I recently returned to floating point error analysis to refine some of the details in the next edition of the Physically Based Rendering book. Floating-point numbers are an interesting area of computation, full of surprises (good and bad), as well as tricky tricks to get rid of unpleasant surprises.
In the process, I came across this post on StackOverflow , from which I learned about an elegant algorithm for exact calculation .
But before proceeding with the algorithm, you need to understand what is so cunning in expression ? Take , , and . (These are the real values that I got during the launch of pbrt .) For 32-bit float values, we get: and . We carry out the subtraction, and we get . But if you perform calculations with double precision, and at the end convert them to float, then you get . What happened
The problem is that the value of each work can go far beyond the bottom line , where the distance between representable floating point values is very large - 64. That is, when rounding and individually, to the nearest representable float, they turn into numbers that are multiples of 64. In turn, their difference will be a multiple of 64, and there will be no hope that it will become closer than . In our case, the result was even further due to how the two works were rounded in . We will directly encounter the good old catastrophic reduction 1 .
Here is a better solution than 2 :
inline float DifferenceOfProducts(float a, float b, float c, float d) { float cd = c * d; float err = std::fma(-c, d, cd); float dop = std::fma(a, b, -cd); return dop + err; }
DifferenceOfProducts()
computes in a way that avoids catastrophic contraction. This technique was first described by the legendary William Kahan in the article On the Cost of Floating-PointComputation Without Extra-Precise Arithmetic . It is worth noting that Kahan’s works are interesting to read as a whole, they contain many comments about the current state of the world of floating points, as well as mathematical and technical considerations. Here is one of his findings:
Those of us who have struggled with the vicissitudes of floating point arithmetic and poorly thought out "optimizations" of compilers can justly be proud of victory in this battle. But if we pass on the continuation of this battle to future generations, this will contradict the whole essence of civilization. Our experience says that programming languages and development systems are sources of too much chaos that we have to deal with. Too many mistakes can be dispensed with, as well as from some attractive “optimizations” that are safe for integers, but sometimes prove fatal for floating point numbers.
Having paid tribute to his wit, let us return to
DifferenceOfProducts()
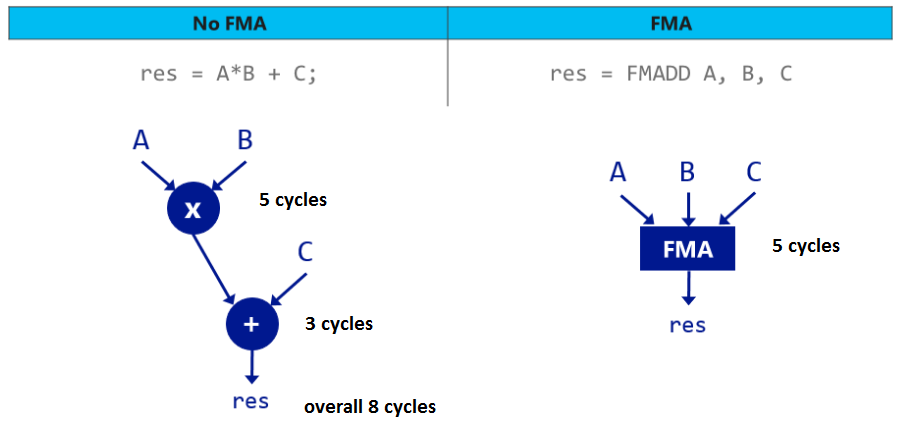
: the basis of the mastery of this function is the use of fused multiply-add, FMA 3 instructions. From a mathematical point of view,
FMA(a,b,c)
is Therefore, at first it seems that this operation is only useful as a microoptimization: one instruction instead of two. However fma
It has a special property - it rounds off only once.
In the usual first calculated , and then this value, which in the general case cannot be represented in floating point format, is rounded to the nearest float. Then to this rounded value is added , and this result is again rounded to the nearest float. FMA is implemented in such a way that rounding is performed only at the end - an intermediate value retains sufficient accuracy, so after adding to it the finished result will be closest to the true value value of float.
