C for Metal - precious metal for computing on Intel graphics cards
How many Intel processor cores do you have on your computer? If you use a system based on Intel, then in the vast majority of cases, you will need to add one to your answer. Almost all Intel processors - from Atom to Xeon E3, of course, without missing the Core, have for many years included the integrated graphics core Intel Graphics, which is essentially a full-fledged processor, and accordingly, capable of not only showing pictures on the screen and accelerating video, but also perform "ordinary" general-purpose calculations. How can this be used effectively? Look under the cut.

First, we briefly explain why it is worth counting on an Intel GPU. Of course, the CPU performance in the system almost always significantly exceeds the GPU, for that it is also the Central Processor.
But it’s interesting to note that the performance of Intel integrated GPUs over the past decade has grown in percentage terms much more than that of the CPU, and this trend will certainly continue with the advent of new discrete Intel graphics cards. In addition, the GPU, by virtue of its architecture (many vector execution devices), is much better suited to perform certain types of tasks - image processing, that is, in fact, to carry out any operations of the same type on data arrays. The GPU does this with full internal parallelization, consumes less energy than the CPU, and in some cases even surpasses it in absolute speed. Finally, the GPU and CPU can work in parallel, each on its own tasks, providing maximum performance and / or minimum power consumption for the entire system.
- Ok, Intel. We decided to use Intel GPU for general purpose calculations, how to do it?
- The simplest way that does not require any special knowledge in graphics (Direct3D and OpenGL shaders) is OpenCL.
OpenCL cores are platform independent and will automatically execute on all computing devices available in the system - CPU, GPU, FPGA, etc. But the fee for such versatility is far from the maximum possible performance on each type of device, and especially on the integrated Intel GPU. Here is an example: when executing code on any Intel GPU that transposes a 16x16 byte matrix, the performance advantage of the “direct programming” of the Intel GPU will be 8 times higher than with the OpenCL version!
In addition, some of the functionality required to implement common algorithms (for example, “wide filters” that use data from a large group of pixels in a single transformation), OpenCL simply does not support.
Therefore, if you need maximum speed on the GPU and \ or something more complicated than working independently with each element of the array and its closest neighbors, then Intel C for Metal (ICM), a tool for developing applications running on Intel Graphics, will help you .
From the point of view of performance and functionality, ICM can be considered "assembler for Intel graphics cards", and in terms of circuitry and usability - "an analogue of OpenCL for Intel graphics cards."
For many years, ICM has been used internally by Intel in developing media processing products on the Intel GPU. But in 2018, ICM was released to the public, and even with open source!
Intel C for Metal got its current name a few months ago, before that it was called Intel C for Media (the same acronym ICM or just CM or even Cm), and even earlier - the Media Development Framework (MDF). So, if somewhere in the component name, in the documentation or in the comments of the open source code, the old names meet - do not be alarmed, this is historical value.
So, the ICM application code, just like in OpenCL, contains two parts: the “administrative” one, executed on the processor, and the kernel, executed on the GPU. Not surprisingly, the first part is called the host, and the second is the kernel.
Kernels are a function of processing a given block of pixels (or just data), are written in the Intel C for Metal language and compiled into the Intel GPU instruction set (ISA) using the ICM compiler.
The host is a kind of “kernel team manager”, it administers the data transfer process between the CPU and GPU and performs other “managerial work” through the ICM Runtime runtime library and the Intel GPU media driver.
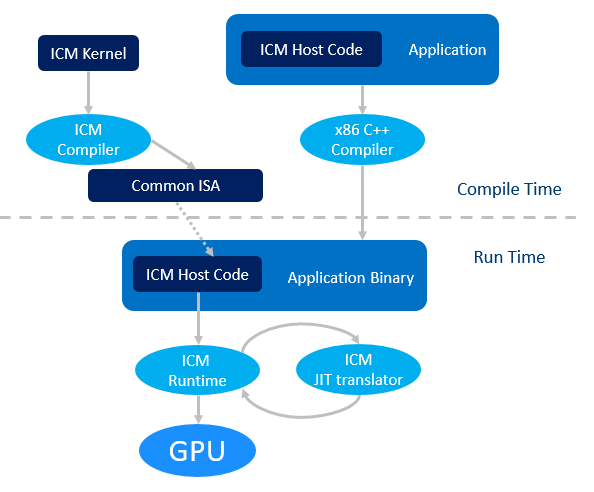
A detailed ICM workflow looks like this:
A couple more important and useful points:
Already from the name "C for Iron" itself, it follows that the device language corresponds to the internal graphics device Intel. That is, it takes into account the fact that the code will be executed on several tens of execution units of the graphic card, each of which is a fully vector processor capable of executing several threads simultaneously.
