There are types of software without which some people can’t live, while others don’t even imagine that such a thing exists and that anyone needs it at all. For me, for many years, such a program was Macropool WebResearch , which allowed me to save, read and organize web pages in a kind of offline library. I am sure that many of the readers are fine with a collection of links or a combination of a browser and a folder with a set of saved documents. I would like to be able to at least mark documents as “read” or “favorites”, quickly switch from one text to another and not depend on the availability of the Internet or a specific site. It happens that there is time to read exactly when there is no Internet (on the road, for example), and links, unfortunately, often turn out to be short-lived.
Apparently, the authors of WebResearch were counting on such people. This program was stuffed with a wide variety of functions: cataloging by sections and by tags, editing notes, all kinds of export / import, and so on. However, by about 2013, the project stopped updating, and then the developer's site also ceased to exist. For several years I was able to ride this horse, but first the browser plug-ins (available only for the then versions of IE and FireFox) fell off, and then modern sites stopped displaying normally in the viewer based on the old IE engine.
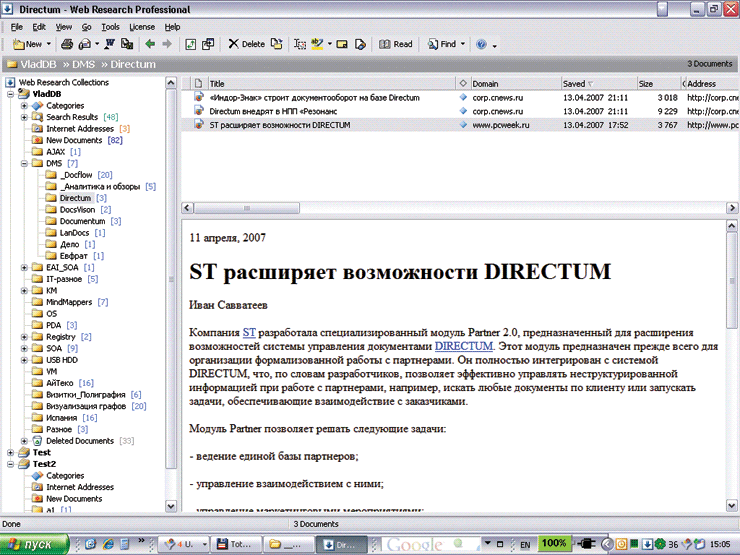
Main window WebResearch, PC Week / RE No. 17 (575)
Road of disappointment
As soon as it became clear that replacements could not be avoided, I set about searching for a decent counterpart in the background. It seemed to me that there would be no particular difficulties, because my desires are extremely modest. I was ready to get by with just a small subset of WebResearch tools, including:
- Saving HTML pages from the browser using the extension;
- at least minimal means of cataloging (renaming, organizing directories, tags);
- (preferably) support for PDF documents;
- any decent way to sync a collection with other devices.
To my surprise, I did not manage to find anything similar, although I honestly climbed the Internet up and down and carefully studied dozens of suitable annotation programs (with the exception of Evernote, where similar description functionality is available only by subscription). To date, at least somehow they satisfy my wishes except for the TagSpaces and myBase projects . Their study, generally speaking, is of certain cultural interest.
TagSpaces is such a "stylish-fashion-youth" organizer on Electron with a beautiful website, adaptive layout and, of course, a dark theme, where without it. At the same time, the ill-fated table of contents of the collection with fashionable rounded icons occupies half the screen, while holding twenty pieces at most, and basic pieces like supporting hot keys or rendering the document you are viewing are written according to the residual principle. As a result, documents are displayed crookedly, and work with the collection turns into a boring and time-consuming set of exercises with the mouse.
Its antipode myBase comes from the late nineties: here, in addition to a purely functional interface, we have an extremely rich set of settings and functions. However, the browser on the basis of the old IE acts as a viewing window here (which already makes reading difficult), and all documents are stored in a monolithic database. If you put it in the Dropbox folder, for example (there are still no other ways to synchronize with other devices), then with the slightest change in the collection you have to wait for hundreds of megabytes of information to be downloaded to the server.
Turning point
Probably the further content of the note seems obvious to the reader: now we will be offered our own bike, which, of course, will be a cut above any existing analogue. As if yes, but not really. I really could not stand the ordeals with myBase and TagSpaces and sketched my own document manager, a link to which I will bring closer to the end. However, this small-scale project for personal needs alone would not deserve a separate article; I write more because I found it interesting to share the experience gained during the work and a number of unpleasant surprises that I could not count on.
Targets and goals
To begin with, I have a rather stressful life now, and there is simply no time for full-fledged hobby projects. Therefore, from the very beginning, I decided that I was ready to sculpt my tool from any components that would come to hand, if this would speed things up. In addition, for now I’m only trying to implement an absolute minimum of functionality, which cannot be dispensed with.
