Preparing to work on a new planner, I spent time searching for thematic resources. Apart from the actual implementations, nothing special was found. I also found that the source code for existing implementations is hard to navigate. To fix this, we tried to write the Tokio sheduler as cleanly as possible. I hope this detailed article on the implementation of the scheduler will help those who are in the same position and unsuccessfully looking for information on this topic.
The article begins with a high-level review of design, including job capture policies. Then dive into the details of specific optimizations in the new Tokio scheduler.
Considered optimizations:
- New std :: future task system
- Choosing the best queue algorithm
- Streamline Message Templates
- Throttle capture
- Reduce synchronization between threads
- Reduce memory allocation
- Reduce atomic link counting
As you can see, the main theme is “reduction.” In the end, the fastest code is its lack!
We will also talk about testing the new scheduler . It is very difficult to write the correct, parallel code without locks. It is better to work slowly, but correctly, than quickly, but with glitches, especially if the bugs relate to memory security. The best option, however, should work quickly and without errors, so we wrote loom , a concurrency testing tool.
Before diving into the topic, I want to thank:
- @withoutboats and others who worked on the
async / await
function in Rust. You did a great job. This is a killer feature.
- @cramertj and others who developed
std::task
. This is a huge improvement over what it was before. And great code.
- Buoyant , the creator of Linkerd, and more importantly, my employer. Thank you for letting me spend so much time on this job. If someone is interested in the service mesh, look at Linkerd. Soon it will include all the benefits discussed in this article.
- Go for such a good planner implementation.
Take a cup of coffee and sit back. This will be a long article.
How do planners work?
The task of the sheduler is to plan work. The application is divided into units of work, which we will call tasks . A task is considered to be runnable when it can advance in its execution, but no longer completed or in idle mode, when it is locked on an external resource. Tasks are independent in the sense that any number of tasks can be performed simultaneously. The scheduler is responsible for running tasks in a running state until they return to standby mode. Task execution implies assigning processor time to the task - a global resource.
The article discusses user space schedulers, that is, working on top of operating system threads (which, in turn, are controlled by a kernel level sheduler). The Tokio Scheduler executes Rust futures, which can be thought of as “asynchronous green threads.” This is a M: N mixed streaming pattern in which many user interface tasks are multiplexed onto multiple threads of the operating system.
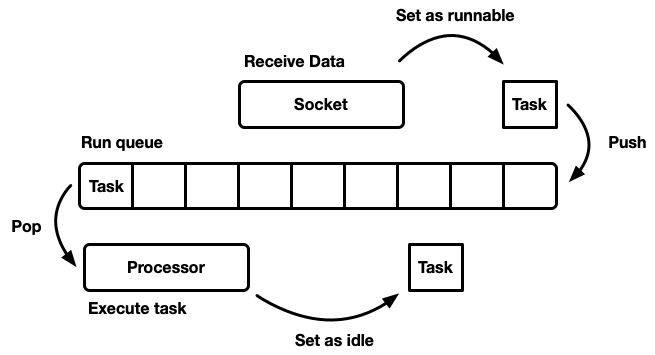
There are many different ways to simulate a sheduler, each with its own pros and cons. At the most basic level, the scheduler can be modeled as a run queue and a processor that pulls it apart. A processor is a piece of code that runs in a thread. In pseudo code, it does the following:
while let Some(task) = self.queue.pop() { task.run(); }
When a task becomes feasible, it is inserted into the execution queue.
Although you can design a system in which resources, tasks, and a processor exist on the same thread, Tokio prefers to use multiple threads. We live in a world where a computer has many processors. The development of a single-threaded scheduler will lead to insufficient loading of iron. We want to use all the CPUs. There are several ways to do this:
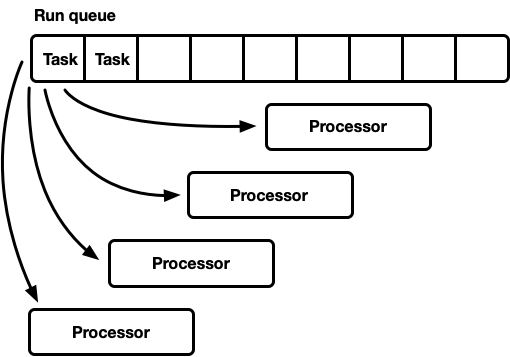
- One global execution queue, many processors.
