Personalize it: how we work with QIWI recommendations
Hello!
My name is Lydia, I am the team lead of a small DataScience team in QIWI.
My guys quite often face the task of researching customer needs, and in this post I would like to share thoughts on how to start a topic with segmentation and what approaches can help to understand the sea of unallocated data.
Who will surprise with personalization now? The lack of personal offers in a product or service already seems like a bad man, and we are waiting for the same cream selected only for us everywhere from a Instagram feed to a personal tariff plan.
However, where does that content or offer come from? If this is your first time immersing yourself in the dark waters of machine learning, you will surely come across the question of where to start and how to identify the very interests of the client. Most often, if there is a large user base and lack of knowledge about them, there is a desire to go in two popular ways:
1. Manually mark the sample of users and train on it a model that allows you to determine whether this class or classes belong to - in the case of a multiclass target.
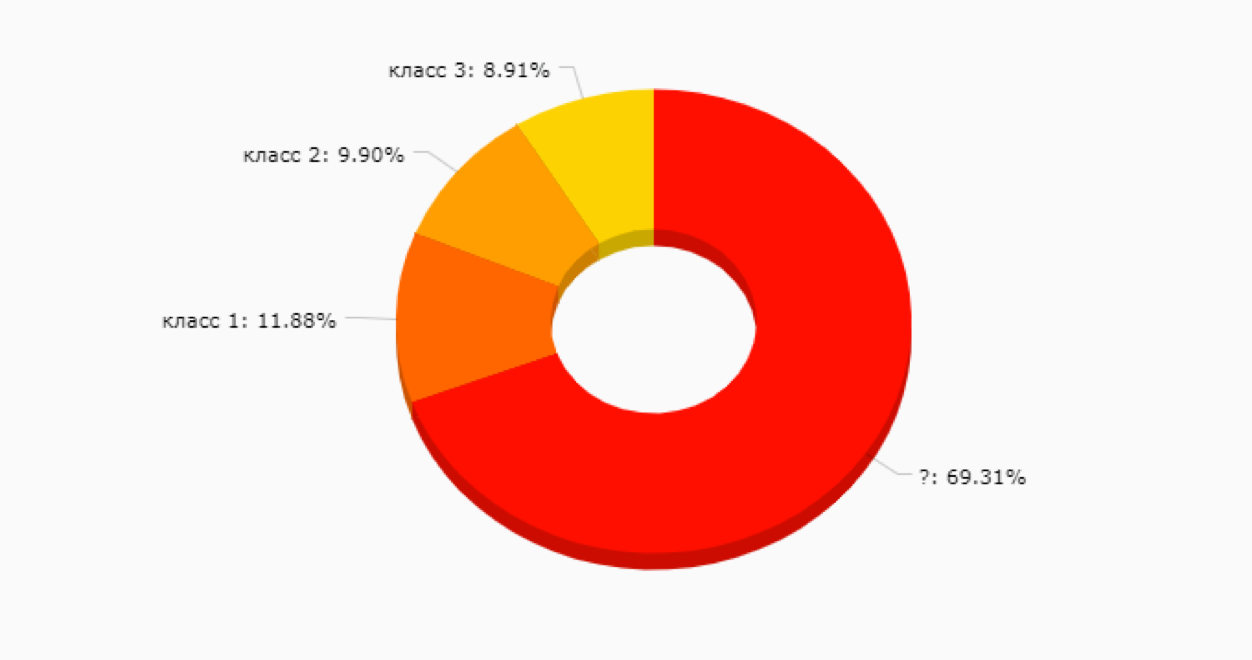
This is a good option, but at the initial stage it can be a trap - after all, we still do not know what segments we have in principle and how useful they will be for promoting new product features, communications, and more. Not to mention the fact that manual client markup is quite expensive and sometimes difficult, because the more services you have, the more data you need to look through to understand how this client lives and breathes. It is very likely that something like this will turn out:
2. Having burned themselves on option # 1, they often choose the option of unsupervised analysis without a training sample.
If you leave out jokes about the effectiveness of kmeans, then there is one important point that combines all clustering methods without training - they simply allow you to combine customers based on proximity by selected metrics. For example, the number of purchases, the number of days of life, balance, and more.
This can also be useful if you want to divide your audience into large groups and then study each, or highlight the core and segments lagging behind product metrics.
For example, in a two-dimensional space, a useful result may look like this - you can immediately see which clusters are worth exploring in more detail.

But the more metrics you used for clustering, the more difficult it will be to interpret the result. And those same customer preferences are still shrouded in mystery.
What to do, here's the question? At QIWI, we have repeatedly racked our brains over this dilemma until we come to a curious model inspired by this article . Among other cases, the article described the decision from Konstantin Vorontsov to highlight latent patterns of behavior of bank card users based on the BigARTM library .
The bottom line is that client transactions were presented as a set of words and then from the resulting text collection, where document = client, and words = MCC codes (merchant category code, international classification of outlets), text topics were allocated using one of the Natural Language Processing tools ( NLP) - thematic modeling .
In our performance, the pipeline looks like this:

It sounds absolutely natural - if we want to understand how and how our audience lives, why not imagine the actions that customers perform inside our ecosystem as a story told by them. And make a guide to the topics of these stories.
Despite the fact that the concept looks elegant and simple, in practice, when implementing the model, I had to face several problems:
For the first problem, the solution was found quite easily - all major clients were divided by the simplest classifier into “core” and “stars” (see the picture above) and already each of the clusters was processed as a separate text collection.
But the second and third points made me wonder - really, how to validate learning outcomes without a training sample? Of course, there are quality metrics for the model, but it seems that they are not enough - and that is why we decided to do a very simple thing - to check the results on the same source data.
This check looks as follows: the classification results in a set of topics, for example, this one:

Here the Python list is a set of the most likely key MCC categories of purchases for this topic (from the matrix “word - subject”). If you look separately at purchases in the airline and air carriers category, it is quite logical that customers with the theme “travelers” will make up the bulk of its users.

