“Automation of infrastructure. Why are we doing this? ”(Denis Yakovlev)
I propose to get acquainted with the decoding of the report of Denis Yakovlev "Automation of infrastructure. Why are we doing this?"
The 2016 report itself. The report was specially decrypted for those who create virtual machines with their hands.
Report on how we at 2GIS automated the work with infrastructure.
“You need to run as fast just to stay in place, but to get somewhere, you must run at least twice as fast” (Alice in Wonderland).
What does this phrase mean to us? In a highly competitive environment, companies should strive to deliver their products to users as quickly as possible. Decreasing the time to market parameter is a multi-level task. To solve it, both development processes and tools must be changed. An important foundation for the entire development process is infrastructure. The larger the infrastructure, the more problems there are with it, use cases, etc. If all operations with it are not automated, then the number of problems increases. One of them is the time that a developer spends on infrastructure issues instead of writing business logic.
Let's talk about:
- What infrastructure problems faced the teams;
- How the development and testing processes suffered from this;
- How we implemented OpenStack;
- What are our scenarios for using OpenStack;
- How automation received an additional impetus in development and new internal products began to appear;
- What aspects we have left are not automated.
About myself. Company 2GIS. I have been working in the company for two years.

Infrastructure and Operations Team. We mainly support the internal infrastructure of the Web department. Recently, other internal product teams have joined us. We are also responsible for the operation of the company's web products in production. And we are also researching and developing new tools to make our lives easier and to improve the lives of our beloved developers. There are only 9 of us.

First we understand the infrastructure. Why are we talking about her? What it is? When do we start talking about her?

From the first moments of work on the product and some project, we have a question - where will we deploy? where to check the results? where to test and so on.

Immediately the first answer is locally. Locally because it’s very simple. Developed on his laptop, launched, checked - everything is fine. You sit thinking - why check besides your laptop? Everything works.

And if we have one operating system on the laptop, and another is spinning in production? Or should our product support several operating systems?

The case is not covered. That is, different operating systems.

If we have the opportunity and we make a strong-willed decision - we have Linux everywhere. For example, some Ubuntu. The rest is all from the evil one. It seems to us that we have solved all our problems.

But simply matching the operating system is not enough. We need packages of a certain version.

we think how to solve this problem. And remember - we have isolation. Very high stuff. Thank God there are so many products on the market. We take virtualbox. Create a virtual machine. We roll our product. We make snapshots. We got the environment.

We are developing. Our product is getting harder. This is no longer just a php database application. The application has grown into a distributed system. We have other products coming up.

The company is developing. And we have new cases of use. All these products want to integrate, to be able to work together. We have features that go through several products. We are constantly asked to show what you have developed. Let us see it somewhere. We no longer have enough resources for manual testing. We recall that there is Continuous integration, autotests. To do this, you need additional software. Us local environment, even with all the isolation, is no longer enough. This is where the infrastructure comes in. We need a place where we can deploy our products and show someone the results. We must somehow manage all this and it should be convenient.

Let's go look at our company 2GIS.

This is a guide and maps. You can look at the city map, search for organizations.

We have: web products, mobile, desktop application. Different teams of the order of thirty-five, of different sizes.

What problems did we have with the infrastructure? At the end of 2013, we used proxmox. This is a virtualization management system. Using it, you can create either KVM virtual machines or OpenVZ containers. But all this is done by hand through interfaces. For full functioning, you still need to go into the virtual machine and configure the network, dns.

Therefore, for some time, the flow of our development looked as follows. As a developer, I’m looking for ticket admins. Admins, when they have time, create a virtual machine. They give out an IP address, login, password. But if I need to redeploy this virtual machine, then I go again to admins who already look at me suspiciously. They say - the guy is as much as possible?

There was no separation of projects. There was a set of virtual machines on several servers, where admins created everything with their hands. There was a high probability of human error. You could confuse the IP address or delete the wrong virtual machine. A very, very many such cases. And the responsibility for the virtual machine is incomprehensible. Developers are not responsible, admins are not soared either. It is not clear that someone else needs a virtual machine or everyone has long forgotten about it and do not know about it.

Plus there is a weak API. Plugins are either paid or perl.

But besides the problems we had something else useful. We had our own iron, on which all this was spinning. Our system administrators are great fellows, they know how to cook this iron, take care of it, and buy it correctly. And they had some experience with virtualization.

