What I learned by testing 200,000 lines of infrastructure code
The IaC (Infrastructure as Code) approach consists not only of the code that is stored in the repository, but also of the people and processes that surround this code. Is it possible to reuse approaches from software development to management and description of infrastructure? It will not be superfluous to keep this idea in mind while you read the article.
This is a transcript of my performance at DevopsConf 2019-05-28 .
Infrastructure as bash history

Suppose you come to a new project, and they say to you: "we have Infrastructure as Code ." In reality, it turns out that Infrastructure as bash history or for example Documentation as bash history . This is a very real situation, for example, a similar case was described by Denis Lysenko in his speech How to replace the entire infrastructure and start to sleep peacefully , he told how from bash history they got a slender infrastructure on the project.
With some desire, we can say that Infrastructure as bash history is like code:
- reproducibility : you can take bash history, execute commands from there, perhaps, by the way, you will get a working configuration at the output.
- versioning : you know who came in and what did, again, not the fact that this will lead you to a working configuration on the output.
- history : the history of who did what. only you can’t use it if you lose the server.
What to do?
Infrastructure as code
Even such a strange case as Infrastructure as bash history can be pulled by the ears to Infrastructure as Code , but when we want to do something more complicated than the good old LAMP server, we will come to the conclusion that this code needs to be modified, modified, modified somehow . Further, we would like to consider the parallels between Infrastructure as Code and software development.
DRY
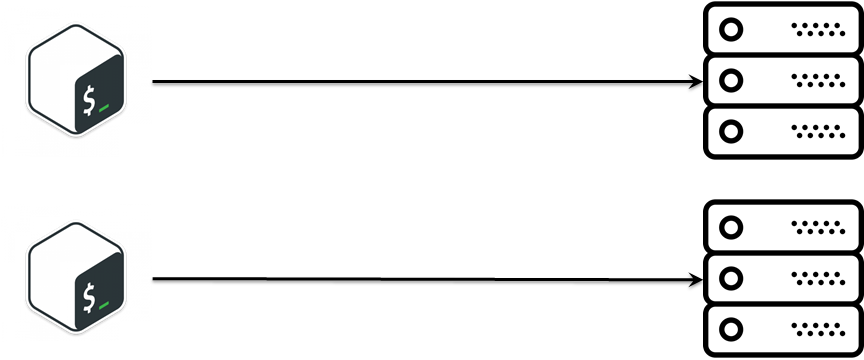
On the project for the development of storage systems, there was a sub-task to periodically configure SDS : we are releasing a new release - it needs to be rolled out for further testing. The task is extremely simple:
- come here by ssh and execute the command.
- copy the file there.
- here is a tweak to the config.
- start the service there
- ...
- PROFIT!
Bash is more than enough for the logic described, especially in the early stages of a project when it is just starting. It's not bad that you use bash , but over time you are prompted to deploy something similar, but slightly different. The first thing that comes to mind: copy-paste. And now we have two very similar scripts that do almost the same thing. Over time, the number of scripts has grown, and we are faced with the fact that there is a certain business logic for deploying the installation, which must be synchronized between different scripts, it is quite difficult.
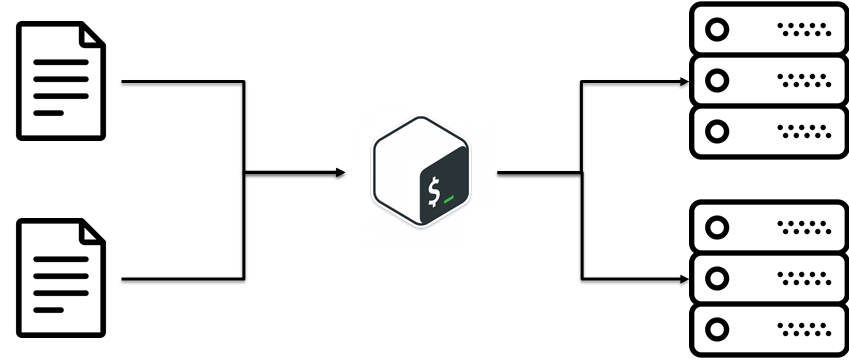
It turns out there is such a practice DRY (Do not Repeat Yourself). The idea is to reuse existing code. It sounds simple, but did not come to this right away. In our case, it was a banal idea: to separate configs from scripts. Those. business logic how the installation is deployed separately, configs separately.
SOLID for CFM