- Many processors, each with its own run queue.
One turn, many processors
This model has one global execution queue. When tasks become complete, they are placed at the tail of the queue. There are several processors, each in a separate thread. Each processor takes a task from the head of the queue or blocks the thread if there are no tasks available.
The execution queue must be supported by many manufacturers and consumers. Usually an intrusive list is used, in which the structure of each task includes a pointer to the next task in the queue (instead of wrapping the tasks in a linked list). Thus, memory allocation for push and pop operations can be avoided. You can use the push operation without locking , but to coordinate consumers, the pop operation requires a mutex (it is technically possible to implement a multi-user queue without locking).
However, in practice, overhead for proper protection against locks is more than just using a mutex.
This approach is often used for a general-purpose thread pool, because it has several advantages:
- Tasks are fairly planned.
- Relatively simple implementation. A more or less standard queue is interfaced with the processor cycle described above.
A brief note on fair (equitable) planning. It means that the tasks are carried out honestly: whoever came earlier is the one who left earlier. General-purpose planners try to be fair, but there are exceptions, such as parallelization via fork-join, where the speed of calculating the result, rather than justice for each individual subtask, is an important factor.
This model has a downside. All processors apply for tasks from the head of the queue. For general purpose threads, this is usually not a problem. The time to complete a task far exceeds the time to retrieve it from the queue. When tasks are performed over a long period of time, competition in the queue is reduced. However, asynchronous Rust tasks are expected to complete very quickly. In this case, the overhead for the fight in the queue increases significantly.
Concurrency and mechanical sympathy
To achieve maximum performance, we must make the most of the hardware features. The term “mechanical sympathy” for software was first used by Martin Thompson (whose blog is no longer updated but still very informative).
A detailed discussion of the implementation of parallelism in modern equipment is beyond the scope of this article. Generally speaking, iron increases performance not due to acceleration, but due to the introduction of a larger number of CPU cores (even my laptop has six!) Each core can perform large amounts of computation in tiny time intervals. Actions such as accessing the cache and memory take much longer relative to the execution time on the CPU. Therefore, to speed up applications, you need to maximize the number of CPU instructions for each memory access. Although the compiler helps a lot, we still have to think about things like alignment and memory access patterns.
Separate threads separately work very much like a single isolated thread, until several threads simultaneously modify the same cache line (concurrent mutations) or consistent consistency is required. In this case, the CPU cache coherence protocol is activated. It guarantees the relevance of the cache of each CPU.
The conclusion is obvious: as far as possible, avoid synchronization between threads, because it is slow.
Many processors, each with its own execution queue
Another model is several single-threaded schedulers. Each processor receives its own execution queue, and tasks are fixed on a specific processor. This completely avoids the synchronization problem. Since the Rust task model requires the ability to queue a task from any thread, there should still be a thread-safe way to enter tasks into the scheduler. Either the execution queue of each processor supports thread-safe push operation (MPSC), or each processor has two execution queues: unsynchronized and thread-safe.
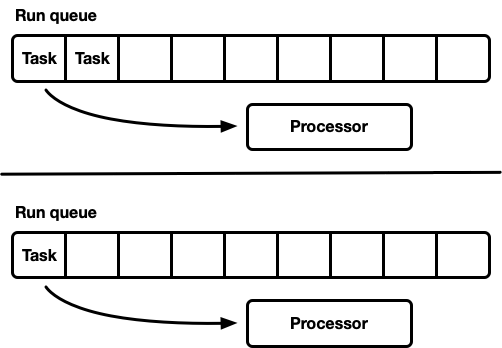
This strategy uses Seastar . Since we almost completely avoid synchronization, this strategy gives very good speed. But she does not solve all the problems. If the workload is not completely homogeneous, then some processors are under load, while others are idle, which leads to not optimal use of resources. This happens because tasks are fixed on a specific processor. When a group of tasks is planned in a package on one processor, it single-handedly fulfills the peak load, even if others are idle.