Having dealt with FMA, we will return to
DifferenceOfProducts()
. Again, I will show the first two lines of it:
float cd = c * d; float err = std::fma(-c, d, cd);
The first calculates the rounded value and the second ... subtracts from their work? If you do not know how FMA works, then you might think that
err
will always be zero. But when working with FMA, the second line actually extracts the value of the rounding error in the calculated value and saves it to
err
. After that, the output is very simple:
float dop = std::fma(a, b, -cd); return dop + err;
The second FMA calculates the difference between the works using the FMA, performing rounding only at the very end. Consequently, it is resistant to catastrophic reduction, but it needs to work with a rounded value. . The
return
"patches" this problem, adding the error highlighted in the second line. In an article by Jeannenrod et al. it is shown that the result is true up to 1.5 ulps (unit precision measures), which is great: FMA and simple floating point operations are accurate up to 0.5 ulps, so the algorithm is almost perfect.
We use a new hammer
When you start looking for ways to use
DifferenceOfProducts()
, it turns out to be surprisingly useful. Calculating the discriminant of the quadratic equation? Call
DifferenceOfProducts(b, b, 4 * a, c)
4 . Calculating the determinant of a 2x2 matrix? The algorithm will solve this problem. In the next version of pbrt, I found about 80 uses for it. Of all of them, the most beloved is the function of the vector product. It has always been a source of problems, because of which you had to raise your hands up and use double in the implementation to avoid a catastrophic reduction:
inline Vector3f Cross(const Vector3f &v1, const Vector3f &v2) { double v1x = v1.x, v1y = v1.y, v1z = v1.z; double v2x = v2.x, v2y = v2.y, v2z = v2.z; return Vector3f(v1y * v2z - v1z * v2y, v1z * v2x - v1x * v2z, v1x * v2y - v1y * v2x); }
And now we can continue to work with float and use
DifferenceOfProducts()
.
inline Vector3f Cross(const Vector3f &v1, const Vector3f &v2) { return Vector3f(DifferenceOfProducts(v1.y, v2.z, v1.z, v2.y), DifferenceOfProducts(v1.z, v2.x, v1.x, v2.z), DifferenceOfProducts(v1.x, v2.y, v1.y, v2.x)); }
That cunning example from the beginning of the post is actually part of a vector work. At a certain stage, the pbrt code needs to calculate the vector product of vectors and . When calculated using float, we would get a vector . (General rule: if in floating point calculations where large numbers are involved, you get not so large integer values, then this is almost a sure sign that a catastrophic reduction has occurred.)
With double precision, the vector product is . We see that with float looks normal already pretty bad as well becomes the disaster that has become the motivation for finding a solution. And what results will we get with
DifferenceOfProducts()
and float values? . Values and correspond to double precision, and slightly offset - hence the extra ulp came from.
What about speed?
DifferenceOfProducts()
performs two FMAs, as well as multiplication and addition. A naive algorithm can be implemented with one FMA and one multiplication, which, it would seem, should take half as much time. But in practice, it turns out that after getting the values from the registers, it doesn’t matter: in the synthetic benchmark held on my laptop,
DifferenceOfProducts()
only 1.09 times more expensive than the naive algorithm. Double precision operation was 2.98 times slower.
As soon as you learn about the possibility of a catastrophic reduction, all kinds of innocent looking expressions in the code begin to seem suspicious.
DifferenceOfProducts()
seems to be a good cure for most of them. It is easy to use, and we have no particular reason not to use it.
Notes
- A catastrophic reduction is not a problem when subtracting quantities with different signs or when adding values with the same sign. However, it can become a problem when adding values with different signs. That is, the amounts should be considered with the same suspicion as the differences.
- As an exercise for the reader, I suggest writing the
SumOfProducts()
function, which provides protection against catastrophic contraction. If you want to complicate the task, explain why inDifferenceOfProducts()
,dop + err == dop
, because the signsa*b
andc*d
are different. - The FMA instruction has been available on the GPU for more than a decade, and on most CPUs, for at least five years. It may be necessary to add compiler flags to the CPU to directly generate them when using
std::fma()
; in gcc and clang,-march=native
works. - In the IEEE floating point format, multiplication by powers of two is performed exactly, so
4 * a
does not cause any rounding error, unless overflow occurs.