The ICM language itself is C ++ with some limitations and extensions. Compared to C ++, ICM lacks ... pointers, memory allocation, and static variables. Under the ban also recursive functions. But there is an explicit vector model (SIMD) programming: vector data types - vector, matrix and surface; vector operations on these data types, vector conditions if / else, independently performed for each element of the vector; as well as built-in features for accessing Intel GPU hardware fixed functionality.
The work with vectors, matrices and surfaces in real problems is facilitated by objects of “subsets” - from the corresponding basic objects you can choose only the “reference” blocks that interest you or, as a special case, individual elements by mask.
For example, let's look at ICM code that implements a linear filter - replacing a value
RGB colors of each pixel by its average value and 8 neighbors in the picture:
If the colors (data) in the matrix are located as R8G8B8 , then the calculation with splitting the input image into blocks of 6x8 pixels (6x24 byte data elements) will be as follows:
Please note that the size of the 8x32 input matrix is selected because although the 8x30 block is algorithmically sufficient for calculating the values of all pixels in a 6x24 block, the data block is read in ICM not bytes, but by 32-bit dword elements.
The above code is, in fact, a full-fledged ICM kernel. As mentioned, it will be compiled by the ICM compiler in two stages (precompilation and subsequent JIT translation). The ICM compiler is built on the basis of LLVM and, if desired, can be studied in the sources and built by you yourself .
But what does the ICM host do? Invokes ICM Runtime runtime library functions that:
The simplest host code looks like this:
As you can see, there is nothing complicated in creating and using kernels and a host. Everything is simple!
The only difficulty to warn about in order to return to the real world: currently, in the publicly available version of ICM, the only way to debug kernels is printf messages. How to use them correctly can be seen in the Hello, World example.
Now let's see how it works in practice. The ICM Developer Kit is available for Windows and Linux , and for both operating systems it contains the ICM Compiler, documentation, and tutorial use cases. A detailed description of these training examples is downloaded separately .
For Linux, the package also includes a user-mode media driver for VAAPI with an integrated ICM Runtime runtime library. For Windows, the usual Intel Graphics Driver for Windows will work with ICM. The ICM Runtime runtime library is included in the dll set of this driver. The ICM package includes only the link .lib file for it. If the driver is missing from your system for some reason, it is downloaded from the Intel website, and the correct operation of ICM in drivers is guaranteed, starting from version 15.60 - 2017 of the release).
The source code of the components can be found here:
The rest of this section is specific to Windows, but the general principles for working with ICM apply to Linux as well.
For a “regular” work with the ICM package, you will need Visual Studio starting in 2015 and Cmake starting from version 3.2. At the same time, the configuration and script files of the training examples are designed for VS 2015, to use newer versions of VS files, you will have to study and edit the paths to the VS components yourself.
So, getting to know ICM for Windows:
After that, you can simply build all the training examples - in the examples folder, the build_all.bat script will do this or generate projects for Microsoft Visual Studio - this will create the create_vs.bat script with the name of a specific example as a parameter.
As you can see, the ICM application will be a .exe file with the host part and a .isa file with the corresponding precompiled GPU part.
Various examples are included in the ICM package - from the simplest Hello, World, which shows the basic principles of ICM operation, to the rather complicated one - the implementation of the algorithm for finding the "maximum flow - minimum cut" of the graph (max-flow min-cut problem) used in image segmentation and stitching .
All ICM case studies are well documented right in the code and in the separate description already mentioned. It is recommended to delve into ICM precisely on it - sequentially studying and running examples, and then - modifying them to fit your needs.
For a general understanding of all the existing ICM features, it is strongly recommended that you study the “specification” - the ICM description cmlangspec.html in the \ documents \ compiler \ html \ cmlangspec folder .
In particular, it describes the API of the ICM functions implemented in the hardware - access to the so-called texture samplers (Sampler) - a mechanism for filtering images of different formats, as well as to evaluate the movement (Motion Estimation) between video frames and some video analytics capabilities.
Speaking about the performance of ICM applications, it should be noted that case studies include measuring the time of their work, so that by running them on the target system and comparing them with your tasks, you can evaluate the appropriateness of using ICM for them.
And general considerations regarding ICM performance are quite simple:
Do you have OpenCL code, but its performance does not please you? Or CUDA code, but you want to work on a much larger number of platforms? Then it's worth a look at ICM.
