), ( ), .
. : Travis Downs. Incrementing vectors .