We began to think: what solution would suit us? What should our infrastructure look like so as not to interfere with the development process, but rather help?
We got the following list of requirements as a result of the study:
Effective utilization of iron. We do not want to have orphaned virtual machines. We do not want to just warm the air in the data center.
We want to have team resources so that the team takes responsibility for the resources that it uses. And she was attentive to them.
We want the solution to be modular, to dial only the services we need. And in case of need, with further development, be able to expand.
The solution should be easily finalized. If new requirements appear, we could refine the solution to our specific needs.
We need not only a user interface, we need an API to write our bindings and manage the infrastructure.
We want to isolate the teams, and especially the load testing team. I wanted her to not disturb the rest at all.

What were our options?
We looked at the public cloud: AWS and more. The option is attractive in that they take on almost all issues related to infrastructure. It was possible to take and pay a lot of money to these famous companies, but we were constrained by the disgusting situation with the dollar (or sanctions). I didn’t really want to get any vendor-lock. The third option, in which we looked at what we have on the open source market? What solutions do we offer? We have our own hardware, it remains to choose something from this many open source applications.

So, in the end, our research and experiments led us to a software called OpenStack. Softinke of course it sounds too rude.

OpenStack is a full-fledged software, in fact, it is a set of services for building a public or private cloud. OpenStack is an open source solution. All services are written in python. Each service is responsible for its task, has its own API.
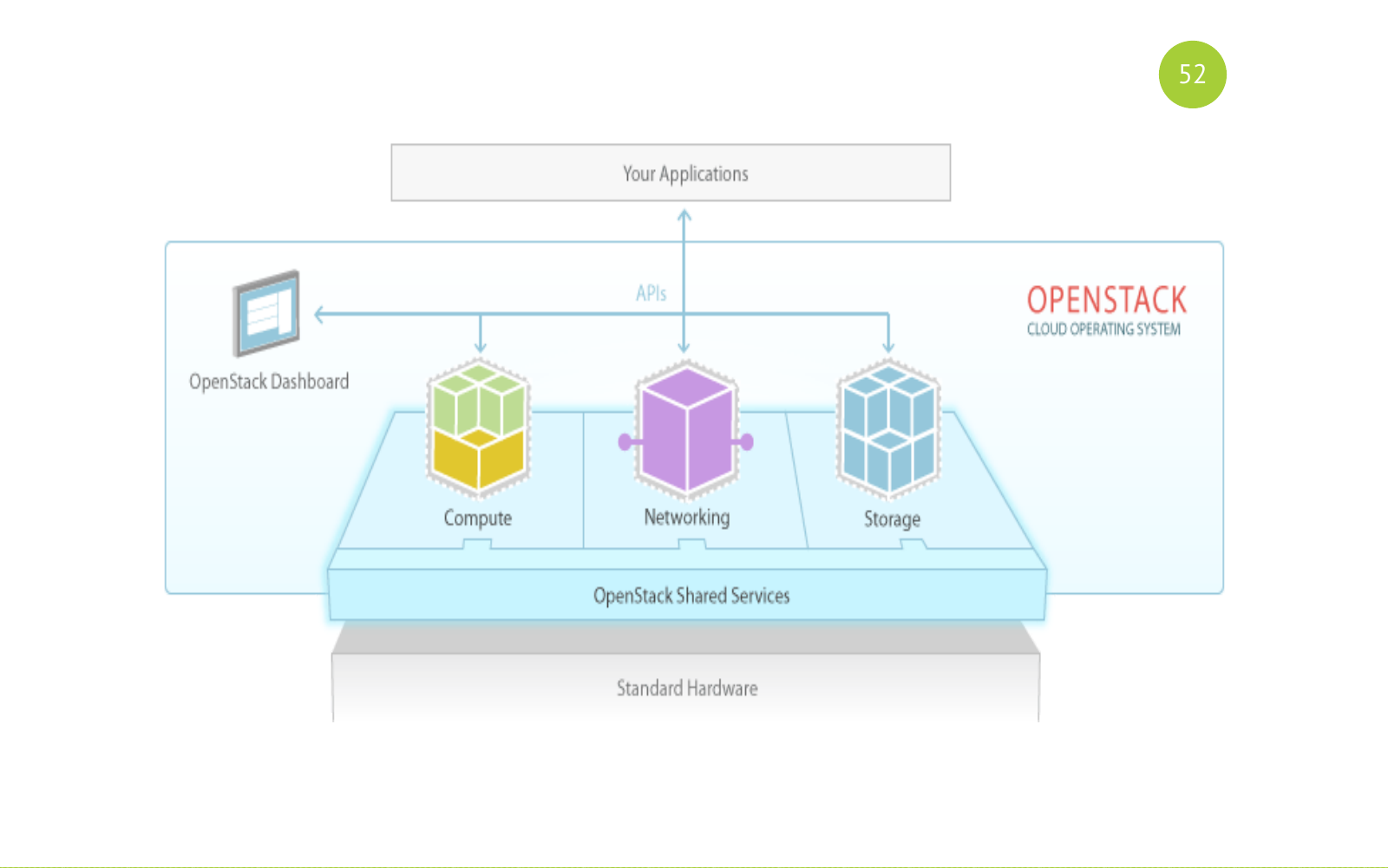
And it looks like this. Remember this picture. Then we will return to her. There are shared (general) services. There are services for the purpose: Compute, Networking, Storage. And our application or user works with these services.