Most “real” workloads are not homogeneous. Therefore, general purpose planners usually avoid this model.
Job Capture Scheduler
The scheduler with work-stealing schedulers is based on the sharded scheduler model and solves the problem of incomplete loading of hardware resources. Each processor supports its own execution queue. Tasks that become performed are placed in the execution queue of the current processor, and it works on it. But when the processor is idle, it checks the queues of the sister processor and tries to grab something from there. The processor goes into sleep mode only after it cannot find work from peer-to-peer execution queues.

At the model level, this is the “best of both worlds” approach. Under load, processors work independently, avoiding overhead synchronization. In cases where the load between the processors is distributed unevenly, the scheduler can redistribute it. This is why such schedulers are used in Go , Erlang , Java, and other languages.
The disadvantage is that this approach is much more complicated. The queue algorithm must support job capture, and for smooth execution some synchronization between processors is required. If it is not implemented correctly, then the overhead for capturing can be more than the gain.
Consider this situation: processor A is currently executing a task, and it has an empty execution queue. Processor B is idle; he tries to capture some task, but fails, so he goes into sleep mode. Then 20 tasks are spawned from the task of processor A. Ideally, processor B should wake up and grab some of them. To do this, it is necessary to implement certain heuristics in the scheduler, where processors signal sleeping peer processors about the appearance of new tasks in their queue. Of course, this requires additional synchronization, so such operations are best minimized.
Eventually:
- The less synchronization, the better.
- Job capture is the optimal algorithm for general purpose planners.
- Each processor works independently of the others, but some synchronization is required to capture the work.
Tokio 0.1 Scheduler
The first working scheduler for Tokio was released in March 2018. This was the first attempt, based on some assumptions that turned out to be wrong.
First, the Tokio 0.1 scheduler suggested that processor threads should be closed if they were idle for a certain amount of time. The scheduler was originally created as a "general purpose" system for the Rust thread pool. At that time, the Tokio runtime was still at an early stage of development. Then the model assumed that I / O tasks would be performed on the same thread as the I / O selector (epoll, kqueue, iocp ...). More computing tasks could be directed to the thread pool. In this context, a flexible setting of the number of active threads is assumed, so it makes more sense to disable idle threads. However, in the scheduler with job capture, the model switched to performing all asynchronous tasks, and in this case it makes sense to always maintain a small number of threads in the active state.
Secondly, a two-way crossbeam was implemented there . This implementation is based on the two-way Chase-Lev line , and it is not suitable for planning independent asynchronous tasks for the reasons described below.
Thirdly, the implementation turned out to be too complicated. This is partly due to the fact that this was my first task scheduler. In addition, I was too impatient when using atomics in branches, where the mutex would just do just fine. An important lesson is that very often it is mutexes that work best.
Finally, there were many minor flaws in the initial implementation. In the early years, implementation details of the asynchronous Rust model evolved significantly, but libraries kept the API stable all the time. This led to the accumulation of some technical debt.
Now Tokio is approaching the first major release - and we can pay all this debt, as well as learn from the experience gained over the years of development. This is an exciting time!
Next Generation Tokio Scheduler
Now it's time to take a closer look at what has changed in the new scheduler.
New task system
First, it’s important to highlight what is not part of Tokio, but is crucial in terms of improving efficiency: this is a new system of tasks in
std
, originally developed by Taylor Kramer . This system provides the hooks that the scheduler must implement to perform asynchronous Rust tasks, and the system is truly superbly designed and implemented. It is much lighter and more flexible than the previous iteration.
