One standup in Yandex.Taxi, or What you need to teach the backend developer
My name is Oleg Ermakov, I work in the backend development team of the Yandex.Taxi application. It is customary for us to conduct daily stand-ups where each of us talks about the tasks done during the day. This is how it happens ...
The names of employees can be changed, but the tasks are quite real!
At 12:45, the whole team gathers in the meeting room. The first word is taken by Ivan, a trainee developer.
Let's take a moment off from the stand-up and summarize the local results of everything that Ivan says. When writing code, the main goal is to ensure its performance. To achieve this goal, you must complete the following tasks:
Alas, even specialists with many years of experience do not always use these approaches in their work. At the backend development school that we are doing now, students will gain practical skills in writing architecturally high-quality code. Our other goal is to disseminate test coverage practices for the project.
But back to the stand-up. After Ivan, Anna speaks.
To summarize again:
Working with information and organizing data flows is an integral part of the tasks of any backend developer. The school will introduce the architecture of the interaction of services (and data sources). Students will learn to work with databases architecturally and in terms of operation - data migration and testing.
The last to speak is Vadim.
Summary:
The teachers of the Backend School ate more than a pound of salt and filled a lot of cones in the asynchronous operation of services. They will tell students about the features of Python's asynchronous operation - both at the practical level and in the analysis of package internals.
Learning Python can help you:
To gain a higher level understanding of architecture, read the books:
Another of the most important skills that you can endlessly develop in yourself is reading someone else’s code. If you suddenly realize that you rarely read someone else’s code, I advise you to develop the habit of regularly watching new popular repositories .
The stand-up was over, everyone went to work.
The names of employees can be changed, but the tasks are quite real!
At 12:45, the whole team gathers in the meeting room. The first word is taken by Ivan, a trainee developer.
Ivan:
I worked on the task of displaying all possible options for the amounts that the passenger could give to the driver at a known cost of the trip. The task is quite well known - it is called "Coin Exchange". Taking into account the specifics, he added several optimizations to the algorithm. I gave the pool request for the review the day before yesterday, but since then I have been correcting the comments.
By Anna's contented smile, it became clear whose remarks Ivan corrects.
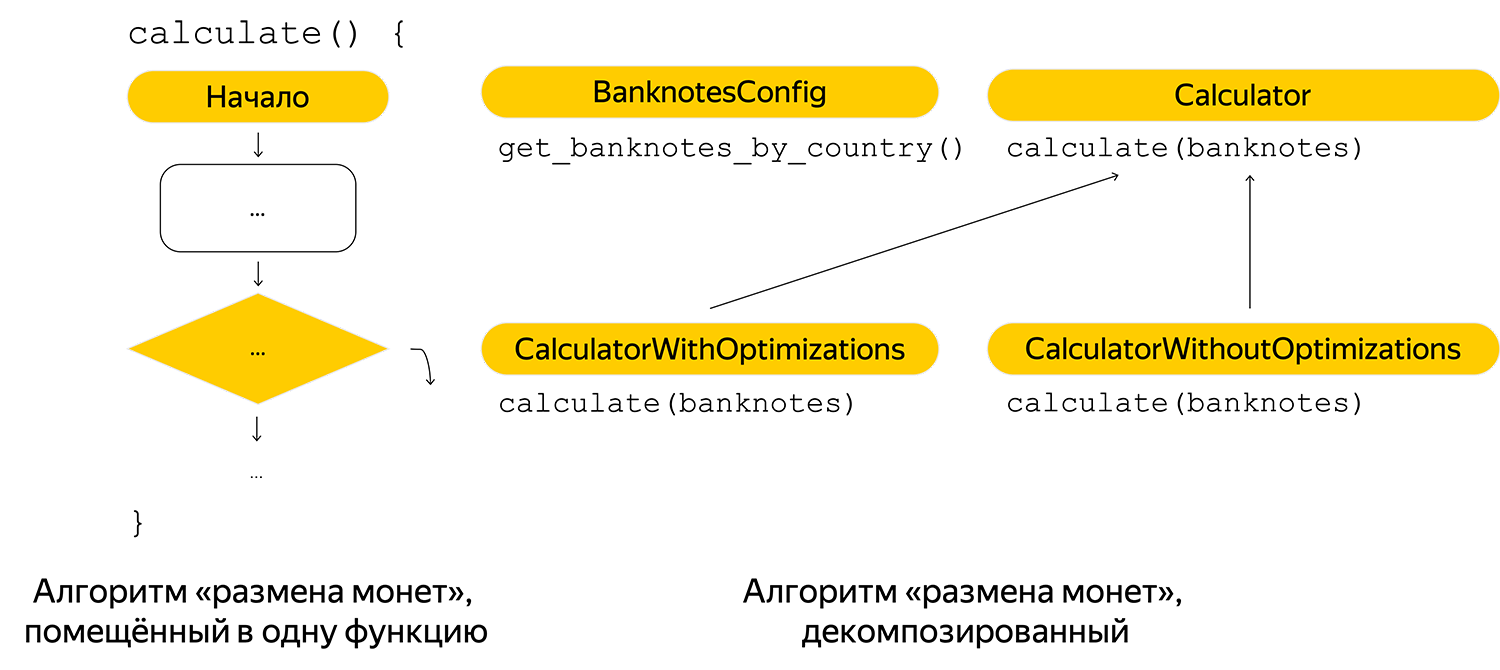
First of all, he made the minimum decomposition of the algorithm, and he was hard-wired to receive banknotes. In the first implementation, possible banknotes were registered in the code, therefore, they were taken out to the config by country.