Open source solution. The release takes place every six months. The release includes basic components. Each release includes new components that initially appear from in this incubator. They spend some time there, fix bugs there, stabilize and so on. And at some point, the community decides that this component should be included in the basic components from the next release. There are also many different mailings, meetings, conferences. The biggest conference is the OpenStack Summit. Held every year. And at the last OpenStack summit there were about four or five thousand participants. Such a big event. Lots of reports.

Many people are contributing to this decision. Here I gave only a list of such tops. This list is sufficient to understand how serious the project is and which companies and how much resources they invest in it.

How we solved our infrastructure problems.
- One of the components of OpenStack is the scheduler, which selects the host on which the virtual machine will be created.
- The team now has its own resources. This is the amount of CPU, memory and more. We got rid of this scenario for creating a virtual on tiket (application).
- OpenStack is a set of services that is. We took only the basic kit that provided our needs.
- Since OpenStack is open-source, it is possible to modify it.
- Each service has an API. There are python builds. That is, it’s quite simple to interact with each service and write your own bindings.
- Insulation. We can isolate teams to us for projects, for aggragation zones, for networks and more.

Team developers received infrastructure as service. What does it look like.

There are two concepts of stack and template. Stack is a set of cloud resources: virtual machines, network, dns records and more. A template is a description of this stack. In the case of OpenStack, this is a regular YAML file. Here is part of the file. It says that there is such an entity as a server with an internal type OS Nova server. For its normal operation, you need an IP address and dns record. Here, the name parameters are accepted as input, flavor is a description of the resources that this server needs. Image operating system. key_name - which public key to put when deploying the server. We have all of these templates in the repository each have in git. Everyone has access. Everyone can send a pull request.

And the creation of Stack is as follows. Heat is the OpenStack component responsible for orchestration. We say this in this context. This is a great utility that we installed for ourselves. We say dear heat, create us a Stack with that name, here is a description of the resources we need to create this Stack. And here is the input that our template requires, which describes our stack. We load it in heat. He rustles there for a while, creates all the necessary resources for us inside himself. And also we in this template here we can specify output. When heat created Stack, it can output information: ip-address, access and the rest that we ask. Further we can already apply this information for further automation.

In order for you not to think that OpenStack is simple and cheap, I’ll tell you what hardware OpenStack works for. The control panel spins on 3 infra-nodes. These are iron servers with such resources. This is the recommended configuration for failover.

We also have two KVM network nodes that serve our network.

Team resources we spin on 8 compute-nodes. They are divided into 3 aggregation zones. One compute node is allocated per zone for load testing. There, servers are created only from the load testing team. In order not to interfere with the rest. We have an aggregation zone for our internal GUI testing automation project. He has certain requirements. It is located in a separate aggregation zone. All the rest of our development environments, servers, test environments are spinning in the third large aggregation zone. It takes us 6 compute nodes to it.

We spin about 350 virtual machines for all teams.

What did we understand when we already went some way. To deploy and to support this software, you need a team. Team depending on your resources.

Teams must have certain competencies.
First of all, this is naturally Ansbile. OpenStack deploy is written in Ansbile. There is an OpenStack-Ansible project. If you want to add OpenStack-Ansible to your needs, you need people who will do this to own Ansbile.
Virtualization Experience. You need to be able to cook virtualization, you need to tune. Understand how it works.
The same network.
The same goes for backend services that OpenStack uses for its work. This database is MySQL Galera and RabbitMQ as a queue.
Understanding how DNS works. How to configure it.
OpenStack is written in python. You must be able to read the code. Ideally, you need to be able to patch. Search community fixes. Be able to debut the code. This is all very helpful. If a team has such an approach, knows how to use an approach like Infrastructure as code, such as ansible, for example, stores all changes in the code, then they will not have problems that arise when configuring hands.
Continues integrations. The OpenStack services suite includes a service such as tempest . In it, all tests are written on all components. If we change the configuration, run a separate diploma in the All-In-One installation and run tempest - we look to see if something has fallen off with us. CI is configured and the team must understand this and must be able to configure all this.
Because everything looks simple and attractive given.