Over time, the project grew and a natural extension was the emergence of Ansible. The main reason for his appearance is the presence of expertise in the team and that bash is not intended for complex logic. Ansible also began to contain complex logic. In order that complex logic would not turn into chaos, there are principles of organizing SOLID code in software development. For example, Grigory Petrov in the report “Why does IT need a personal brand” raised the question that a person is so designed that it’s easier to operate with some social entities, in software development these are objects. If you combine these two ideas and continue to develop them, you will notice that in the description of the infrastructure you can also use SOLID to make it easier to maintain and modify this logic in the future.
The Single Responsibility Principle

Each class performs only one task.
No need to mix code and make monolithic divine pasta monsters. The infrastructure should consist of simple bricks. It turns out that if you split Ansible playbook into small pieces, read Ansible roles, then they are easier to maintain.
The open closed principles
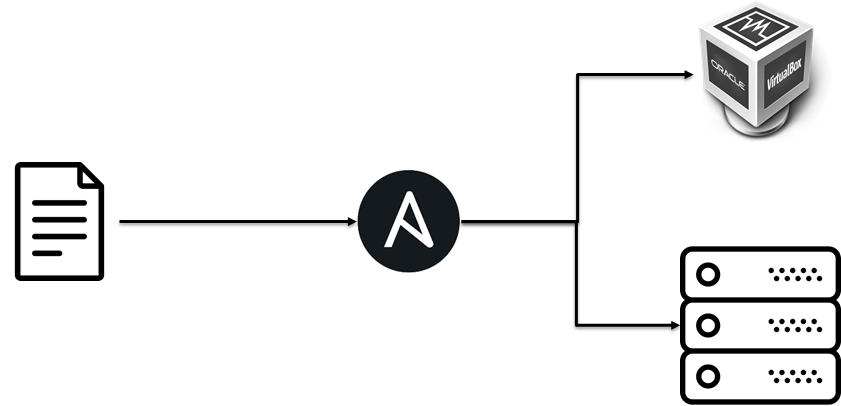
The principle of openness / closure.
- Open for expansion: means that the behavior of an entity can be expanded by creating new types of entities.
- Closed for change: as a result of expanding the behavior of an entity, no changes should be made to the code that uses these entities.
Initially, we deployed the test infrastructure on virtual machines, but due to the fact that the business deployment logic was separate from the implementation, we easily added a rollout to baremetall.
The Liskov Substitution Principle

The principle of substitution Barbara Liskov. objects in the program must be replaceable with instances of their subtypes without changing the correctness of the program
If you look more broadly, it is not a feature of any particular project that you can apply SOLID , it is generally about CFM, for example, on another project you need to deploy a boxed Java application on top of various Java, application servers, databases, OS, etc. For this example, I will consider further SOLID principles
In our case, as part of the infrastructure team, there is an agreement that if we installed the role of imbjava or oraclejava, then we have a binary executable java file. This is necessary because higher roles depend on this behavior; they expect java to be present. At the same time, this allows us to replace one implementation / version of java with another without changing the application deployment logic.
The problem here lies in the fact that in Ansible it is impossible to implement such, as a result, some agreements appear within the team.
The Interface Segregation Principle
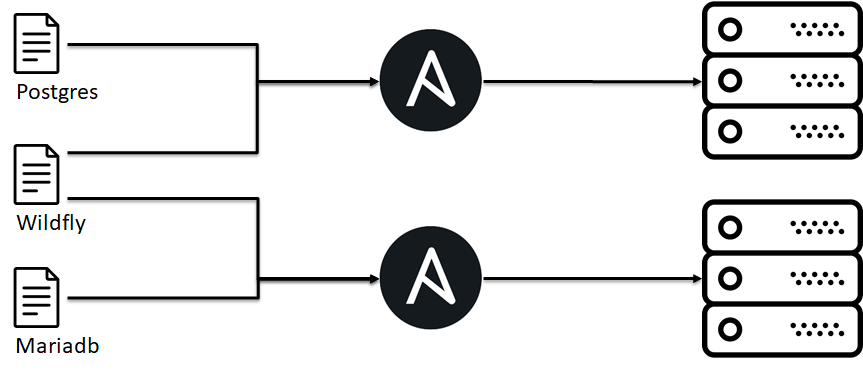
The principle of separation of the interface “many interfaces specifically designed for customers are better than one general purpose interface.
Initially, we tried to put all the variation in deploying the application into one Ansible playbook, but it was difficult to maintain, and the approach when we have an interface out (the client expects port 443) is specified, then for a specific implementation you can build the infrastructure from separate bricks.
The Dependency Inversion Principle

