Providing Storage Failover

Hello! Recently, an open webinar “Providing fault-tolerant storage” was held . It examined what problems arise in the design of architectures, why server failure is not an excuse for a server crashing and how to reduce downtime to a minimum. The webinar was conducted by Ivan Remen , head of server development at Citimobil and a teacher in the course “High Load Architect” .
Why bother with storage resiliency?
Thinking about the fault tolerance of scalable storage and understanding the basic caching problems should be at the startup stage . It is clear that when you write a startup, at the very beginning you make the minimum version of the product. But the more you grow, the faster you run into productivity, which can lead to a complete stop of the business. And if you get money from investors, then, of course, they will also require constant growth and new business features. To find the right balance, you need to choose between speed and quality. At the same time, you cannot sacrifice either one or the other, and if you sacrifice, then consciously and within certain limits. However, there are no universal recipes, as well as ideal solutions.
We rest against the base for reading
This is the first scenario. Imagine that we have 1 server with a processor or hard drive load of 99%. Wherein:
- 90% of requests are read;
- 10% of requests are a record.
The best solution in this situation is to think about replicas. Why? This is the cheapest and easiest solution.
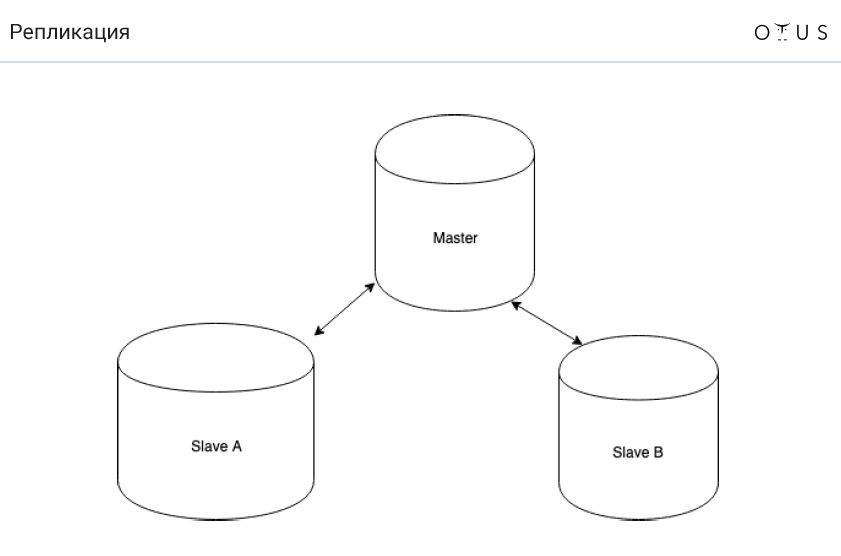
Replication is classified:
1. By synchronization:
- synchronous;
- asynchronous;
- semi-synchronous.
2. According to portable data:
- logical (row-based, statement-based, mixed);
- physical.
3. By the number of nodes per record:
- master / slave;
- master / master.
4. By initiator:
- pull
- push
And now the task is about a bucket of water . Imagine that we have MySQL and asynchronous master-slave replication. Cleaning is going on in the DC, as a result of which the cleaner stumbles and pours a bucket of water on the server with the master base. Automation successfully switches one of the latest slave to master mode. And everything continues to work. Where is the catch?
The answer is simple - we lose transactions that we did not manage to replicate. Consequently, property D of the ACID is violated.
Now let's talk about how asynchronous replication (MySQL) works:
- recording a transaction to the storage engine (InnoDB);
- recording a transaction in a binary log;
- transaction completion in the storage engine;
- return confirmation to the customer;
- transferring part of the log to the replica;
- execution of a transaction on a replica (p. 1-3).
And now the question is, what needs to be changed in the above paragraphs so that we never end up with replication?
And only two points need to be interchanged: 4th and 5th (“transferring part of the log to the replica” and “returning confirmation to the client”). Thus, if the master node flies out, we will always have a transaction log somewhere (item 2). And if the transaction was recorded in the binary log, then the transaction will also happen sometime.
As a result, we get semi-synchronous replication (MySQL), which works as follows:
- recording a transaction to the storage engine (InnoDB);
- recording a transaction in a binary log;
- transaction completion in the storage engine;
- transferring part of the log to the replica;
- return confirmation to the customer;
- execution of a transaction on a replica (p. 1-3).
Sync vs semi-sync and async vs semi-sync
For some reason, in Russia, most people have not heard about semi-synchronous replication. By the way, it is well implemented in PostgreSQL and not very in MySQL. Read more about this here , but thesis can be formulated as follows:
- semi-synchronous replication is still behind (but not so much) as asynchronous;
- we do not lose transactions;
- it is enough to bring the data to only one slave.
By the way, semi-synchronous replication is used on Facebook.
We rest against the record base
Let's talk about a diametrically opposite problem when we have:
- 90% of requests - record;
- 10% of requests are read;
- 1 server;
- load - 99% (processor or hard disk).
Well-known sharding comes to the rescue here. But now let's talk about something else:

