
→ The first part
Programmers who are tired of linting
Considering that we have about a hundred of our own linting rules, pedantic accounting of recommendations issued by these rules can quickly result in a waste of developers time. It would be better to spend the time that is spent on straightening the code style or getting rid of obsolete patterns to create something new and to develop the project.
We found that when programmers see too many notifications coming from the linter, they begin to ignore all these messages. This also applies to important notifications.
Suppose we decide to declare the function
fn
obsolete and use a function with a better name,
add
, instead. If you do not inform the developers about this, they will not know that they no longer need to use the
fn
function. Even worse, they don’t know what to use instead of this function. In this situation, you can create a linter rule. But any large code base will already contain many rules. As a result, it is likely that an important linter notification will be lost in the heap of notifications of minor bugs.

Linter is too nit-picking and the “useful signal” can easily get lost in the “noise”
What shall we do with this?
You can automatically fix many problems detected by the linter. If the linter itself can be compared with the documentation that appears where it is needed, then such automatic corrections are a bit of a refactoring of code that is executed where it is needed. Given the large number of developers working on Instagram, it is almost impossible to train each of them in our best code writing techniques. Adding automatic code correction capabilities to the system allows us to educate developers on new techniques when they are not aware of these techniques. This helps us quickly get developers up to date. Automatic corrections, in addition, allowed us to make programmers focus on important things, rather than focusing on monotonous minor code changes. In general, it can be noted that automatic code corrections are more efficient and useful in terms of training developers than simple linter notifications.
So, how to create a system for automatic code correction? A syntax tree based lint gives us information about a dysfunctional node. As a result, we do not need to create logic to detect problems, since we already have the corresponding rules for the linter! Since we know about which particular node does not suit us, and about where its source code is located, we can, without risking spoiling something, for example, replace the name of the function
fn
with
add
. This is well suited to correcting single violations of the rules that are executed as such violations are detected. But what if we introduce a new rule for the linter, which means that there can be hundreds of code fragments in the code base that do not comply with this rule? Can all these inconsistencies be corrected in advance?
Code Mods
A codemod is just a way to find problems and make changes to the source code. Codemods are script based. Codmod can be thought of as "refactoring on steroids." The range of tasks solved by code modes is extremely wide: from simple ones, such as renaming a variable in a function, to complex ones, such as rewriting a function so that it takes a new argument. When working with the codemod, the same concepts are used as with the operation of the linter. But instead of informing the programmer about the problem, as the linter does, the code mode automatically solves this problem.
How to write a codemod? Consider an example. Here we want to stop using
get_global
. In this situation, you can use the linter, but it will not be known how long it will take to fix the entire code, in addition, this task will be distributed among many developers. At the same time, even if the project uses a system of automatic code correction, it may take some time to process all the code.