ICM is a living and evolving product. You can participate in its use and its development - the corresponding repositories on github are waiting for your commits. All the information necessary for both processes is in this article and readme files on github. And if something is missing, it will appear after your questions in the comments.
First, we briefly explain why it is worth counting on an Intel GPU. Of course, the CPU performance in the system almost always significantly exceeds the GPU, for that it is also the Central Processor.
But it’s interesting to note that the performance of Intel integrated GPUs over the past decade has grown in percentage terms much more than that of the CPU, and this trend will certainly continue with the advent of new discrete Intel graphics cards. In addition, the GPU, by virtue of its architecture (many vector execution devices), is much better suited to perform certain types of tasks - image processing, that is, in fact, to carry out any operations of the same type on data arrays. The GPU does this with full internal parallelization, consumes less energy than the CPU, and in some cases even surpasses it in absolute speed. Finally, the GPU and CPU can work in parallel, each on its own tasks, providing maximum performance and / or minimum power consumption for the entire system.
- Ok, Intel. We decided to use Intel GPU for general purpose calculations, how to do it?
- The simplest way that does not require any special knowledge in graphics (Direct3D and OpenGL shaders) is OpenCL.
OpenCL cores are platform independent and will automatically execute on all computing devices available in the system - CPU, GPU, FPGA, etc. But the fee for such versatility is far from the maximum possible performance on each type of device, and especially on the integrated Intel GPU. Here is an example: when executing code on any Intel GPU that transposes a 16x16 byte matrix, the performance advantage of the “direct programming” of the Intel GPU will be 8 times higher than with the OpenCL version!
In addition, some of the functionality required to implement common algorithms (for example, “wide filters” that use data from a large group of pixels in a single transformation), OpenCL simply does not support.
Therefore, if you need maximum speed on the GPU and \ or something more complicated than working independently with each element of the array and its closest neighbors, then Intel C for Metal (ICM), a tool for developing applications running on Intel Graphics, will help you .
ICM - welcome to the forge!
From the point of view of performance and functionality, ICM can be considered "assembler for Intel graphics cards", and in terms of circuitry and usability - "an analogue of OpenCL for Intel graphics cards."
For many years, ICM has been used internally by Intel in developing media processing products on the Intel GPU. But in 2018, ICM was released to the public, and even with open source!
Intel C for Metal got its current name a few months ago, before that it was called Intel C for Media (the same acronym ICM or just CM or even Cm), and even earlier - the Media Development Framework (MDF). So, if somewhere in the component name, in the documentation or in the comments of the open source code, the old names meet - do not be alarmed, this is historical value.
So, the ICM application code, just like in OpenCL, contains two parts: the “administrative” one, executed on the processor, and the kernel, executed on the GPU. Not surprisingly, the first part is called the host, and the second is the kernel.
Kernels are a function of processing a given block of pixels (or just data), are written in the Intel C for Metal language and compiled into the Intel GPU instruction set (ISA) using the ICM compiler.
The host is a kind of “kernel team manager”, it administers the data transfer process between the CPU and GPU and performs other “managerial work” through the ICM Runtime runtime library and the Intel GPU media driver.
A detailed ICM workflow looks like this:
- ICM host code is compiled by any x86 C / C ++ compiler along with the entire application;
- The ICM kernel code is compiled by the ICM compiler into a binary file with some common instruction set (Common ISA);
- At runtime, this general set of JIT instructions translates to a specific Intel GPU;
- The ICM host invokes the ICM runtime library to communicate with the GPU and operating system.
A couple more important and useful points:
- The surfaces used in ICM to represent / store data can be shared with DirectX 11 and 9 (DXVA on Linux).
- The GPU can take and write data from both video memory and system memory shared with the CPU. The ICM includes special functions for both cases of data transfer in both directions. At the same time, the system memory is exactly shared, and real copying in it is not required - for this, the so-called zero copy is provided in ICM.
ICM - in the vent of the volcano!
Already from the name "C for Iron" itself, it follows that the device language corresponds to the internal graphics device Intel. That is, it takes into account the fact that the code will be executed on several tens of execution units of the graphic card, each of which is a fully vector processor capable of executing several threads simultaneously.
The ICM language itself is C ++ with some limitations and extensions. Compared to C ++, ICM lacks ... pointers, memory allocation, and static variables. Under the ban also recursive functions. But there is an explicit vector model (SIMD) programming: vector data types - vector, matrix and surface; vector operations on these data types, vector conditions if / else, independently performed for each element of the vector; as well as built-in features for accessing Intel GPU hardware fixed functionality.