And this check is conveniently implemented in the form of a dashboard - at the same time you will have visual material for generating product hypotheses - who has cashback for flights, and who has a discount on coffee.
And in the collection for thematic modeling, you can add not only transactional events, but also meta information from other models, topics of customer support calls and much more. Or use as categorical features for supervised algorithms - for example, models of outflow prediction and so on.
Of course, this approach has its own nuances - for example, the collection is processed as bag of words and the order of purchases is not taken into account, but it can be completely compensated by using N grams or calculating thematic tags for each significant period of the client’s life (every month, for example). However, the very idea of a readable and interpretable customer story, a combination of NLP and other models seems very attractive to us.
How do you like this topic? What difficulties or joys of segmentation does your data science team face? It will be interesting to know your opinion.
My name is Lydia, I am the team lead of a small DataScience team in QIWI.
My guys quite often face the task of researching customer needs, and in this post I would like to share thoughts on how to start a topic with segmentation and what approaches can help to understand the sea of unallocated data.
Who will surprise with personalization now? The lack of personal offers in a product or service already seems like a bad man, and we are waiting for the same cream selected only for us everywhere from a Instagram feed to a personal tariff plan.
However, where does that content or offer come from? If this is your first time immersing yourself in the dark waters of machine learning, you will surely come across the question of where to start and how to identify the very interests of the client. Most often, if there is a large user base and lack of knowledge about them, there is a desire to go in two popular ways:
1. Manually mark the sample of users and train on it a model that allows you to determine whether this class or classes belong to - in the case of a multiclass target.
This is a good option, but at the initial stage it can be a trap - after all, we still do not know what segments we have in principle and how useful they will be for promoting new product features, communications, and more. Not to mention the fact that manual client markup is quite expensive and sometimes difficult, because the more services you have, the more data you need to look through to understand how this client lives and breathes. It is very likely that something like this will turn out:
2. Having burned themselves on option # 1, they often choose the option of unsupervised analysis without a training sample.
If you leave out jokes about the effectiveness of kmeans, then there is one important point that combines all clustering methods without training - they simply allow you to combine customers based on proximity by selected metrics. For example, the number of purchases, the number of days of life, balance, and more.
This can also be useful if you want to divide your audience into large groups and then study each, or highlight the core and segments lagging behind product metrics.
For example, in a two-dimensional space, a useful result may look like this - you can immediately see which clusters are worth exploring in more detail.
But the more metrics you used for clustering, the more difficult it will be to interpret the result. And those same customer preferences are still shrouded in mystery.
What to do, here's the question? At QIWI, we have repeatedly racked our brains over this dilemma until we come to a curious model inspired by this article . Among other cases, the article described the decision from Konstantin Vorontsov to highlight latent patterns of behavior of bank card users based on the BigARTM library .
The bottom line is that client transactions were presented as a set of words and then from the resulting text collection, where document = client, and words = MCC codes (merchant category code, international classification of outlets), text topics were allocated using one of the Natural Language Processing tools ( NLP) - thematic modeling .
In our performance, the pipeline looks like this:
It sounds absolutely natural - if we want to understand how and how our audience lives, why not imagine the actions that customers perform inside our ecosystem as a story told by them. And make a guide to the topics of these stories.
Despite the fact that the concept looks elegant and simple, in practice, when implementing the model, I had to face several problems:
- the presence of outliers and anomalies in the data and, as a result, a shift in the subjects towards the categories of purchases of customers with high turnover
- the correct determination of the number of topics N,
- a question of validation of results (is this possible in principle?)
For the first problem, the solution was found quite easily - all major clients were divided by the simplest classifier into “core” and “stars” (see the picture above) and already each of the clusters was processed as a separate text collection.
But the second and third points made me wonder - really, how to validate learning outcomes without a training sample? Of course, there are quality metrics for the model, but it seems that they are not enough - and that is why we decided to do a very simple thing - to check the results on the same source data.
This check looks as follows: the classification results in a set of topics, for example, this one:
Here the Python list is a set of the most likely key MCC categories of purchases for this topic (from the matrix “word - subject”). If you look separately at purchases in the airline and air carriers category, it is quite logical that customers with the theme “travelers” will make up the bulk of its users.
And this check is conveniently implemented in the form of a dashboard - at the same time you will have visual material for generating product hypotheses - who has cashback for flights, and who has a discount on coffee.
And in the collection for thematic modeling, you can add not only transactional events, but also meta information from other models, topics of customer support calls and much more. Or use as categorical features for supervised algorithms - for example, models of outflow prediction and so on.
Of course, this approach has its own nuances - for example, the collection is processed as bag of words and the order of purchases is not taken into account, but it can be completely compensated by using N grams or calculating thematic tags for each significant period of the client’s life (every month, for example). However, the very idea of a readable and interpretable customer story, a combination of NLP and other models seems very attractive to us.
How do you like this topic? What difficulties or joys of segmentation does your data science team face? It will be interesting to know your opinion.
All Articles