The principle of dependency inversion. Upper level modules should not depend on lower level modules. Both types of modules should depend on abstractions. Abstractions should not depend on the details. Details should depend on abstractions.
Here the example will be based on antipattern.
- One of the customers had a private cloud.
- Inside the cloud, we ordered virtual machines.
- But in view of the cloud’s features, the deployment of the application was tied to which hypervisor the VM hit.
Those. high-level application deployment logic, dependencies flowed to the lower levels of the hypervisor, and this meant problems when reusing this logic. Do not do like this.
Interaction

Infrastructure as a code is not only about code, but also about the relationship between code and a person, about interactions between infrastructure developers.
Bus factor
Suppose you have Vasya on the project. Vasya knows everything about your infrastructure, what will happen if Vasya suddenly disappears? This is a very real situation, because it can be hit by a bus. Sometimes it happens. If this happens and knowledge about the code, its structure, how it works, appearances and passwords are not distributed in the team, then you may encounter a number of unpleasant situations. Various approaches can be used to minimize these risks and distribute knowledge within the team.
Pair devopsing

It’s not a joke that administrators drank beer, changed passwords, but an analogue of pair programming. Those. two engineers sit down on one computer, one keyboard and begin to configure your infrastructure together: configure the server, write the Ansible role, etc. It sounds nice, but it didn’t work for us. But the special cases of this practice worked. A new employee has come, his mentor takes a real task with him, works, transfers knowledge.
Another special case is an incident call. During the problem, a group of persons on duty and involved gathers, one leader is appointed, who shares his screen and voices the train of thought. Other participants follow the leader’s thought, spy tricks from the console, check that they haven’t missed a line in the log, learn new things about the system. This approach worked rather than not.
Code review
Subjectively, more effectively the dissemination of knowledge about the infrastructure and how it was organized was carried out using code review:
- The infrastructure is described by code in the repository.
- Changes occur in a separate branch.
- With a merge request, you can see the delta of changes in infrastructure.
The highlight here was that the reviewers were selected in turn, according to the schedule, i.e. with some probability you will climb into a new piece of infrastructure.
Code Style

Over time, squabbles began to appear during the review, as reviewers had their own style and rotatability of reviewers stacked them with different styles: 2 spaces or 4, camelCase or snake_case. Implement this did not work right away.
- The first idea was to recommend the use of linter, because all the same engineers, all smart. But different editors, OS, not convenient
- This evolved into a bot, which for each commit commit to a problem wrote in slack, and applied the output of linter. But in most cases, more important matters were found and the code remained not fixed.
Green build master
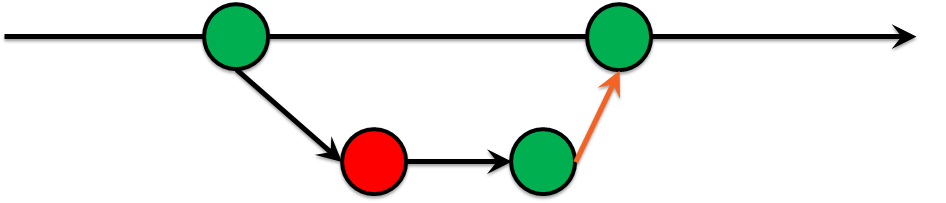
Time passes, and we came to the conclusion that you should not allow commits that do not pass certain tests into the master. Voila! we invented the Green Build Master, which has long been practiced in software development:
- Development is in a separate branch.
- Tests run on this thread.
- If the tests fail, the code will not get into the wizard.
Making this decision was very painful because caused a lot of controversy, but it was worth it, because requests for mergers began to come to the review without disagreements in style and over time, the number of problem areas began to decrease.
IaC Testing

In addition to style checking, you can use other things, for example, to verify that your infrastructure can really be deployed. Or check that changes in infrastructure will not result in a loss of money. Why might this be needed? The question is complex and philosophical, it is better to answer with the tale that somehow there was an auto-scaler on Powershell which did not check the boundary conditions => more VMs were created than necessary => the client spent more money than planned. It’s not enough pleasant, but it would be quite possible to catch this mistake at earlier stages.
One may ask, why make complex infrastructure even more difficult? Tests for the infrastructure, as well as for the code, are not about simplification, but about knowing how your infrastructure should work.
IaC Testing Pyramid