Data Format and Saving Pages
How to store web pages on disk? Given the previously formulated requirements, it seemed to me that the choice was small: either the "full web page" save format, that is, the main HTML file and folder with related resources, or the MHTML format. The first option immediately seemed less preferable to me: it’s not great to have garbage on the disk from a heap of files from which you need to extract meaningful documents, filter out excess when searching and monitor integrity when copying. When I tried to work with TagSpaces, I had to re-save all my documents so that the name of the resource folder began with a dot: then the system recognized them as "hidden" and did not display it.
This problem is hidden from view in myBase, because everything is stored in the database, but in my case the principle of simplicity prevailed: I really wanted to store everything in the form of ordinary files on disk so that I would not have to deal with the implementation of routine operations like copying, renaming, deleting and synchronizing .
The MHTML format is going through hard times. An easy way to save MHTML was thrown out of Chrome this summer , and I don’t even know what it is now supposed to store pages in. It is clear that the opportunity has not yet disappeared, there are third-party extensions, but in general this is some kind of bad sign. In addition, saving in MHTML format is not supported in the Chromium Embedded Framework , which also does not add optimism.
In parallel, I began to look for an easy way to save pages from the browser to the specified folder. As a result, both problems were resolved with a little blood: I came across a wonderful SingleFile project that can save the contents of a web page in a separate independent HTML file. This is done by converting all related resources to base64 format and embedding it directly in HTML. Of course, the file size grows, and the contents look a bit garbage, but in general, the approach seemed reliable and simple, and I settled on it.
SingleFile comes as a browser extension or as a command-line application. Now I just use the extension: it is quite convenient, except for the fact that you need to manually select the destination folder to save. In the future, I will probably try to finalize the application to simplify this process. To call a third-party application from Chrome, you can use the External Application Button extension - this is another useful discovery of mine. By the way, the application has already benefited: with its help, I converted the collection of folders and files from TagSpaces into a set of stand-alone HTML documents.
Hassle with GUI and browser
It seemed to me that Python is well suited for all kinds of simple operations with files and strings, and since wxWidgets is used in one of my working projects, choosing wxPython as the main framework seemed logical.
Further, having looked at the jambs with the display of pages in other programs, I concluded for myself that the only reliable way to deal with them is to introduce a visualizer based on a modern browser, that is, Chrome or Firefox, into the program.
I must admit that the last time I had to do something like that about 15 years ago, and I did not expect any dirty tricks. It turned out that "you can’t just slap the browser onto the form" is impossible: somehow, humanity has failed to reliably and universally cope with this task. Any listbox or button on the form can be placed in any GUI framework, and even generate cross-platform code, and it seemed to me that in 2019 the display of HTML should also have been a universally solved problem.
It turned out that in wxWidgets, for example, the standard “browser” component is a cross-platform wrapper over a system-dependent “browser”, which in the case of Windows, for example, means Internet Explorer 7 , and the situation in Windows Forms is no better, and versions fresh than IE9 are available only with the help of non-trivial registry manipulations . As you can see, the last 15 years I haven’t been alone in other matters - here, too, nothing has moved.
Next, I had a choice: change the framework or look for an alternative component for the browser. After hesitating, I decided to try the second way first and quickly came across a Python CEF project : Python bindings for Chromium Embedded Framework , designed specifically for the task of embedding Chromium in Python applications.
Evaluate the situation: Python is one of the most popular programming languages in the world, Chrome is essentially a monopolist in the browser market. At the same time, CEF Python is actually supported by the energy of one guy , his strength and health. Does anyone really need this anymore? ..
However, CEF Python did not help me in the end: although even the basic example of integration with wxWidgets from the project repository is clearly buggy, I tried to tinker with it longer, but could not solve all the problems that arise. I will not even delve into the topic, it is unlikely that it deserves it.
I studied the components based on the Chromium Embedded Framework in more detail and eventually decided to try the version for C # . Since I work almost all the time with Windows, the prospect of abandoning the cross-platform platform did not bother me, in general.
After some inevitable fuss at the start, things went much faster: the combination of CefSharp and Windows Forms turned out to be winning, and I managed to solve most of the technical problems without any problems.
About untested
You can try to implement FireFox in a C # application using the Geckofx component, but I can’t say anything about it. The standard Qt browser component called QWebEngineView is based on Chromium , so it will probably work no worse than CefSharp.
Fans of Qt may be tempted to comment: they say, I would take Qt, I would not have problems. It is possible that it is, but wxWidgets can be considered, if not the first, then the second option when choosing a GUI framework for applications in Python or C ++. And in my humble opinion, such a thing as a browser should be embedded in any more or less developed GUI framework without dancing with a tambourine.
