Kubernetes Storage Volume Plugins: Flexvolume to CSI

In the days when Kubernetes was still v1.0.0, volume plugins existed. They were needed to connect to Kubernetes systems for storing persistent (permanent) container data. Their number was small, and among the first - such storage providers as GCE PD, Ceph, AWS EBS and others.
Plug-ins were delivered together with Kubernetes, for which they got their name - in-tree. However, many of the existing set of such plug-ins was not enough. The craftsmen added simple plugins to the core of Kubernetes using patches, after which they assembled their own Kubernetes and put it on their servers. But over time, Kubernetes developers realized that the fish could not be solved. People need a fishing rod . And in Kubernetes v1.2.0 release, it appeared ...
Flexvolume plugin: minimal fishing rod
The developers of Kubernetes created the FlexVolume plugin, which was a logical binding of variables and methods for working with third-party Flexvolume drivers.
Let's stop and take a closer look at what the FlexVolume driver is. This is a certain executable file (binary file, Python script, Bash script, etc.), which, when executed, takes command line arguments and returns a message with previously known fields in JSON format. By convention, the first command line argument is always the method, and the rest of the arguments are its parameters.
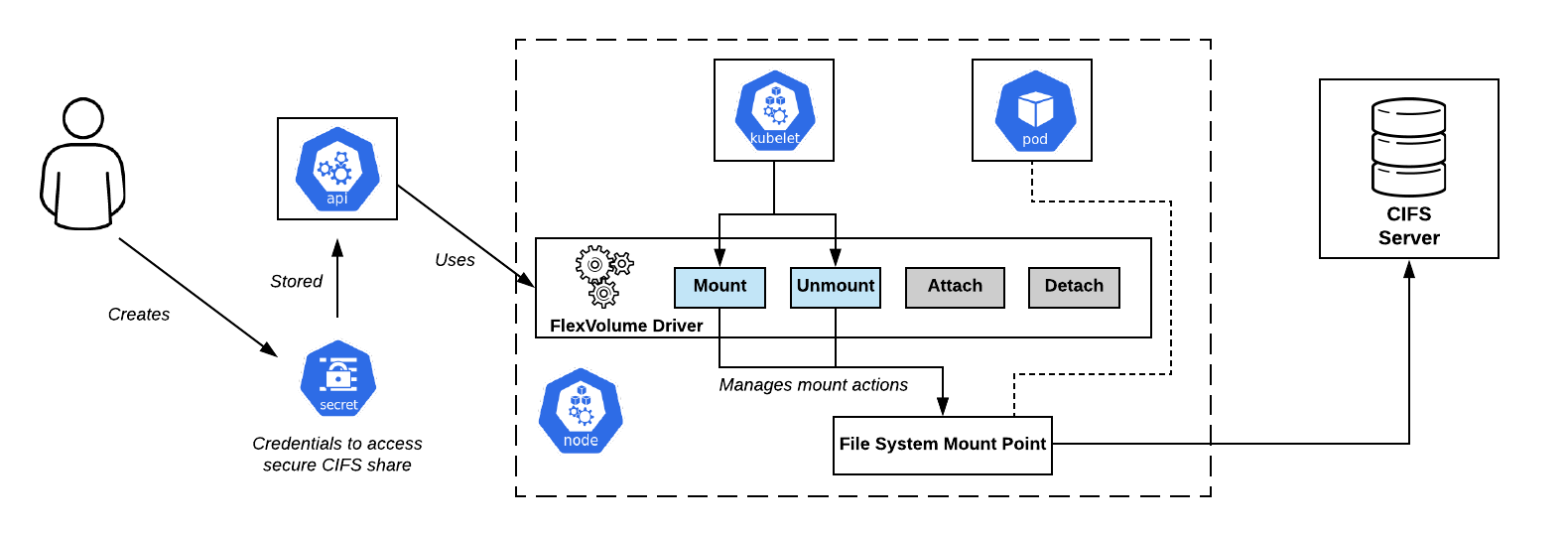
CIFS Shares connection scheme in OpenShift. Flexvolume Driver - Right in the Center
The minimum set of methods looks like this:
flexvolume_driver mount # pod' # : { "status": "Success"/"Failure"/"Not supported", "message": " ", } flexvolume_driver unmount # pod' # : { "status": "Success"/"Failure"/"Not supported", "message": " ", } flexvolume_driver init # # : { "status": "Success"/"Failure"/"Not supported", "message": " ", // , attach/deatach "capabilities":{"attach": True/False} }
Using the
attach
and
detach
methods will determine the scenario according to which in the future kubelet will act when the driver is called. There are also special
expandvolume
and
expandfs
that are responsible for dynamically resizing a volume.
