Parsing: OOM on Kubernetes

Problems in the work environment are always a disaster. It happens when you go home, and the reason always seems stupid. Recently, we have run out of memory on nodes in the Kubernetes cluster, although the node immediately recovered, without visible interruptions. Today we will talk about this case, about what damage we suffered and how we intend to avoid a similar problem in the future.
Case one
Saturday, June 15, 2019 5:12 p.m.
Blue Matador (yes, we monitor ourselves!) Generates an alert: an event on one of the nodes in the Kubernetes production cluster - SystemOOM.
17:16
Blue Matador generates a warning: EBS Burst Balance is low on the root volume of the node — the one where the SystemOOM event took place. Although a warning about the Burst Balance came after a notification about SystemOOM, actual CloudWatch data shows that the Burst Balance has reached a minimum level at 17:02. The reason for the delay is that EBS metrics are constantly 10-15 minutes behind, and our system does not catch all events in real time.
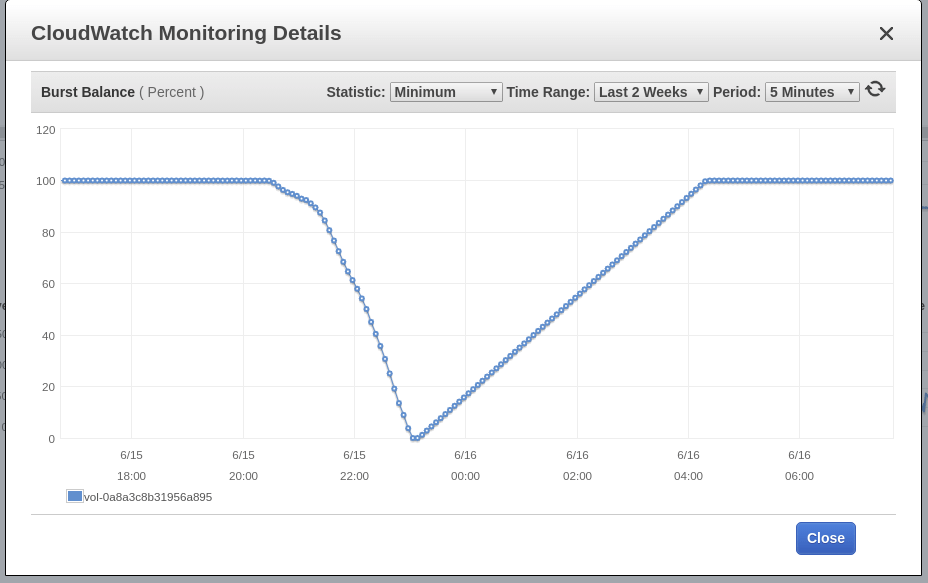
17:18
Right now I saw the alert and warning. I quickly run kubectl get pods to see what damage we suffered, and I am surprised to find that the pods in the application died exactly 0. I perform kubectl top nodes , but this check also shows that the suspected node has a memory problem; True, it has already recovered and uses approximately 60% of its memory. It’s 5 p.m., and the craft beer is already warming up. After making sure that the node was operational and not a single pod was damaged, I decided that an accident had occurred. If anything, I'll figure it out on Monday.
Here is our correspondence with the service station in Slack that evening:

Case two
Saturday, June 16, 2019 6:02 p.m.
Blue Matador generates an alert: the event is already on another node, also SystemOOM. It must have been that the service station at that moment was just looking at the screen of the smartphone, because it wrote to me and made me immediately take up the event, I myself cannot turn on the computer (is it time to reinstall Windows again?). And again, everything seems normal. Not a single pod is killed, and the node hardly consumes 70% of the memory.
18:06
Blue Matador generates a warning again: EBS Burst Balance. The second time in a day, which means that I can’t release this problem on the brakes. With CloudWatch unchanged, Burst Balance deviated from the norm more than 2 hours before the problem was identified.
18:11
I go to Datalog and look at the data on memory consumption. I see that right before the SystemOOM event, the suspected node really took a lot of memory. The trail leads to our fluentd-sumologic pods.