IaC Testing: Static Analysis
If you immediately deploy the entire infrastructure and verify that it works, then it may turn out that it takes a lot of time and requires a lot of time. Therefore, the basis should be something quickly working, it is a lot, and it covers many primitive places.
Bash is tricky
Here is a trivial example. select all files in the current directory and copy to another location. The first thing that comes to mind:
for i in * ; do cp $i /some/path/$i.bak done
But what if there is a space in the file name? Well, ok, we are smart, we can use quotes:
for i in * ; do cp "$i" "/some/path/$i.bak" ; done
Well done? no! What if there is nothing in the directory, i.e. Globbing won't work.
find . -type f -exec mv -v {} dst/{}.bak \;
Now well done? not ... Forgot that the file name may be \n
.
touch x mv x "$(printf "foo\nbar")" find . -type f -print0 | xargs -0 mv -t /path/to/target-dir
Static analysis tools
The problem from the previous step could be caught when we forgot the quotes, for this there are many Shellcheck tools in nature, there are many of them, and most likely you can find your IDE linter for your stack.
| Language | Tool |
|---|---|
| bash | Shellcheck |
| Ruby | Rubocop |
| python | Pylint |
| ansible | Ansible lint |
IaC Testing: Unit Tests
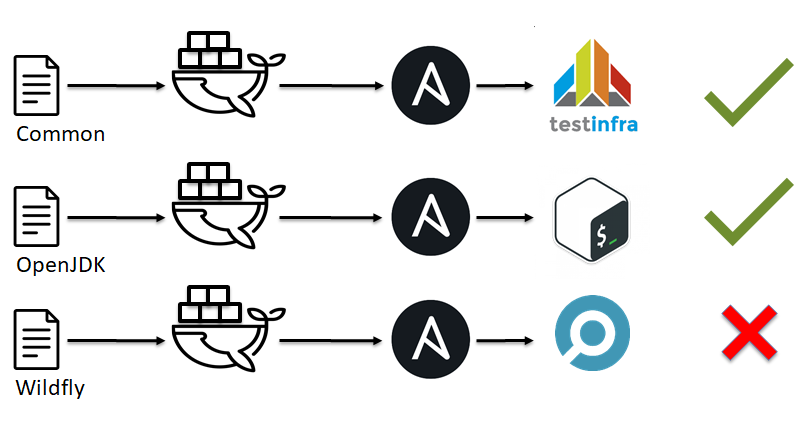
As we saw from the previous example, linter is not omnipotent and cannot point to all the problem areas. Further, by analogy with testing in software development, we can recall unit tests. Then shunit , junit , rspec , pytest immediately come to mind. But what to do with ansible, chef, saltstack and others like them?
At the very beginning, we talked about SOLID and the fact that our infrastructure should consist of small bricks. Their time has come.
- Infrastructure is crushed into small bricks, for example, Ansible roles.
- Some kind of environment is unfolding, be it docker or VM.
- We apply our Ansible role to this test environment.
- Check that everything worked out as we expect (run tests).
- We decide ok or not ok.
IaC Testing: Unit Testing tools
The question is, what are tests for CFM? you can run the script corny, or you can use ready-made solutions for this:
| CFM | Tool |
|---|---|
| Ansible | Testinfra |
| Chef | Inspec |
| Chef | Serverspec |
| saltstack | Goss |
Example for testinfra, we verify that users test1
, test2
exist and are in the sshusers
group:
def test_default_users(host): users = ['test1', 'test2' ] for login in users: assert host.user(login).exists assert 'sshusers' in host.user(login).groups
What to choose? The question is complex and ambiguous, here is an example of a change in projects on github for 2018-2019:

IaC Testing frameworks
There is how to put it all together and run? You can take and do everything yourself if you have a sufficient number of engineers. And you can take ready-made solutions, though there are not very many of them:
| CFM | Tool |
|---|---|
| Ansible | Molecule |
| Chef | Test kitchen |
| Terraform | Terratest |
An example of a change in projects on github for 2018-2019:

Molecule vs. Testkitchen

Initially, we tried using testkitchen :
- Create VMs in parallel.
- Apply Ansible Roles.
- Drive away inspec.
For 25-35 roles, this worked for 40-70 minutes, which was a long time.
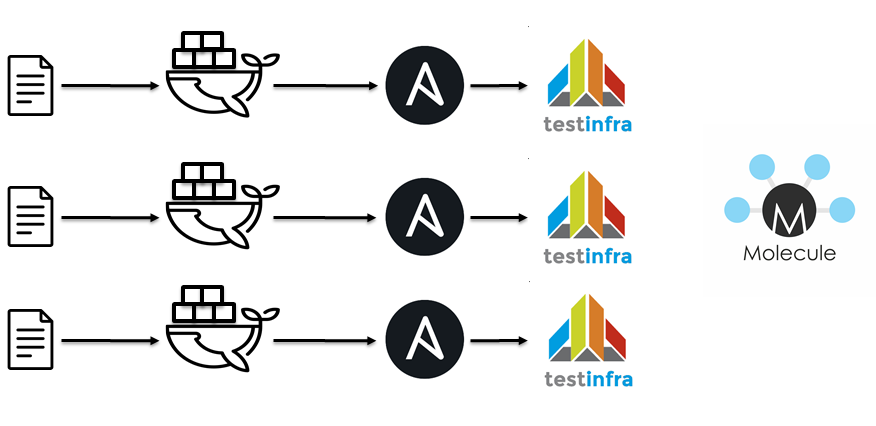
The next step was the switch to jenkins / docker / ansible / molecule. Idiologically, everything is the same
- Lint playbooks.
- To spill roles.
- Run container
- Apply Ansible Roles.
- Drive away testinfra.
- Check idempotency.
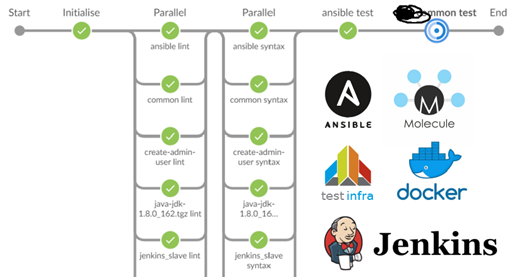
A ruler for 40 roles and tests for a dozen began to take about 15 minutes.