As an example of the changes that the
expandvolume
method
expandvolume
, and with it the ability to perform volume resizing in real time, you can check out our pull request in the Rook Ceph Operator.
Here is an example implementation of the Flexvolume driver for working with NFS:
usage() { err "Invalid usage. Usage: " err "\t$0 init" err "\t$0 mount <mount dir> <json params>" err "\t$0 unmount <mount dir>" exit 1 } err() { echo -ne $* 1>&2 } log() { echo -ne $* >&1 } ismounted() { MOUNT=`findmnt -n ${MNTPATH} 2>/dev/null | cut -d' ' -f1` if [ "${MOUNT}" == "${MNTPATH}" ]; then echo "1" else echo "0" fi } domount() { MNTPATH=$1 NFS_SERVER=$(echo $2 | jq -r '.server') SHARE=$(echo $2 | jq -r '.share') if [ $(ismounted) -eq 1 ] ; then log '{"status": "Success"}' exit 0 fi mkdir -p ${MNTPATH} &> /dev/null mount -t nfs ${NFS_SERVER}:/${SHARE} ${MNTPATH} &> /dev/null if [ $? -ne 0 ]; then err "{ \"status\": \"Failure\", \"message\": \"Failed to mount ${NFS_SERVER}:${SHARE} at ${MNTPATH}\"}" exit 1 fi log '{"status": "Success"}' exit 0 } unmount() { MNTPATH=$1 if [ $(ismounted) -eq 0 ] ; then log '{"status": "Success"}' exit 0 fi umount ${MNTPATH} &> /dev/null if [ $? -ne 0 ]; then err "{ \"status\": \"Failed\", \"message\": \"Failed to unmount volume at ${MNTPATH}\"}" exit 1 fi log '{"status": "Success"}' exit 0 } op=$1 if [ "$op" = "init" ]; then log '{"status": "Success", "capabilities": {"attach": false}}' exit 0 fi if [ $# -lt 2 ]; then usage fi shift case "$op" in mount) domount $* ;; unmount) unmount $* ;; *) log '{"status": "Not supported"}' exit 0 esac exit 1
So, after preparing the actual executable file, you need to lay out the driver in the Kubernetes cluster . The driver must be located on each node of the cluster according to a predefined path. By default was selected:
/usr/libexec/kubernetes/kubelet-plugins/volume/exec/__~_/
... but using different Kubernetes distributions (OpenShift, Rancher ...) the path may be different.
Flexvolume problems: how to cast a fishing rod?
Putting the Flexvolume driver on the cluster nodes turned out to be a non-trivial task. Having done the operation once manually, it is easy to encounter a situation when new nodes appear in the cluster: due to the addition of a new node, automatic horizontal scaling, or, worse, replacing the node due to a malfunction. In this case, it is impossible to work with the storage on these nodes until you manually add the Flexvolume driver to them in the same way.
The solution to this problem was one of the primitives of Kubernetes -
DaemonSet
. When a new node appears in the cluster, it automatically gets a pod from our DaemonSet, to which a local volume is attached along the way to find Flexvolume drivers. Upon successful creation, pod copies the necessary files for the driver to work on disk.
Here is an example of such a DaemonSet for laying out the Flexvolume plugin:
apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: flex-set spec: template: metadata: name: flex-deploy labels: app: flex-deploy spec: containers: - image: <deployment_image> name: flex-deploy securityContext: privileged: true volumeMounts: - mountPath: /flexmnt name: flexvolume-mount volumes: - name: flexvolume-mount hostPath: path: <host_driver_directory>
... and an example of a Bash script for laying out a Flexvolume driver:
#!/bin/sh set -o errexit set -o pipefail VENDOR=k8s.io DRIVER=nfs driver_dir=$VENDOR${VENDOR:+"~"}${DRIVER} if [ ! -d "/flexmnt/$driver_dir" ]; then mkdir "/flexmnt/$driver_dir" fi cp "/$DRIVER" "/flexmnt/$driver_dir/.$DRIVER" mv -f "/flexmnt/$driver_dir/.$DRIVER" "/flexmnt/$driver_dir/$DRIVER" while : ; do sleep 3600 done
It is important not to forget that the copy operation is not atomic . It is very likely that kubelet will start using the driver before the process of its preparation is completed, which will cause an error in the system. The correct approach would be to first copy the driver files under a different name, and then use the atomic renaming operation.