Very often in such cases, they begin to use master-master. However, it does not help in this situation . Why? Everything is simple: there are no less entries on the server. After all, replication implies that there is data on all nodes. With statement-based replication, in effect, SQL will run on ALL nodes. C row-based is a little easier, but still expensive. And also master-master has problems with conflicts.
In fact, it makes sense to use master-master in the following situations:
- write-through fault tolerance (the idea is that you always write to only one master). You can implement using Virtual IP address ;
- geo-distributed systems.
However, remember that master-master replication is always difficult. And often master-master brings more problems than it solves.
Sharding
We have already mentioned sharding. In short, sharding is a sure-fire way to scale a record. The idea is that we distribute data across independent (but not always) servers. Each shard can replicate independently.
The first rule of sharding is that data that is used together must be in the same shard. The
sharding_key -> shard_id
formula works
sharding_key -> shard_id
. Accordingly,
sharding_key
for the data used together must match. The first difficulty is that if you choose the wrong
sharding_key
, then it will be very difficult for you to re-shuffle everything. Secondly, if you have some kind of
sharding_key
, some requests will be very difficult to execute. For example, you cannot find the average value.
To demonstrate this, let's imagine that we have two shards with three values in each: (1; 2; 3) (0; 0; 500). The average value will be equal to (1 + 2 + 3 + 500) / 6 = 84.33333.
Now imagine that we have two independent servers. And recalculate the average value separately for each shard. On the first of them we get 2, on the second - 166.66667. And even if we then average these values, we will still get a number that will differ from the correct one: (2 + 166.66667) / 2 = 86.33334.
That is, the average of the means is not equal to the average of everything:
avg(a, b, c, d) != avg(avg(a, b) + (avg(c, d))
Simple math, but it's important to remember.
Sharding task
Let's say we have a dialogue system in a social network. There can only be 2 people in a dialogue. All messages are in one table, in which there is:
- Message ID
- Sender ID
- Recipient ID
- Message text;
- date the message was sent;
- some flags.
What sharding key should be chosen based on the fact that we have the first sharding rule described above?
There are several options for solving this classic problem:
- crc32 (id_src // id_dst);
- crc32 (1 // 2)! = crc32 (2 // 1);
- crc32 (from + to)% n;
- crc32 (min (from, to). max (from, to))% n.
Caches
And a few words about caches. We can say that caches are an antipattern , although one can argue with this statement (many people like to use caches). But by and large, caches are only needed to increase the response rate. And they can not be set to hold the load.
The conclusion is simple - we should live quietly without caches. The only reason they may be needed is for exactly the same reason why they are needed in the processor: to increase the response speed. If the database does not withstand the load as a result of the cache disappearing, this is bad. This is an extremely unsuccessful architectural pattern, so this should not be. And whatever resources you have, someday your cache will surely fall down, no matter what you do.
The cache problems are thesis:
- start with a cold cache;
- cache invalidation issue;
- cache consistency.
If you still use caches, consistent hashing will help you. This is a way to create distributed hash tables, in which the failure of one or more storage servers does not lead to the need for a complete relocation of all stored keys and values. However, you can read more about this here .

Well, thanks for watching! In order not to miss anything from the last lecture, it is better to watch the entire webinar .
All Articles