The resource
Waker
structure signals that there is a feasible task that should be placed in the scheduler queue. In the new system of tasks, this is a two-pointer structure, whereas before it was much larger. Reducing the size is important to minimize the overhead of copying the
Waker
value in different places, and it takes up less space in the structures, which allows you to squeeze more important data into the cache line. The vtable design made a number of optimizations, which we will discuss later.
Choosing the best queue algorithm
The execution queue is in the center of the scheduler. Therefore, this is the most important component to fix. The original Tokio scheduler used a two-way crossbeam queue : a single-source implementation (producer) and many consumers. A task is placed at one end, and values are retrieved from the other. Most of the time, the thread “pushes” values from the end of the queue, but sometimes other threads intercept work, performing the same operation. The two-way queue is supported by an array and a set of indices tracking the head and tail. When the queue is full, the introduction of it will lead to an increase in storage space. A new, larger array is allocated, and the values are moved to the new storage.
The ability to grow is achieved through complexity and overhead. Push / pop operations should take this growth into account. In addition, freeing the original array is fraught with additional difficulties. In a garbage collection (GC) language, the old array will go out of scope and eventually the GC will clear it. However, Rust ships without a GC. This means that we ourselves are responsible for freeing the array, but threads can try to access memory at the same time. To solve this problem, crossbeam uses an epoch based reclamation strategy. Although it does not require a lot of resources, it adds non-trivial overhead to the main path (hot path). Each operation should now perform atomic RMW (read-modify-write) operations at the entrance and exit of critical sections to signal to other threads that the memory is in use and cannot be cleared.
Because of the overhead for the growth of the execution queue, it makes sense to think: is support for this growth really necessary? This question ultimately prompted me to rewrite the planner. The new strategy is to have a fixed queue size for each process. When the queue is full, instead of increasing the local queue, the task moves to the global queue with several consumers and several producers. Processors will periodically check this global queue, but at a much lower frequency than the local one.
In one of our first experiments, we replaced crossbeam with mpmc . This did not lead to a significant improvement due to the amount of synchronization for push and pop. The key to capturing work is that there is almost no competition in the queues under load, since each processor only accesses its own queue.
At this point, I decided to study the Go source code more carefully - and found that it uses a fixed queue size with one manufacturer and several consumers, with minimal synchronization, which is very impressive. To adapt the algorithm to the Tokio scheduler, I made a few changes. It is noteworthy that the Go implementation uses sequential atomic operations (as I understand it). The Tokio version also reduces the number of some copy operations in rarer code branches.
A queue implementation is a circular buffer that stores values in an array. The head and tail of the queue are tracked by atomic operations with integer values.
struct Queue { /// Concurrently updated by many threads. head: AtomicU32, /// Only updated by producer thread but read by many threads. tail: AtomicU32, /// Masks the head / tail position value to obtain the index in the buffer. mask: usize, /// Stores the tasks. buffer: Box<[MaybeUninit<Task>]>, }
Queuing is performed by a single thread:
loop { let head = self.head.load(Acquire); // safety: this is the **only** thread that updates this cell. let tail = self.tail.unsync_load(); if tail.wrapping_sub(head) < self.buffer.len() as u32 { // Map the position to a slot index. let idx = tail as usize & self.mask; // Don't drop the previous value in `buffer[idx]` because // it is uninitialized memory. self.buffer[idx].as_mut_ptr().write(task); // Make the task available self.tail.store(tail.wrapping_add(1), Release); return; } // The local buffer is full. Push a batch of work to the global // queue. match self.push_overflow(task, head, tail, global) { Ok(_) => return, // Lost the race, try again Err(v) => task = v, } }
Note that in this
push
function, the only atomic operations are loading with
Acquire
ordering and saving with
Release
ordering. There are no RMW operations (
compare_and_swap
,
fetch_and
...) or sequential order as before. This is important because on x86 chips all downloads / saves are already “atomic”. Thus, at the CPU level, this function will not be synchronized . Atomic operations will prevent certain optimizations in the compiler, but that’s all. Most likely, the first
load
operation could be safely performed with
Relaxed
ordering, but the replacement does not carry any noticeable overhead.