But when you start to delve into it more, you understand that in fact everything looks like this. This may be a surprise to someone.

The introduction of OpenStack is not only a technical solution. In addition, you need to be able to sell, to be able to explain to the teams the new paradigm of how they now work, what benefits it brings. How to work with it in order to get a profit. We wrote a lot of documentation. The documentation is of the form quickstart (quick start), first steps (first steps). That is, what needs to be done to quickly make your life easier and not to spend a lot of time on it.
We conducted TechTalk, we talked, made topics, showed, talk, now see now you can get your product as follows. literally here we are writing a template, launching. Everything is quite simple. Now you don’t have to go to the admins and ask them for something there.
In especially such difficult cases when the project is complex, it has a lot of cases, we came to teams, worked directly with teams. That is, they somehow tried to help them in the automation of processes. Set up all the teams. Wound up some bugs. They understood that we didn’t configure something wrong there. In general, tight work with teams.

We received a quick deployment of products. Previously, in order to receive products, it was necessary to perform many manual actions, interact with many people. Now we get the creation of Envinronment (Environment, server) by button. And if deploy is written and works for the project, we get deploy by the button or new Envinronment (Environment, servers) with the product installed.
The lack of a normal infrastructure was a blocker for some teams in terms of implementing the CI process within the team. We solved infrastructure problems, the teams raised on the CI server, configured the pipeline, virtual machines are created in the pipeline. In general, they gave impetus to the development of these processes.
They also helped some internal products that use the infrastructure to automate testing. VM Master is a product that tests our online. He needs to raise a lot of virtual machines in order to access the site from different browsers, go through some steps to understand that online works in all known browsers. That is, they helped him a lot.
A nice bonus is that they unloaded the admins (themselves). Because at some point, the activity of creating a virtual machine began to take up space time. And everyone began to get nervous. Now we are doing interesting things, complex products. We got rid of the routine task.

Questions?
Question: How long did it take to deploy OpenStack?
Answer: The question is complicated because we had a process that can accommodate a comedy series. He has a high entry threshold. We comprehended our entire infrastructure, looked for a solution - it took three months. Then in a month we rolled out the first installation somewhere. We added a couple of projects there. They lived there. Then the human factor happened - they shot the head of this installation. We realized that the lack of fault tolerance is bad. Then we waited for the iron.
Question: Do you use paid support?
Answer: no, we don’t use it.
Question: What version of OpenStack are you using?
Answer: The OpenStack version is called words. First was Juno, then we upgraded to Liberty.
Question: Are virtual machines created in pipeline Continuous integration?
Answer: Building in Jenkins can cause Heat and create a virtual machine.
Question: Have you encountered problems with resource sharing? Roughly speaking, 2 virtual machines are on the same physical server. One of them starts to load a disk, for example, a database. If faced, how did you decide?
Answer: We did not encounter problems with resource sharing. Each other's products do not particularly interfere. We laid out the scripts. If you need to run a heavy scenario, run load tests, then you need to go to the load testing team and they run load testing.
Question: load testing was immediately taken to a separate aggregation zone or ran into some problems?
Answer: Employees came and said that OpenStack was slow. We begin to understand. It turns out we have a load testing team. And the load testing team was taken to a separate aggregation zone.
Question: We have a large flow of tests. And the tests are in line and are waiting for their resources. Will OpenStack Help as a Resource Manager for AutoTests?
Answer: We do not have such a case. OpenStack has a scheduler. He manages resources.
Question: How complicated is the move from the old infrastructure to OpenStack?
Answer: It was a very fun process. Cleaned up unnecessary virtual machines in proxmox. Moved virtual machines to OpenStack.
Question: What is DevOps?
Answer: DevOps is an ideology aimed at delivering products to customers as quickly as possible. All processes in the company, tools, thinking and interaction between teams should be built around this goal.
PS In 2019, it is better to use Terraform instead of heat to automatically create resources in OpenStack.
All Articles