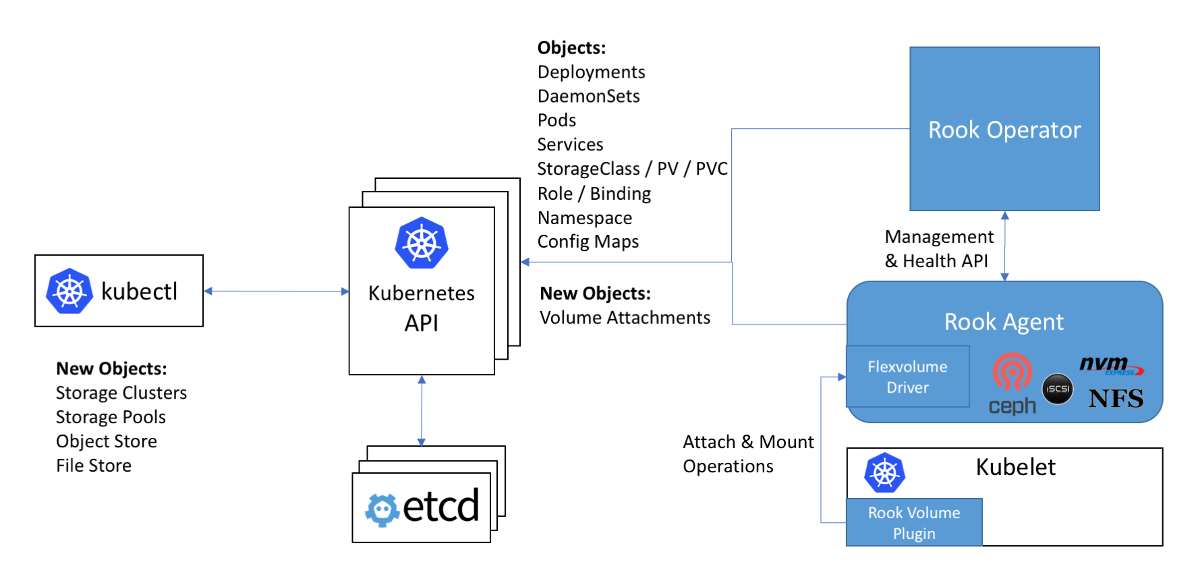
Scheme of working with Ceph in the Rook statement: the Flexvolume driver in the diagram is inside the Rook agent
The next problem when using Flexvolume drivers is that for most storages , the software necessary for this should be installed on the cluster node (for example, the ceph-common package for Ceph). Initially, the Flexvolume plugin was not designed to implement such complex systems.
An original solution to this problem can be seen in the implementation of the Flexvolume driver of the Rook operator:
The driver itself is designed as an RPC client. The IPC socket for communication lies in the same directory as the driver itself. We remember that for copying driver files it would be good to use DaemonSet, which connects a directory with the driver as a volume. After copying the necessary rook driver files, this pod does not die, but connects to the IPC socket via the attached volume as a full-fledged RPC server. The ceph-common package is already installed inside the pod container. The IPC socket gives confidence that kubelet will communicate with the particular pod located on the same node. Everything ingenious is simple! ..
Goodbye, our affectionate ... in-tree plugins!
Kubernetes developers have found that the number of plugins for storage within the kernel is twenty. And the change in each of them somehow goes through the full Kubernetes release cycle.
It turns out that to use the new version of the plugin for storage, you need to update the entire cluster . In addition to this, you may be surprised that the new version of Kubernetes suddenly becomes incompatible with the Linux kernel used ... And therefore, you wipe away the tears and grit your teeth and coordinate with the authorities and users the time for updating the Linux kernel and Kubernetes cluster. With possible downtime in the provision of services.
The situation is more than comical, don’t you? It became clear to the whole community that the approach did not work. With a strong-willed decision, Kubernetes developers announce that new storage plugins will no longer be accepted into the kernel. To everything else, as we already know, in the implementation of the Flexvolume plugin a number of shortcomings were revealed ...
Once and for all, the last added plugin for volumes in Kubernetes, CSI, was called upon to close the issue with persistent data warehouses. Its alpha version, more fully referred to as Out-of-Tree CSI Volume Plugins, was announced in Kubernetes 1.9 .