When the queue is full,
push_overflow
is
push_overflow
.This function moves half of the tasks from local to global queue. A global queue is an intrusive list protected by a mutex. When moving to the global queue, tasks are first linked together, then a mutex is created, and all tasks are inserted by updating the pointer to the tail of the global queue. This saves a small critical section size.
If you are familiar with the details of atomic memory ordering, you may notice a potential “problem” with the function shown above
push
. The atomic
load
ordering operation is
Acquire
rather weak. It can return obsolete values, i.e., a parallel capture operation may already increase the value
self.head
, but in the stream cache
push
the old value will remain, so it will not notice the capture operation. This is not a problem with the correctness of the algorithm. In the main (fast) way,
push
we only care about whether the local queue is full or not. Since only the current thread can push the queue, an outdated operation
load
will simply make the queue look more full than it actually is. It may incorrectly determine that the queue is full, and cause
push_overflow
, but this function includes a stronger atomic operation. If it
push_overflow
determines that the queue is actually not full, then returns w /
Err
, and the operation
push
starts again. This is another reason why
push_overflow
moves half of the execution queue to the global queue. After this movement, such false positives occur much less frequently.
Local
pop
(from the processor to which the queue belongs) is also implemented simply:
loop { let head = self.head.load(Acquire); // safety: this is the **only** thread that updates this cell. let tail = self.tail.unsync_load(); if head == tail { // queue is empty return None; } // Map the head position to a slot index. let idx = head as usize & self.mask; let task = self.buffer[idx].as_ptr().read(); // Attempt to claim the task read above. let actual = self .head .compare_and_swap(head, head.wrapping_add(1), Release); if actual == head { return Some(task.assume_init()); } }
In this function, one atomic
load
and one
compare_and_swap
s
Release
. The main overhead comes from
compare_and_swap
.
The function
steal
is similar to
pop
, but the
self.tail
atomic load must be transferred from . Also, similarly
push_overflow
, the operation is
steal
trying to pretend to be half the queue instead of a single task. This has a good effect on performance, which we will discuss later.
The last missing part is the analysis of the global queue, which receives tasks that overflow local queues, as well as for transferring tasks to the scheduler from non-processor threads. If the processor is under load, that is, there are tasks in the local queue, the processor will try to pull tasks out of the global queue after about every 60 tasks in the local queue. It also checks the global queue when it is in the “search” state described below.
Streamline Message Templates
Tokio applications typically consist of many small independent tasks. They interact with each other through messages. Such a template is similar to other languages such as Go and Erlang. Given how common the template is, it makes sense for the planner to optimize it.
Suppose tasks A and B are given. Task A is now running and sends a message to task B over the transmission channel. A channel is a resource on which task B is currently blocked, so the action of sending a message will cause task B to transition to an executable state - and it will be placed in the execution queue of the current processor. Then the processor will deduce the next task from the execution queue, execute it, and repeat this cycle until it reaches task B.
The problem is that there may be a significant delay between sending a message and completing task B. In addition, "hot" data, such as a message, is stored in the CPU cache, but by the time the task is completed, it is likely that the corresponding caches will be cleared.
To solve this problem, the new Tokio scheduler implements optimization (as in the Go and Kotlin schedulers). When a task goes into an executable state, it is not placed at the end of the queue, but is stored in a special “next task” slot. The processor always checks this slot before checking the queue. If there is already an old task there when inserting into the slot, it is removed from the slot and moves to the end of the queue. Thus, the task of transmitting a message will be accomplished with virtually no delay.

Throttle capture
In a job capture scheduler, if the processor execution queue is empty, the processor attempts to capture tasks from peer CPUs. First, a random peer-to-peer CPU is selected, if no tasks are found for it, the next one is searched, and so on, until tasks are found.