Weblibrary
Let us return, however, to my application with the working title WebLibrary . Today it looks like (drum roll) like this:
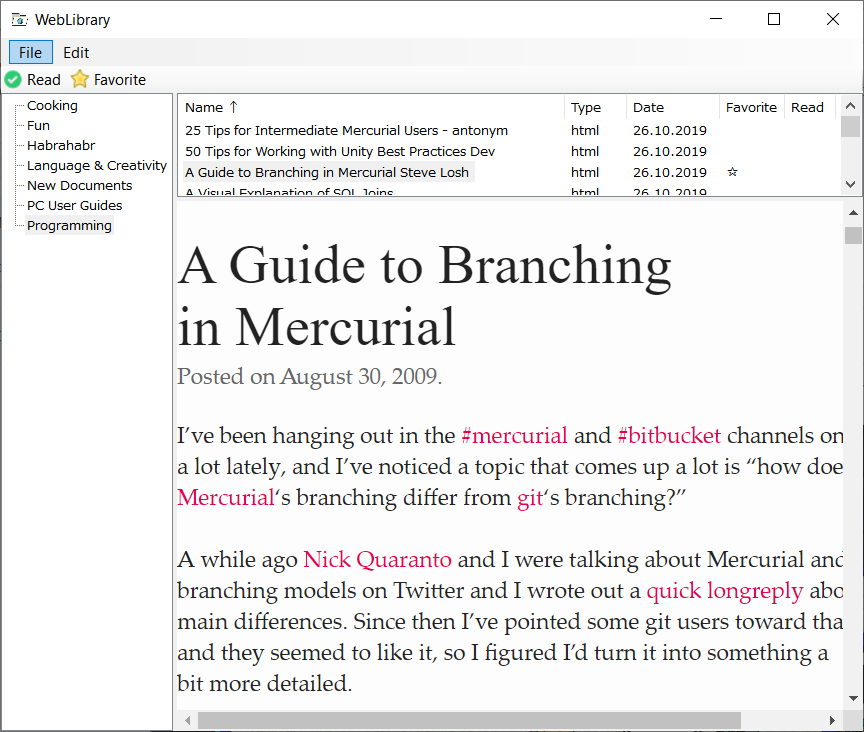
In addition to a clean and concise interface , only the most basic functions are implemented here:
- Displays any specified directory in the system as a document library.
- View documents in a browser window. Navigating the list in the usual way (cursor keys, PgUp, PgDn, Home, End), scrolling in the browser with the Space and Shift + Space keys.
- Rename documents.
- Mark documents as read or selected using hotkeys.
- Sort documents by any field.
- Updating the application window with any changes in the library folder.
- Saving window settings on exit.
All this may seem like trivial functionality, but, let's say, saving column sizes in TagSpaces is still not supported - apparently, the authors have different priorities.
The status (read / selected) is simply stored in the file name (the read doc.html
file doc.html
renamed to doc{R,S}.html
). Synchronization as such is not implemented, but I just keep the library in Dropbox - in the end, it's just a folder with files.
There are plans to finalize simple things like moving and deleting files, as well as implement tagging with arbitrary tags. If anyone wants to help, I will only be glad.
conclusions
Variety. As I said from the very beginning, it is amazing how much the tools of one person can differ from the tools of another. For me, using a tool like WebResearch is natural, and I felt almost physical discomfort from its absence. At the same time, apparently, I have few like-minded people, otherwise there would have been no problem finding analogues. On the other hand, similar cases occur with much more mainstream software: for example, Microsoft is not going to update the desktop version of OneNote, so I have to use the 2016 version, and sooner or later I will have to move somewhere from it too.
What is even more surprising is how difficult it is to navigate in the current landscape of libraries and frameworks. As a result of my service, I rarely have to write desktop applications from start to finish, and I assumed that literally any tool for any programming language would be suitable for my task (one window, three components, trivial interactions). We’ll take anything directly and do it within a few days.
It turned out that reality is much less benevolent, and you can run into a problem simply out of the blue. Let's say I have two splitter s that can be used to extend the browser window. So, restoring their position after loading into wxWidgets is extremely difficult, because the system puts them in the default position after almost all the events available to me, and you have to do all kinds of hacking to get what you need. Who would have guessed?
On the other hand, it is clear that in Windows Forms everything is tailored to "business interfaces". Almost everything that was required turned out to be available out of the box: both saving / restoring application settings, and a user-friendly interface of components (say, I did not expect that the TreeView component can be requested the full path from the root to any child element as a string), and non-trivial tools like a tracker for changing the contents of a folder.
In any case, the time wasted not in vain, and the result can be considered satisfactory, so what more could you want from life, right?