Container Storage Interface, or CSI 3000 spinning!
First of all, I would like to note that CSI is not just a volume plugin, but a real standard for creating custom components for working with data warehouses . It was assumed that container orchestration systems, such as Kubernetes and Mesos, should “learn” how to work with components implemented according to this standard. And now Kubernetes has already learned.
What is the device of the CSI plugin in Kubernetes? The CSI plugin works with special drivers ( CSI drivers ) written by third-party developers. The CSI driver in Kubernetes should at least consist of two components (pods):
- Controller - manages external persistent stores. It is implemented as a gRPC server for which the
StatefulSet
primitive is used. - Node - is responsible for mounting persistent stores to cluster nodes. It is also implemented as a gRPC server, but the
DaemonSet
primitive is used for it.
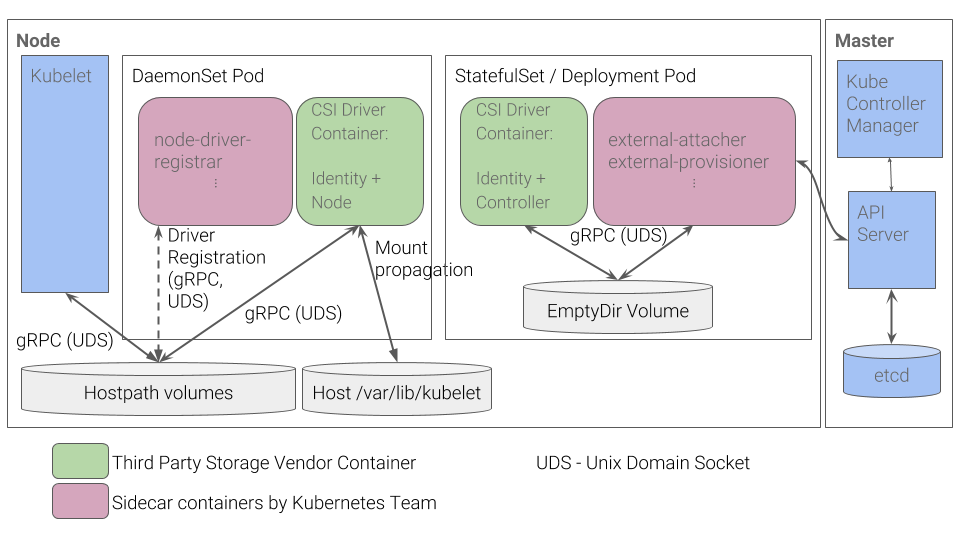
Kubernetes CSI Plugin Workflow
You can learn about some other details of CSI, for example, from the article “ Understanding the CSI ”, a translation of which we published a year ago.
The advantages of such an implementation
- For basic things - for example, to register a driver for a node - Kubernetes developers have implemented a set of containers. You no longer need to generate a JSON response with capabilities yourself, as was done for the Flexvolume plugin.
- Instead of “slipping” the nodes of executable files, we now lay out pods in the cluster. This is what we originally expected from Kubernetes: all processes occur inside containers deployed using Kubernetes primitives.
- To implement complex drivers, you no longer need to develop an RPC server and an RPC client. The client for us was implemented by Kubernetes developers.
- Passing arguments to work with the gRPC protocol is much more convenient, flexible, and more reliable than passing them through command line arguments. To understand how to add support for volume usage metrics to CSI by adding a standardized gRPC method, you can check out our pull request for the vsphere-csi driver.
- Communication takes place via IPC sockets so as not to get confused whether the request was sent to the kubelet pod.
Does this list remind you of anything? The advantages of CSI are the solution to the very problems that were not taken into account when developing the Flexvolume plugin.
findings
CSI as a standard for implementing custom plugins for interacting with data warehouses has been very warmly accepted by the community. Moreover, due to its advantages and versatility, CSI drivers are created even for repositories such as Ceph or AWS EBS, plugins for working with which were added in the very first version of Kubernetes.
In early 2019, in-tree plugins were deprecated . It is planned to continue supporting the Flexvolume plugin, but there will be no development of new functionality for it.
We ourselves already have experience using ceph-csi, vsphere-csi and are ready to add to this list! So far, CSI copes with the tasks assigned to it with a bang, and there we wait and see.
Do not forget that everything new is a well rethought old!
PS
Read also in our blog:
All Articles