We want to get away from using get_global and use instance variables instead
To solve this problem, we can, together with the linter rule that detects it, write a codemod. We believe that allowing outdated patterns and APIs to gradually leave code will distract developers and degrade code readability. We prefer to immediately remove the obsolete code, and not watch how it gradually disappears from the project.
Given the volume of our code and the number of active developers, this often means automatically eliminating obsolete designs. If we are able to quickly clear code from obsolete patterns, this means that we can maintain the productivity of all Instagram developers.
So, how to make a codemod? How to replace only the code fragment that interests us, while preserving the comments, indents and everything else? There are tools based on a specific syntax tree (like what LibCST creates) that allow you to modify the code with surgical precision and save all auxiliary constructions in it. As a result, if we need to change the function name from
fn
to
add
in the tree below, then we can write the name
add
instead of
fn
in the
Name
node, and then write the tree to disk!
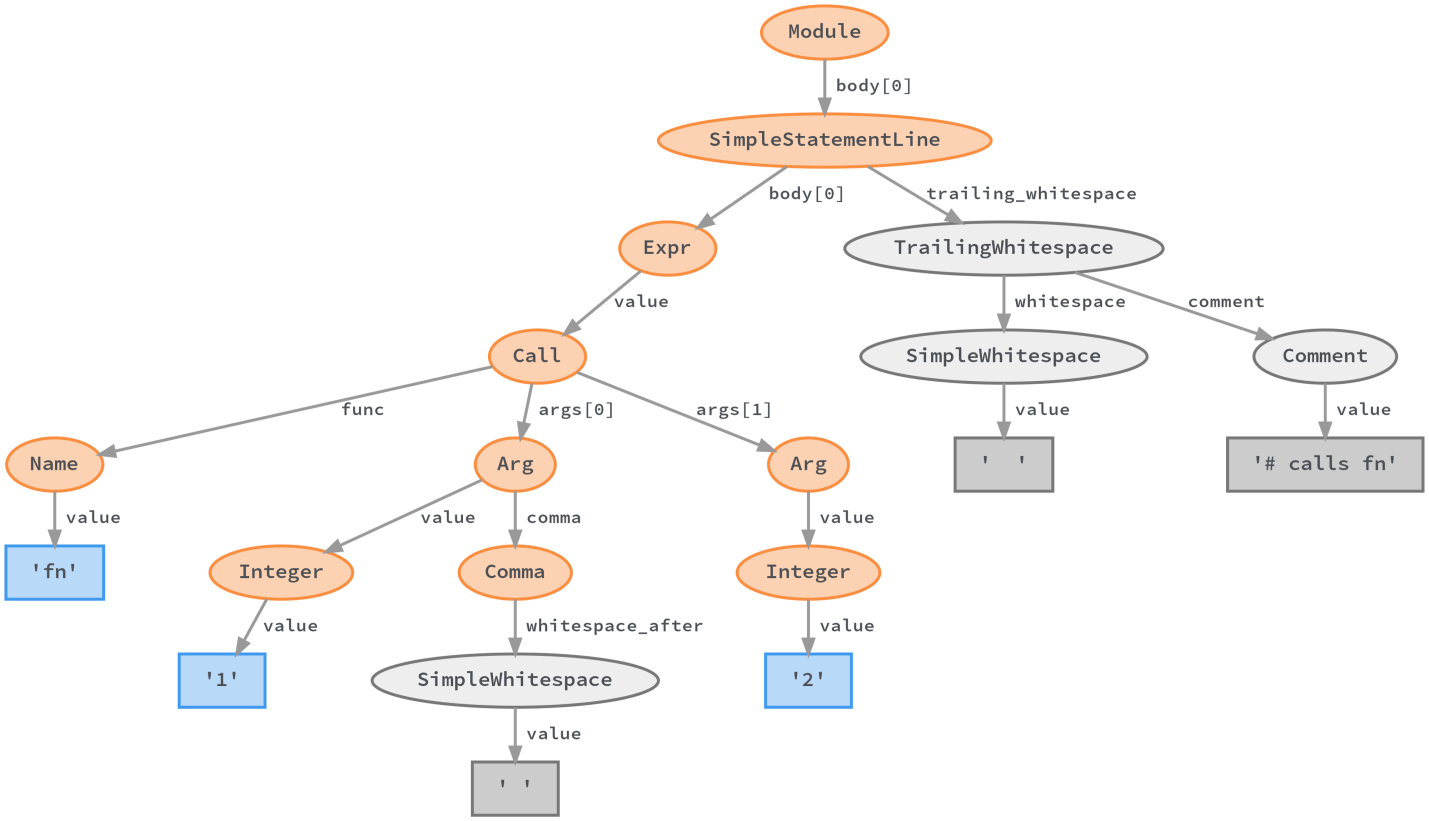
You can do the code mode by writing add to the Name node instead of fn. Then the changed tree can be written to disk. You can read more about this in the LibCST documentation .
Now that we’ve got a little familiar with the code mods, let's take a look at a practical example. Instagram employees are working hard to make the code base of the project fully typed. Kodmody seriously help them in this matter.
If we have a certain set of untyped functions that need to be typed, we can try to generate the types returned by them by the usual type inference! For example, if a function returns values of only one primitive type, we simply assign this type of return value to the function. If a function returns values of a boolean type, for example, if it compares something with something or checks something, then we can assign it the return value type
bool
. We found that in the course of practical work with the Instagram codebase, this is a pretty safe operation.

Finding out the types of values returned by functions
But what if the function does not explicitly return any value, or implicitly returns
None
? If the function does not explicitly return anything, it can be assigned the type
None
.
This, unlike the previous example, can be more dangerous due to the existence of common patterns that developers use. For example, in a base class method, you can throw a
NotImplemented
exception, and in methods of subclasses that override this method, you can return a string. It is important to note that all these techniques are heuristic, but the results of their application quite often turn out to be correct. As a result, they can be considered useful.