Added comments for the future, so that any reader can quickly figure out the algorithm:
for exception in self.exceptions[banknote]: exc_value = value + exception.delta if exc_value - cost >= banknote: continue if exc_value > cost >= exception.banknote: banknote_results.append(exc_value) # for exception in self.exceptions[banknote]: # # exc_value = value + exception.delta # # (corner case) if exc_value - cost >= banknote: continue if exc_value > cost >= exception.banknote: banknote_results.append(exc_value)
Well, of course, I spent the rest of the time covering the entire code with tests.
RUB = [1, 2, 5, 10, 50, 100, 200, 500, 1000, 2000, 5000] CUSTOM_BANKNOTES = [1, 3, 7, 11] @pytest.mark.parametrize( 'cost, banknotes, expected_changes', [ # no banknotes ( 321, [], [], ), # zero cost ( 0, RUB, [], ), # negative cost ( -13, RUB, [], ), # simple testcase ( 264, RUB, [265, 270, 300, 400, 500, 1000, 2000, 5000], ), # cost bigger than max banknote ( 6120, RUB, [6121, 6150, 6200, 6300, 6500, 7000, 8000, 10000], ), # min cost ( 1, RUB, [2, 5, 10, 50, 100, 200, 500, 1000, 2000, 5000], ), ... ], )
In addition to the usual tests that run during each build of the project, he wrote a test that uses an algorithm without optimizations (consider - exhaustive search). The result of this algorithm for each bill from the first 10 thousand cases put in a file and ran separately on the algorithm with optimizations to be sure that it really works correctly.
Let's take a moment off from the stand-up and summarize the local results of everything that Ivan says. When writing code, the main goal is to ensure its performance. To achieve this goal, you must complete the following tasks:
- Decompose business logic into atomic fragments. Readability is complicated when viewing a canvas of code written in one function.
- Add comments to the "particularly complex" parts of the code. Our team has the following approach: if you are asked a question about the implementation on the code review (they ask to explain the algorithm), then you need to add a comment. Better yet, think about it in advance and add it yourself.
- Write tests covering the main branches of algorithm execution. Tests are not only a method for verifying code health. They still serve as an example of using your module.
Alas, even specialists with many years of experience do not always use these approaches in their work. At the backend development school that we are doing now, students will gain practical skills in writing architecturally high-quality code. Our other goal is to disseminate test coverage practices for the project.
But back to the stand-up. After Ivan, Anna speaks.
Anna:
I am developing a microservice for returning promotion images. As you remember, the service initially gave away static data-stubs. Then the testers asked to customize them, and I put them into the config, and now I am doing an “honest” implementation with the return of data from the database (PostgreSQL 10.9). The decomposition, originally laid down, helped me a lot, in the framework of which the interface for receiving data in business logic does not change, and each new source (whether it is a config, database or external microservice) only implements its own logic.Vadim:

I checked the written system under load, testing showed that the handle starts to brake sharply when we go to the database. According to explain, I saw that the index is not used. Until I figured out how to fix it.
And what kind of request?Anya:
Two conditions under OR:Vadim:
SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_2.attr1 = 'val' OR table_1.attr2 IN ('val1', 'val2')) AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at
The query explain showed that it does not use one of the indices for the attr1 attributes of table_2 and attr2 of table_1.
Faced with a similar behavior in MySQL, the problem is precisely in the condition for OR, because of which only one index is used, say attr2. And the second condition uses seq scan - a full pass through the table. The request can be divided into two independent requests. As an option, split and freeze the query result on the backend side. But then you need to think about wrapping these two requests in a transaction, or combining them with UNION - in fact, on the base side:Anya:
SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_2.attr1 = 'val') AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_1.attr2 IN ('val1' , 'val2')) AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at
Thanks, I'll try ^ _ ^
To summarize again:
- Almost all product development tasks are related to obtaining records from external sources (services or databases). You need to carefully approach the issue of decomposition of classes that unload data. Properly designed classes will allow you to write tests and modify data sources without problems.
- To work effectively with the database, you need to know the features of query execution, for example, understand explain.