The abrupt deviation in memory consumption is clearly visible, at about the same time that SystemOOM events occurred. My conclusion: it was these pods that took all the memory, and when SystemOOM happened, Kubernetes realized that these pods could be killed and restarted to return the necessary memory without affecting my other pods. Well done, Kubernetes!
So why didn’t I see this on Saturday, when I figured out which pods restarted? The fact is that I launch fluentd-sumologic pods in a separate namespace and in a hurry I just did not think of looking into it.
Conclusion 1: When looking for restarted pods, check all the namespaces.
Having received this data, I calculated that in the next day the memory on other nodes would not end, however I went ahead and restarted all sumologic pods so that they started working with low memory consumption. The next morning, I plan to whip up how to integrate work on the problem into a plan for the week and not load Sunday evening too much.
23:00
I watched the next series of "Black Mirror" (by the way, I liked Miley) and decided to look at how the cluster was doing. Memory consumption is normal, so feel free to leave it at night.
Fix
On Monday, I made time for this problem. It doesn’t hurt to hunt around with her every night. What I know at the moment:
- Fluentd-sumologic containers gobbled up a ton of memory;
- The SystemOOM event is preceded by high disk activity, but I don’t know which one.
At first I thought that fluentd-sumologic containers are accepted to eat memory at a sudden influx of logs. However, after checking Sumologic, I saw that the logs were used stably, and at the same time when there were problems, there was no increase in these logs.
Googling a bit, I found this task on github , which suggests adjusting some Ruby settings - to reduce memory consumption. I decided to give it a try, add an environment variable to the pod specification and run it:
env: - name: RUBY_GC_HEAP_OLDOBJECT_LIMIT_FACTOR value: "0.9"
Looking through the fluentd-sumologic manifest, I noticed that I did not define resource requests and restrictions. I begin to suspect that the fix RUBY_GCP_HEAP will do some kind of miracle, so now it makes sense to set restrictions on memory consumption. Even if I don’t fix the memory problems, it’s possible to at least limit its consumption to this set of pods. Using kubectl top pods | grep fluentd-sumologic , I already know how many resources to request:
resources: requests: memory: "128Mi" cpu: "100m" limits: memory: "1024Mi" cpu: "250m"
Conclusion 2: Set resource limits, especially for third-party applications.
Execution verification
After a few days, I confirm that the above method works. Memory consumption was stable, and - no problems with any component of Kubernetes, EC2 and EBS. Now it’s clear how important it is to define resource requests and restrictions for all the pods I run, and here’s what needs to be done: apply a combination of default resource limits and resource quotas .
The last unsolved mystery is EBS Burst Balance, which coincided with the SystemOOM event. I know that when there is little memory, the OS uses the swap space so as not to be left completely without memory. But I was not born yesterday and I am aware that Kubernetes will not even start on servers where the page file is activated. Just wanting to make sure, I climbed into my nodes via SSH - to check if the page file was activated; I used both free memory and the one in the swap area. The file was not activated.
And since swapping is not at work, I have more clues as to what caused the growth of I / O flows, which is why the node almost ran out of memory, no. Actually, I have a hunch: the fluentd-sumologic pod itself was writing a ton of log messages at this time, possibly even a log message related to setting up Ruby GC. It is also possible that there are other sources of Kubernetes or journald messages that become excessively productive when the memory runs out, and I eliminated them while setting up fluentd. Unfortunately, I no longer have access to the log files recorded immediately before the malfunction, and now I can’t dig deeper.
Conclusion 3: While there is an opportunity, dig deeper when analyzing the root causes, whatever the problem.
Conclusion
And although I did not get to the root of the causes, I am sure they are not needed to prevent the same malfunctions in the future. Time is money, but I have been busy for too long, and after that I also wrote this post for you. And since we use Blue Matador , such faults are dealt with in great detail, so I allow myself to release something on the brakes, without being distracted from the main project.
All Articles