
The palette allows the artist to smear and mix paints of different colors. SpaceFusion is committed to helping AI scientists do similar things for different models trained on different datasets.
For modern deep learning models, data sets are usually represented by vectors in different hidden spaces using different neural networks. In the article “ Joint Optimization of Diversity and Relevance in the Generation of Neural Reactions ,” my co-authors and I present SpaceFusion, a training paradigm that can “mix” various hidden spaces - like paints on a palette - so that AI can use the patterns and knowledge embedded in each of them. Implementation of this work is available on GitHub .
Capture the color of human conversation
As a first attempt, we applied this technique to neural interactive AI. In our setup, the neural model is expected to generate relevant and interesting responses based on the conversation history or context. Despite the fact that promising successes have been achieved in neural communication models, these models, as a rule, try not to take risks, reproducing general and boring answers. Approaches have been developed to diversify these responses and better reflect the color of human conversation, but a compromise often arises with a decrease in relevance. .
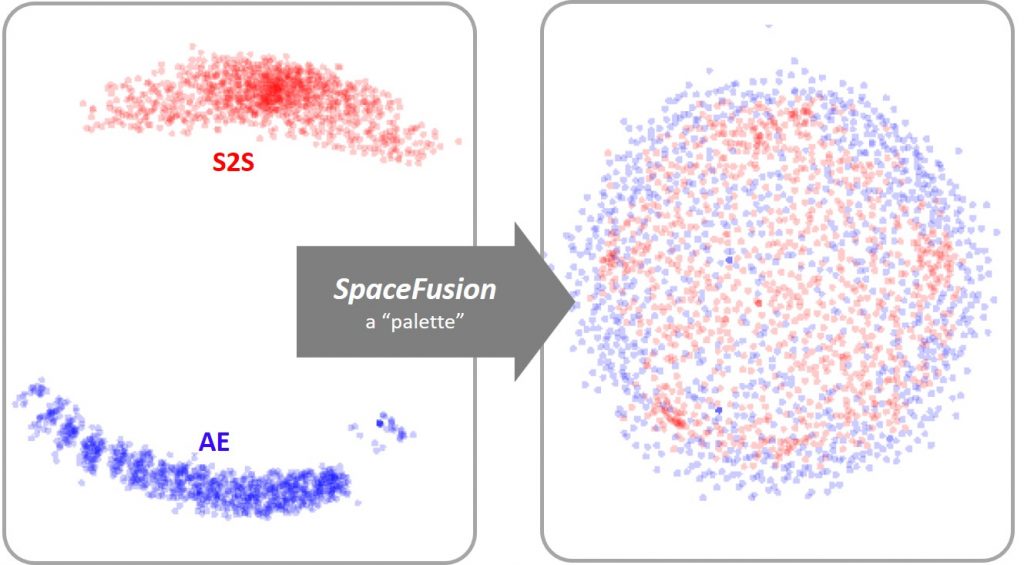
Figure 1: Like a palette that makes it easy to combine paints, SpaceFusion evens out or mixes hidden spaces from seq2seq (S2S, red dots) and autoencoder (AE, blue dots) to share the two models more efficiently.
SpaceFusion solves this problem by linking hidden spaces extracted from two models (Figure 1):
- a sequence-to-sequence (S2S) model that seeks to get relevant answers, but may have few differences; and
- an autoencoder (AE) model that is capable of presenting different answers but does not reflect their relationship with the conversation.
A co-trained model can harness the strengths of both models and organize data points in a more structured way.