The work with vectors, matrices and surfaces in real problems is facilitated by objects of “subsets” - from the corresponding basic objects you can choose only the “reference” blocks that interest you or, as a special case, individual elements by mask.
For example, let's look at ICM code that implements a linear filter - replacing a value
RGB colors of each pixel by its average value and 8 neighbors in the picture:
 | I (x, y) = [I (x-1, y-1) + I (x-1, y) + I (x-1, y + 1) + I (x, y-1) +
+ I (x, y) + I (x, y + 1) + I (x + 1, y-1) + I (x + 1, y) + I (x + 1, y + 1)] / 9 |
If the colors (data) in the matrix are located as R8G8B8 , then the calculation with splitting the input image into blocks of 6x8 pixels (6x24 byte data elements) will be as follows:
_GENX_MAIN_ void linear(SurfaceIndex inBuf, SurfaceIndex outBuf, uint h_pos, uint v_pos){ // 8x32 matrix<uchar, 8, 32> in; // 6x24 matrix<uchar, 6, 24> out; matrix<float, 6, 24> m; // read(inBuf h_pos*24, v_pos*6, in); // - m = in.select<6,1,24,1>(1,3); m += in.select<6,1,24,1>(0,0); m += in.select<6,1,24,1>(0,3); m += in.select<6,1,24,1>(0,6); m += in.select<6,1,24,1>(1,0); m += in.select<6,1,24,1>(1,6); m += in.select<6,1,24,1>(2,0); m += in.select<6,1,24,1>(2,3); m += in.select<6,1,24,1>(2,6); // - 9 * 0.111f; out = m * 0.111f; // write(outBuf, h_pos*24, v_pos*6, out); }
- The size of the matrices is set in the form <data type, height, width>;
- the select <v_size, v_stride, h_size, h_stride> operator (i, j) returns the submatrix starting with the element (i, j) , v_size shows the number of selected rows, v_stride - the distance between selected rows h_size - the number of selected columns, h_stride - the distance between them .
Please note that the size of the 8x32 input matrix is selected because although the 8x30 block is algorithmically sufficient for calculating the values of all pixels in a 6x24 block, the data block is read in ICM not bytes, but by 32-bit dword elements.
The above code is, in fact, a full-fledged ICM kernel. As mentioned, it will be compiled by the ICM compiler in two stages (precompilation and subsequent JIT translation). The ICM compiler is built on the basis of LLVM and, if desired, can be studied in the sources and built by you yourself .
But what does the ICM host do? Invokes ICM Runtime runtime library functions that:
- Create, initialize and delete after using the GPU device (CmDevice), as well as surfaces containing user data used in kernels (CmSurface);
- Work with kernels - download them from precompiled .isa files, prepare their arguments, indicating the part of the data that each kernel will work with;
- Create and manage a kernel execution queue;
- They control the operation of the threads executing each kernel on the GPU;
- Manage events (CmEvent) - GPU and CPU synchronization objects;
- Transfer data between the GPU and the CPU, or rather, between the system and video memory;
- Report errors, measure the time of operation of the kernels.
The simplest host code looks like this:
// CmDevice cm_result_check(::CreateCmDevice(p_cm_device, version)); // hello_world_genx.isa std::string isa_code = isa::loadFile("hello_world_genx.isa"); // isa CmProgram CmProgram *p_program = nullptr; cm_result_check(p_cm_device->LoadProgram(const_cast<char* >(isa_code.data()),isa_code.size(), p_program)); // hello_world . CmKernel *p_kernel = nullptr; cm_result_check(p_cm_device->CreateKernel(p_program, "hello_world", p_kernel)); // CmKernel CmThreadSpace *p_thread_space = nullptr; cm_result_check(p_cm_device->CreateThreadSpace(thread_width, thread_height, p_thread_space)); // . cm_result_check(p_kernel->SetKernelArg(0, sizeof(thread_width), &thread_width)); // CmTask – // // . CmTask *p_task = nullptr; cm_result_check(p_cm_device->CreateTask(p_task)); cm_result_check(p_task->AddKernel(p_kernel)); // CmQueue *p_queue = nullptr; cm_result_check(p_cm_device->CreateQueue(p_queue)); // GPU ( ). CmEvent *p_event = nullptr; cm_result_check(p_queue->Enqueue(p_task, p_event, p_thread_space)); // . cm_result_check(p_event->WaitForTaskFinished());
As you can see, there is nothing complicated in creating and using kernels and a host. Everything is simple!