In practice, several processors often finish processing the execution queue at about the same time. This happens when a job package arrives (for example, when
epoll
polled for readiness of the socket). Processors wake up, receive tasks, start them and complete. This leads to the fact that all processors are simultaneously trying to capture other people's tasks, that is, many threads are trying to access the same queues. There is a conflict. A random choice of starting point helps reduce competition, but the situation is still not very good.
To work around this problem, the new scheduler limits the number of parallel processors that perform capture operations. We call the state of the processor, in which it is trying to capture other people's tasks, “job search”, or “search” for short (more on that later). Such optimization is performed using the atomic value
int
, which the processor increases before starting the search and decreases when exiting the search state. As much as possible in a search state can be half of the total number of processors. That is, the approximate limit is set, and this is normal. We do not need a hard limit on the number of CPUs in the search, just throttling. We sacrifice accuracy for the sake of algorithm efficiency.
After entering the search state, the processor tries to capture the work from peer CPUs and checks the global queue.
Decrease synchronization between threads
Another important part of the scheduler is notifying peer CPUs of new tasks. If the "brother" is asleep, he wakes up and captures tasks. Notifications play another important role. Recall that the queue algorithm uses weak atomic ordering (
Acquire
/
Release
). Due to the atomic allocation of memory, there is no guarantee that the peer processor will ever see tasks in the queue without additional synchronization. Therefore, notifications are responsible for it too. For this reason, notifications become expensive. The goal is to minimize their number so as not to use CPU resources, that is, the processor has tasks, and the "brother" cannot steal them. Excessive number of notifications leads to a thunder herd problem .
The original Tokio planner took a naive approach to notifications. Whenever a new task was placed in the execution queue, the processor received a notification. Whenever the CPU was notified and saw the task after waking up, it notified another CPU. This logic very quickly led to all processors waking up and looking for work (causing a conflict). Often, most processors did not find work and fell asleep again.
The new scheduler greatly improved this pattern, similar to the Go scheduler. Notifications are sent as before, but only if there is no CPU in the search state (see the previous section). When the processor receives a notification, it immediately enters the search state. When the processor in the search state finds new tasks, it first leaves the search state and then notifies the other processor.
This logic limits the speed at which processors wake up. If a whole task package is planned immediately (for example, when
epoll
polled for readiness of the socket), then the first task will lead to the notification of the processor. He is now in a search state. The remaining scheduled tasks in the package will not notify the processor, since there is at least one CPU in the search state. This notified processor will capture half the tasks in the package and, in turn, will notify the other processor. A third processor wakes up, finds the tasks of one of the first two processors and captures half of them. This leads to a smooth increase in the number of working CPUs, as well as fast load balancing.
Reduce memory allocation
The new Tokio scheduler requires only one allocation of memory for each generated task, while the old one required two. Previously, the task structure looked something like this:
struct Task { /// All state needed to manage the task state: TaskState, /// The logic to run is represented as a future trait object. future: Box<dyn Future<Output = ()>>, }
The structure
Task
will also be highlighted in
Box
. For a very long time I wanted to fix this joint (I first tried in 2014). Two things have changed since the old Tokio planner. First, stabilized
std::alloc
. Secondly, the future task system has switched to an explicit vtable strategy . It was these two things that were missing, finally, to get rid of inefficient double memory allocation for each task.
Now the structure
Task
is presented in the following form:
struct Task<T> { header: Header, future: T, trailer: Trailer, }
For tasks necessary and
Header
and
Trailer
, but they are divided between the "hot" data (head) and "cold" (tail), m. E. Approximately between data frequently accessed and those that are rarely used. “Hot” data is placed at the head of the structure and stored as little as possible. When the processor dereferences the task pointer, it immediately loads the cache line (from 64 to 128 bytes). We want this data to be as relevant as possible.
Reduce atomic link counting
The last optimization we discuss in this article is to reduce the number of atomic links. There are many references to the structure of the task, including from the scheduler and from each waker. The general strategy for managing this memory is atomic link counting . This strategy requires an atomic operation every time a link is cloned and every time a link is deleted. When the last link goes out of scope, the memory is freed.