Working with information and organizing data flows is an integral part of the tasks of any backend developer. The school will introduce the architecture of the interaction of services (and data sources). Students will learn to work with databases architecturally and in terms of operation - data migration and testing.
The last to speak is Vadim.
Vadim:
I was on duty for a week, sorted out the sequence of incidents. One ridiculous mistake in the code took a very long time: there were no logs on demand in the prod, although their creation was written in the code.
By the mournful silence of all those present, it is understandable - everyone already somehow faced the problem .
To get all the logs as part of the request, request_id is used, which is thrown into all entries in the following form:
# request_id logger.info( 'my log msg', ) # request_id logger.info( 'my log msg', extra=log_extra, # request_id — )
log_extra is a dictionary with meta-information of the request, the keys and values of which will be written to the log. Without passing log_extra to the logging function, the record will not be associated with all other logs, because it will not have request_id.
I had to fix the error in the service, re-roll it and only then deal with the incident. This is not the first time this has happened. To prevent this from happening again, I tried to fix the problem globally and get rid of log_extra.
First I wrote a wrapper over the standard execution of the request:
async def handle(self, request, handler): log_extra = request['log_extra'] log_extra_manager.set_log_extra(log_extra) return await handler(request)
It was necessary to decide how to store log_extra in a single request. There were two options. The first is to change task_factory for eventloop from asyncio:
class LogExtraManager: __init__(self, context: Any, settings: typing.Optional[Dict[str, dict]], activations_parameters: list) -> None: loop = asyncio.get_event_loop() task_factory = loop.get_task_factory() if task_factory is None: task_factory = _default_task_factory @functools.wraps(task_factory) def log_extrad_factory(ev_loop, coro): child_task = task_factory(ev_loop, coro) parent_task = asyncio.Task.current_task(loop=ev_loop) log_extra = getattr(parent_task, LOG_EXTRA_CONTEXT_KEY, None) setattr(child_task, LOG_EXTRA_CONTEXT_KEY, log_extra) return child_task # updating loop, so any created task will # get the log_extra of its parent loop.set_task_factory(log_extrad_factory) def set_log_extra(log_extra: dict): loop = asyncio.get_event_loop() task = asyncio.Task.current_task(loop=loop) setattr(task, LOG_EXTRA_CONTEXT_KEY, log_extra)
The second option is to “push” the transition to Python 3.7 through the infrastructure command to use contextvars :
log_extra_var = contextvars.ContextVar(LOG_EXTRA_CONTEXT_KEY) class LogExtraManager: def set_log_extra(log_extra: dict): log_extra_var.set(log_extra)
Well and further it was necessary to forward stored in the context of log_extra in logger.
class LogExtraFactory(logging.LogRecord): # this class allows to create log rows with log_extra in the record def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) task = asyncio.Task.current_task() log_extra = getattr(task, LOG_EXTRA_CONTEXT_KEY, None) if not log_extra: return for key in log_extra: self.__dict__[key] = log_extra[key] logging.setLogRecordFactory(LogExtraFactory)
Summary:
- In Yandex.Taxi (and everywhere in Yandex) asyncio is actively used. It is important not only to be able to use it, but also to understand its internal structure.
- Develop the habit of reading the changelogs of all new versions of the language, think about how you can make life easier for yourself and your colleagues with the help of innovations.
- When working with standard libraries, do not be afraid to crawl into their source code and understand their device. This is a very useful skill that will allow you to better understand the operation of the module and open up new possibilities in the implementation of features.
The teachers of the Backend School ate more than a pound of salt and filled a lot of cones in the asynchronous operation of services. They will tell students about the features of Python's asynchronous operation - both at the practical level and in the analysis of package internals.
Books and links
Learning Python can help you:
- Three books: Python Cookbook , Diving Into Python 3, and Python Tricks .
- Video lectures by IT industry pillars like Raymond Hettinger and David Beasley. From the video lectures of the first one, the report “Beyond PEP 8 - Best practices for beautiful intelligible code” can be distinguished. Beasley advises you to watch a performance about asyncio.
To gain a higher level understanding of architecture, read the books:
- "Highly loaded applications . " Here, the issues of interacting with data are described in detail (data encoding, work with distributed data, replication, partitioning, transactions, etc.).
- “Microservices. Development and refactoring patterns . " The book shows the main approaches to microservice architecture, describes the shortcomings and problems that one has to face when switching from a monolith to microservices. There is almost nothing in the post about them, but still I advise you to read this book. You will begin to understand the trends in building architectures and learn the basic practices of code decomposition.
Another of the most important skills that you can endlessly develop in yourself is reading someone else’s code. If you suddenly realize that you rarely read someone else’s code, I advise you to develop the habit of regularly watching new popular repositories .
The stand-up was over, everyone went to work.
All Articles