The only difficulty to warn about in order to return to the real world: currently, in the publicly available version of ICM, the only way to debug kernels is printf messages. How to use them correctly can be seen in the Hello, World example.
ICM - not heavy metal!
Now let's see how it works in practice. The ICM Developer Kit is available for Windows and Linux , and for both operating systems it contains the ICM Compiler, documentation, and tutorial use cases. A detailed description of these training examples is downloaded separately .
For Linux, the package also includes a user-mode media driver for VAAPI with an integrated ICM Runtime runtime library. For Windows, the usual Intel Graphics Driver for Windows will work with ICM. The ICM Runtime runtime library is included in the dll set of this driver. The ICM package includes only the link .lib file for it. If the driver is missing from your system for some reason, it is downloaded from the Intel website, and the correct operation of ICM in drivers is guaranteed, starting from version 15.60 - 2017 of the release).
The source code of the components can be found here:
- Intel Media Driver for VAAPI and Intel C for Media Runtime: github.com/intel/media-driver
- Intel C for Media Compiler and examples: github.com/intel/cm-compiler
- Intel Graphics Compiler: github.com/intel/intel-graphics-compiler
The rest of this section is specific to Windows, but the general principles for working with ICM apply to Linux as well.
For a “regular” work with the ICM package, you will need Visual Studio starting in 2015 and Cmake starting from version 3.2. At the same time, the configuration and script files of the training examples are designed for VS 2015, to use newer versions of VS files, you will have to study and edit the paths to the VS components yourself.
So, getting to know ICM for Windows:
- Download the archive ;
- Unpack it;
- We launch (preferably on the VS command line) the setupenv.bat environment configuration script with three parameters - the Intel GPU generation (corresponding to the processor in which the GPU is built in, it can be left by default: gen9), the compilation platform: x86 \ x64 and the DirectX version for sharing with ICM: dx9 / dx11.
After that, you can simply build all the training examples - in the examples folder, the build_all.bat script will do this or generate projects for Microsoft Visual Studio - this will create the create_vs.bat script with the name of a specific example as a parameter.
As you can see, the ICM application will be a .exe file with the host part and a .isa file with the corresponding precompiled GPU part.
Various examples are included in the ICM package - from the simplest Hello, World, which shows the basic principles of ICM operation, to the rather complicated one - the implementation of the algorithm for finding the "maximum flow - minimum cut" of the graph (max-flow min-cut problem) used in image segmentation and stitching .
All ICM case studies are well documented right in the code and in the separate description already mentioned. It is recommended to delve into ICM precisely on it - sequentially studying and running examples, and then - modifying them to fit your needs.
For a general understanding of all the existing ICM features, it is strongly recommended that you study the “specification” - the ICM description cmlangspec.html in the \ documents \ compiler \ html \ cmlangspec folder .
In particular, it describes the API of the ICM functions implemented in the hardware - access to the so-called texture samplers (Sampler) - a mechanism for filtering images of different formats, as well as to evaluate the movement (Motion Estimation) between video frames and some video analytics capabilities.
ICM - hit the iron while it's hot!
Speaking about the performance of ICM applications, it should be noted that case studies include measuring the time of their work, so that by running them on the target system and comparing them with your tasks, you can evaluate the appropriateness of using ICM for them.
And general considerations regarding ICM performance are quite simple:
- When uploading calculations to the GPU, remember the overhead of transmitting the CPU data <-> GPU and synchronizing these devices. Therefore, an example such as Hello, World is not a good candidate for an ICM implementation. But the algorithms of computer vision, AI and any non-trivial processing of data arrays, especially with a change in the order of this data in the process or at the output, is what ICM needs.
- In addition, when designing an ICM code, it is necessary to take into account the internal GPU device, that is, it is desirable to create a sufficient number (> 1000) of GPU threads and load them all with work. In this case, it is a good idea to split the images for processing into small blocks. But the specific way of partitioning, as well as the choice of a specific processing algorithm to achieve maximum performance, is not a trivial task. However, this applies to any way of working with any GPU (and CPU).
Do you have OpenCL code, but its performance does not please you? Or CUDA code, but you want to work on a much larger number of platforms? Then it's worth a look at ICM.
ICM is a living and evolving product. You can participate in its use and its development - the corresponding repositories on github are waiting for your commits. All the information necessary for both processes is in this article and readme files on github. And if something is missing, it will appear after your questions in the comments.
All Articles