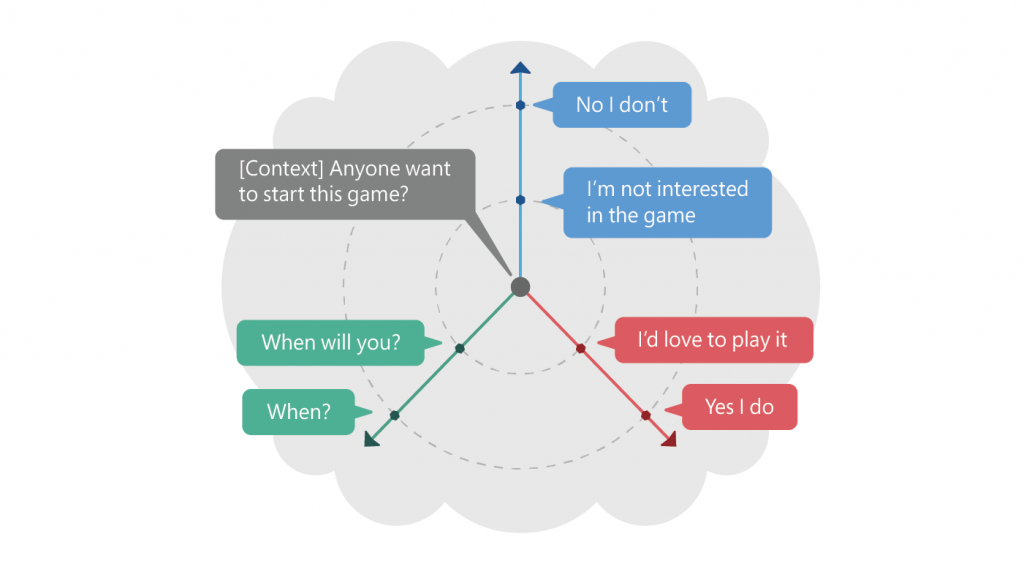
Figure 2: The above shows one context and its many responses in hidden space caused by SpaceFusion. The distance and direction from the predicted response vector, taking into account the context, approximately correspond to significance and diversity, respectively.
For example, as shown in Figure 2, given the context — in this case, “Does anyone want to start this game?” - the positive answers “I would like to play it” and “Yes, I play” are located along one direction. The negative ones - “I'm not interested in the game” and “No, I'm not interested” - are mapped in a different direction. Diversity in answers is achieved through the study of hidden space in different directions. In addition, the distance in the hidden space is relevant. Answers that are farther from the context - “Yes, I play” and “No, I do not play” - are usually general in nature, while those who are closer are more relevant to the specific context: “I am not interested in the game” and “When are you going to play? "
SpaceFusion separates relevance and diversity criteria and presents them in two independent dimensions - direction and distance - facilitating joint optimization of both. Our empirical experiments and evaluations in humans have shown that SpaceFusion performs better on these two criteria compared to competitive baselines.
Learning shared hidden space
So how exactly does SpaceFusion map different hidden spaces?
The idea is quite intuitive: for each pair of points from two different hidden spaces, we first minimize their distance in the common hidden space, and then maintain a smooth transition between them. This is done by adding two new regularization term - distance term and smoothness term - to the target function.
Taking the conversation as an example, distance term measures the Euclidean distance between the point from the hidden space S2S, which is displayed based on the context and represents the predicted response, and the points from the hidden space AE that correspond to its target answers. Minimizing this distance encourages the S2S model to display the context as a point close and surrounded by its responses in a common hidden space, as shown in Figure 2.
Smoothness term measures the probability of generating a target response from random interpolation between a point displayed from a context and a point displayed from a response. By maximizing this probability, we encourage a smooth transition in the value of the generated responses as you move away from the context. This allows us to explore the neighborhood of the prediction point made by S2S, and thus generate a variety of answers that are relevant to the context.
With these two new regularizations added to the objective function, we impose distance and evenness restrictions on learning hidden spaces, so training will not only focus on performance in each hidden space, but will also try to align them together by adding these desired structures. Our work has focused on interactive models, but we expect SpaceFusion to align hidden spaces trained by other models on different datasets. This will connect the various abilities and areas of knowledge learned by each particular AI system, and is the first step towards a more comprehensive AI.
See also: 7 free developer courses