In the old Tokio scheduler, both the scheduler and all wakers contained a link to a task descriptor, approximately:
struct Waker { task: Arc<Task>, } impl Waker { fn wake(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
When the task wakes up, the link is cloned (an atomic increment occurs). Then the link is placed in the execution queue. When the processor receives the task and completes its execution, it discards the link, which leads to atomic reduction. These atomic operations (increment and decrease) add up.
This problem was previously identified by the developers of the task system
std::future
. They noticed that when calling, the
Waker::wake
original link to the link is
waker
often no longer needed. This allows you to reuse the atomic link counter when moving a task to the execution queue. The task system
std::future
now includes two API calls to “wake up”:
-
wake
which takesself
-
wake_by_ref
which takes&self
Such an API construction makes us use it when calling
wake
, avoiding atomic increment. The implementation becomes this:
impl Waker { fn wake(self) { task.scheduler.schedule(self.task); } fn wake_by_ref(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
This avoids the overhead of additional reference counting only if you can take responsibility for awakening. In my experience, instead, it is almost always advisable to wake up with
&self
. Awakening
self
prevents the reuse of waker (useful in cases where the resource sends a lot of values, i.e. channels, sockets, ...). Also in the case it is
self
more difficult to implement thread-safe waking up (we will leave the details for another article).
The new planner solves the problem of “waking through,
self
” avoiding the atomic increment in
wake_by_ref
, which makes it as effective as
wake(self)
. To do this, the scheduler maintains a list of all tasks that are currently active (not yet completed). The list represents the reference counter needed to send the task to the execution queue.
The complexity of this optimization lies in the fact that the scheduler will not remove tasks from its list until it receives guarantees that the task will be placed in the execution queue again. Details of the implementation of this scheme are beyond the scope of this article, but I strongly recommend that you look at the source.
Bold (unsafe) concurrency with Loom
It is very difficult to write the correct, parallel code without locks. It is better to work slowly, but correctly, than quickly, but with glitches, especially if the bugs relate to memory security. The best option, however, should work quickly and without errors. The new scheduler made some rather aggressive optimizations and it avoids most types
std
for the sake of specialization. In general, there are quite a lot of unsafe code in it
unsafe
.
There are several ways to test parallel code. One of them is for users to perform testing and debugging instead of you (an attractive option, that's for sure). Another is to write unit tests that run in a loop and can catch an error. Maybe even use TSAN. Of course, if he finds an error, it cannot be easily reproduced without restarting the test cycle. Also, how long does this cycle take? Ten seconds? Ten minutes? Ten days? Previously, you had to test parallel code in Rust.
We found this situation unacceptable. When we release the code, we want to feel confident (as much as possible), especially in the case of parallel code without locks. Tokio users need reliability.
Therefore, we developed Loom : a tool for permutation testing of parallel code. Tests are written as usual, but
loom
It will run them many times, rearranging all possible variants of execution and behavior that the test may encounter in a streaming environment. It also checks for correct memory access, freeing memory, etc.
As an example, here is the loom test for the new scheduler:
#[test] fn multi_spawn() { loom::model(|| { let pool = ThreadPool::new(); let c1 = Arc::new(AtomicUsize::new(0)); let (tx, rx) = oneshot::channel(); let tx1 = Arc::new(Mutex::new(Some(tx))); // Spawn a task let c2 = c1.clone(); let tx2 = tx1.clone(); pool.spawn(async move { spawn(async move { if 1 == c1.fetch_add(1, Relaxed) { tx1.lock().unwrap().take().unwrap().send(()); } }); }); // Spawn a second task pool.spawn(async move { spawn(async move { if 1 == c2.fetch_add(1, Relaxed) { tx2.lock().unwrap().take().unwrap().send(()); } }); }); rx.recv(); }); }
It looks pretty normal, but a piece of code in a block
loom::model
runs many thousands of times (possibly millions), each time with a slight change in behavior. Each run changes the exact order of the threads. In addition, for each atomic operation, loom tries all the different behaviors allowed in the C ++ 11 memory model. Recall that the atomic load with
Acquire
was rather weak and could return obsolete values. The test
loom
will try all possible values that can be loaded.
loom
became an invaluable tool in developing a new planner. He caught more than ten bugs that passed all unit tests, manual testing and load testing.