Functions That Return Nothing
Expanding Code Modules with Pyre
Let's go one step further. Instagram uses Pyre, a full-blown static type checking system similar to mypy. Using Pyre allows us to check types in a codebase. What if we used the data generated by Pyre in order to expand the capabilities of codemods? The following is an example of such data. It’s easy to see that there’s almost everything you need to automatically fix type annotations!
$ pyre ƛ Found 2 type errors! testing/utils.py:7:0 Missing return annotation [3]: Returning `SomeClass` but no return type is specified. testing/utils.py:10:0 Missing return annotation [3]: Returning `testing.other.SomeOtherClass` but no return type is specified.
Pyre during the work performs a detailed analysis of the execution order of each function. As a result, this tool can sometimes with a very high probability make an assumption that an unannotated function should return. This means that if Pyre believes that the function returns a simple type, we assign this function the return type. However, now, in potential, we need to process import commands as well. This means that we need to know if something is imported or declared locally. Later we will briefly touch upon this topic.
What benefits do we get from automatically adding type information that is easily displayed in the code? Well, types are documentation! If the function is fully typed, then the developer will not have to read its code in order to find out the features of its call and the features of using what it returns.
def get_description(page: WikiPage) -> Optional[str]: if page.draft: return None return page.metadata["description"] # <- ?
Many of us have come across similar Python code. Something similar is also seen in the Instagram codebase. If the
get_description
function were untyped, then you would need to look into several modules in order to find out what it returns. At the same time, even if we are talking about simpler functions, the types of return values of which are easy to derive, their typed variants are perceived more easily than untyped ones.
In addition, Pyre does not verify the correct functioning of the function body in the event that the function is not completely annotated. In the following example, the call to
some_function
will fail. It would be nice to know about this before the code gets into production.
def some_function(in: int) -> bool: return in > 0 def some_other_function(): if some_function("bla"): # <- print("Yay!")
In this case, we can well find out about a similar error after the code has gone into production. The fact is that
some_other_function
does not have return type annotation. If we annotated it using our heuristic mechanisms using the automatically deduced type
None
, we would have discovered a problem with the types before it could cause any problems. This, of course, is an artificial example, but on Instagram such problems are serious. If you have millions of lines of code, then you, in the code review process, may well miss out on such things that seem completely obvious in a simple example.
In Instagram, the above methods based on automatically deduced types allowed typing about 10% of functions. As a result, people no longer had to manually edit thousands and thousands of functions. The advantages of typed code are obvious, but this, in the context of our conversation, leads to another important advantage. A fully typed codebase opens up even greater possibilities for processing code using codemods.
If we trust type annotations, it means that Pyre can open up additional possibilities for us. Let's look again at the example where we renamed the functions. What if the entity we are renaming is represented by a class method, rather than a global function?

Function is a class method
If you combine the type information received from Pyre and the code mode that renames the functions, you can, unexpectedly, make corrections both to where the function is called and where it is declared! In this example, since we know what is on the left side of the
a.fn
construct, we also know that it is safe to change this construct to
a.add
.
More advanced static analysis

Python has four types of scopes: global scope, class and function level scope, nested scope
The analysis of scope allows us to use even more powerful code modes. Remember one of the above examples, where we talked about the fact that adding type annotations can also mean the need to work with import commands? If the system analyzes the scope, this means that we can know which types used in the file are present in it thanks to import commands, which are declared locally and which are missing. Similarly, if you know that a global variable is overlapped by a function argument, you can avoid accidentally changing the name of such an argument when renaming a global variable.
Summary
In our quest to correct all errors in the Instagram code, we understood one thing. It consists in the fact that the search for the code that needs to be fixed is often more important than the fix itself. Programmers often have to solve simple tasks - such as renaming functions, adding arguments to methods, or dividing modules into parts. All this is commonplace, but the size of our code base means that a person will not be able to find every line that needs to be changed. That is why it is so important to combine the capabilities of codemods with reliable static analysis. This allows us to more confidently find those parts of the code that need to be changed, which means that it allows us to make code modes safer and more powerful.
Dear readers! Do you use code mods?