What to choose depends on many factors, such as the stack used, the expertise in the team, etc. here everyone decides how to close the Unit Test question
IaC Testing: Integration Tests
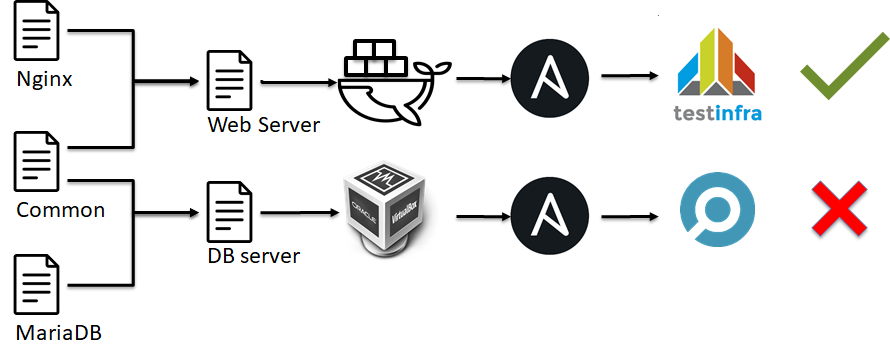
At the next stage of the pyramid of infrastructure testing, integration tests will appear. They are similar to Unit tests:
- Infrastructure is crushed into small bricks, such as Ansible roles.
- Some kind of environment is unfolding, be it docker or VM.
- There are many Ansible roles applied to this test environment.
- Check that everything worked out as we expect (run tests).
- We decide ok or not ok.
Roughly speaking, we do not check the operability of an individual element of the system as in unit tests, we check how the server is configured as a whole.
IaC Testing: End to End Tests
At the top of the pyramid we are met by End to End tests. Those. we do not check the operation of a separate server, a separate script, a separate brick of our infrastructure. We check that many servers are combined together, our infrastructure works as we expect. Unfortunately, I did not see any ready-made box solutions, probably because the infrastructure is often unique and difficult to template and create a framework for testing it. As a result, everyone creates their own solution. There is demand, but there is no answer. Therefore, I’ll tell you what is there to prompt others to sound thoughts or poke my nose, that everything was invented long before us.
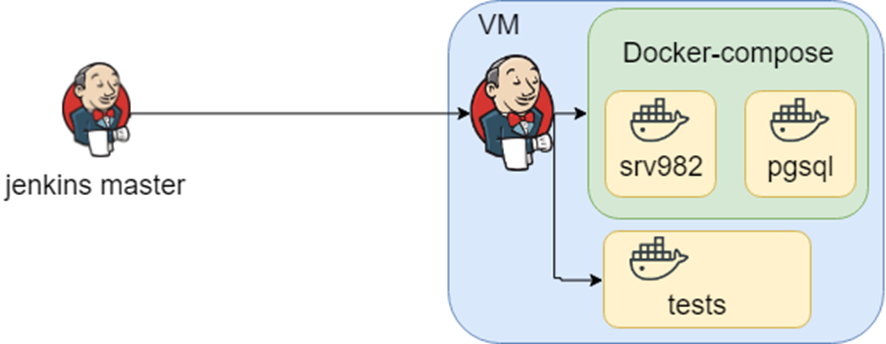
A project with a rich history. Used in large organizations and probably each of you indirectly intersected. The application supports many databases, integrations, etc., etc. Knowing how the infrastructure can look like this is a lot of docker-compose files, and knowing which tests to run in which environment is jenkins.
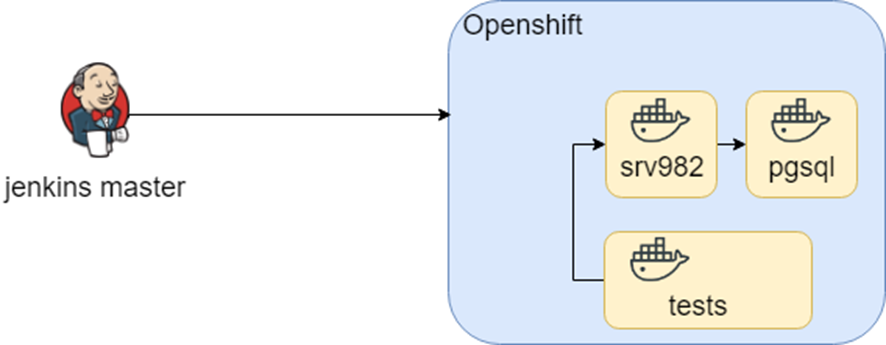
This scheme worked for a long time, until as part of the study we tried to transfer it to Openshift. The containers remained the same, but the launch environment has changed (hello DRY again).
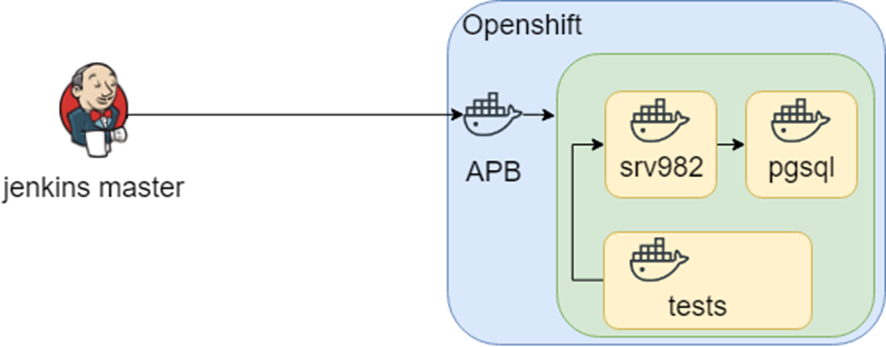
The idea of research went further, and in openshift there was such an APB (Ansible Playbook Bundle) thing that allows you to pack knowledge in the container how to deploy the infrastructure. Those. There is a reproducible, testable point of knowledge on how to deploy the infrastructure.

All this sounded good, until we ran into a heterogeneous infrastructure: we needed Windows for tests. As a result, the knowledge about where to deploy and test is in jenkins.
Conclusion
Infrastructure as Code is
- The code in the repository.
- The interaction of people.
- Infrastructure testing.
- English Version
- Cross post from a personal blog
- Dry run 2019-04-24 SpbLUG
- Video (RU) from DevopsConf 2019-05-28
- Video (RU) from DINS DevOps EVENING 2019-06-20
- Lessons Learned From Writing Over 300,000 Lines of Infrastructure Code & text version
- Integrating Infrastructure as Code into a Continuous Delivery Pipeline
- Testing the infrastructure as code
- Effective development and maintenance of Ansible roles
- Ansible is not bash for you!
All Articles