An astute reader may doubt that loom checks “all possible permutations” and he will be right. Naive permutations will lead to a combinatorial explosion. Any non-trivial test will never end. This problem has been studied for many years, and a number of algorithms have been developed to prevent a combinatorial explosion. Loom basic algorithm based on dynamic reduction with partial ordering (dynamic partial-order reduction). This algorithm eliminates permutations leading to the same result. But the state space can still grow to such a size that it will not be processed in a reasonable amount of time (several minutes). Loom allows you to further limit it using dynamic reduction with partial ordering.
In general, thanks to extensive testing with Loom, I am now much more confident in the correctness of the scheduler.
results
So, we looked at what schedulers are and how the new Tokio scheduler achieved a huge performance boost ... but what kind of growth? Given that the new scheduler is only developed, in the real world it has not yet been tested in full. Here is what we know.
Firstly, the new scheduler is much faster in micro benchmarks:
Old planner
test chained_spawn ... bench: 2,019,796 ns / iter (+/- 302,168) test ping_pong ... bench: 1,279,948 ns / iter (+/- 154,365) test spawn_many ... bench: 10,283,608 ns / iter (+/- 1,284,275) test yield_many ... bench: 21,450,748 ns / iter (+/- 1,201,337)
New planner
test chained_spawn ... bench: 168,854 ns / iter (+/- 8,339) test ping_pong ... bench: 562,659 ns / iter (+/- 34,410) test spawn_many ... bench: 7,320,737 ns / iter (+/- 264,620) test yield_many ... bench: 14,638,563 ns / iter (+/- 1,573,678)
This benchmark includes the following:
-
chained_spawn
recursively spawn new tasks, i.e., generate a task that generates another task, which also generates a task, etc.
-
ping_pong
selects a channeloneshot
and spawns a task that sends a message on that channel. The original task is waiting for a message. This is the test closest to the “real world”.
-
spawn_many
Checks the implementation of tasks in the scheduler, i.e., generates tasks from outside its context.
-
yield_many
checks for self-awakening tasks.
The difference in benchmarks is very impressive. But how will this be reflected in the "real world"? It's hard to say for sure, but I tried to run the Hyper benchmarks .
Here is the simplest Hyper server, whose performance is measured using
wrk -t1 -c50 -d10
:
Old planner
Running 10s test @ http://127.0.0.1{000
1 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 371.53us 99.05us 1.97ms 60.53%
Req / Sec 114.61k 8.45k 133.85k 67.00%
1139307 requests in 10.00s, 95.61MB read
Requests / sec: 113923.19
Transfer / sec: 9.56MB
New planner
Running 10s test @ http://127.0.0.1{000
1 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 275.05us 69.81us 1.09ms 73.57%
Req / Sec 153.17k 10.68k 171.51k 71.00%
1522671 requests in 10.00s, 127.79MB read
Requests / sec: 152258.70
Transfer / sec: 12.78MB
We see an increase of 34% in requests per second just after the change of scheduler! The first time I saw this, I was very happy, because I expected an increase of a maximum of 5-10%. But then I felt sad, because this result also showed that the old Tokio scheduler is not so good. Then I remembered that Hyper is already a leader in TechEmpower ratings . It is interesting to see how the new planner will affect ratings.
Tonic , the gRPC client and server, with the new scheduler accelerated by about 10%, which is pretty impressive considering that Tonic is not yet fully optimized.
Conclusion
I am really very happy to finally complete this project after several months of work. This is a major improvement to Rust's asynchronous I / O. I am very pleased with the improvements made. There is still much room for optimization in Tokio code, so we are not done with the performance improvement yet.
I hope that the material in the article will be useful for colleagues who try to write their task scheduler.