Updating statistics on secondary replicas of Availability Group
We all love and use the amazing Availability Group features on secondary replicas, such as integrity checks, backups, etc.
In fact, the impossibility of storing this information in a database on a replica is still a headache (and think about things like CDC for even more discomfort).
But stop complaining, here is the main idea: dear Microsoft, let us use our cues to update statistics ... well, and do a lot more on them.
*almost always
Let's list the known basic details of a possible solution on Enterprise Edition MS SQL Server:
I have a test AG on a pair of virtual machines with SQL Server 2017 (you can use any version) and I will create a simple table in which I want to update the statistics.
Here is a script to create a table and insert a million rows into it:
Now let's create the ST_SampleDataTable_C2 statistics for column c2
And then I will insert 1000 rows, which will be very important and because of which I really need to update the statistics.
Now I have 1000 entries in which, in column C2, the value is 999999999. And this definitely means the Ascending Key Problem and I really need to update the statistics ... on the replica so that I don’t strain the main server with calculations and prevented him from serving customers.
Using the good old DBCC SHOW_STATISTICS command, let's examine our statistics.
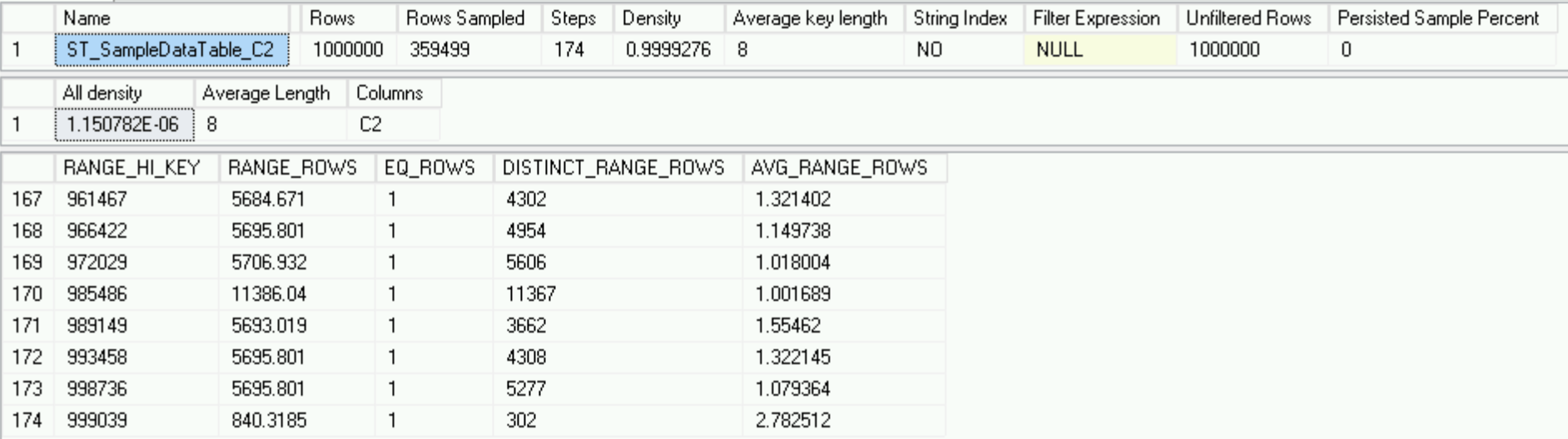
Everything is perfect in our kingdom and our statistics are in perfect order, although it only takes into account 1 million lines and there is no that harmful thousand lines, which, ultimately, should become part of these statistics.
Also, we can see the statistics stream using the STATS_STREAM parameter of the DBCC SHOW_STATISTICS command:

It’s just a character set that blogs have been writing about for years, but I'm still not sure if this is a fully documented feature (although it never stopped people from using it).
Let's copy our table on a replica to tempdb (although my AG is in synchronous mode, the same thing can be done in asynchronous, just the data can come with a slight delay).
Now we are ready to update the statistics with a full scan in tempdb on the replica.
( Translator's note - Nico forgot to create statistics, and uses the incorrect syntax of the UPDATE STATISTICS operation, instead of UPDATE it should be CREATE, i.e. the statistics are not updated, but created )
Go back to DBCC SHOW_STATISTICS and look at it:
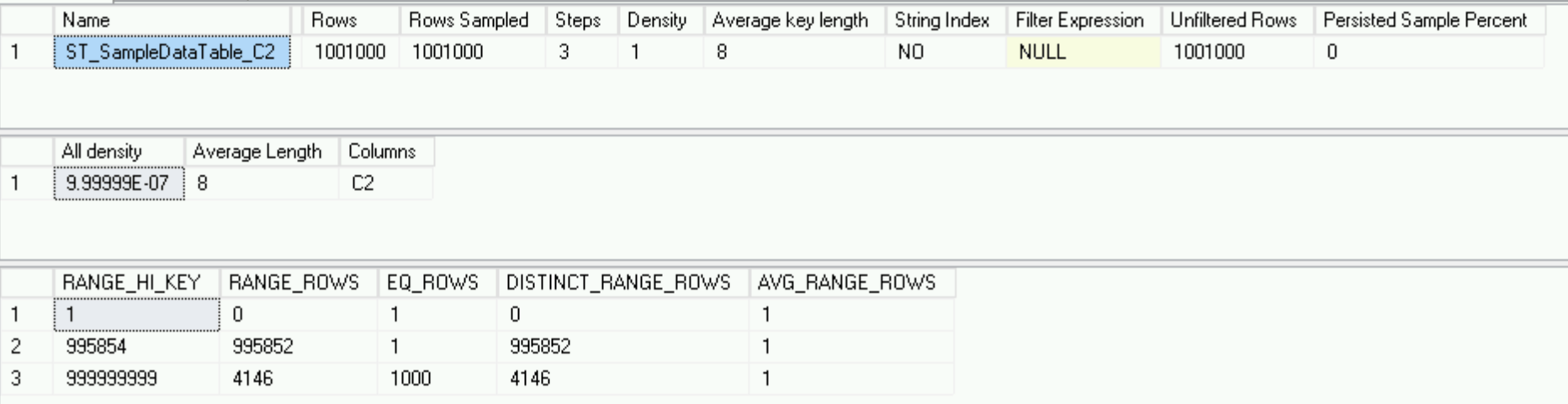
It looks completely different from what it was on the main server - only 3 lines versus 178, but it describes the data perfectly - we have a million unique lines and 1000 lines with the same C2 column value - the histogram is as good as possible .
Let's look at the statistics flow:

You don’t need to be a genius to notice that the stream looks completely different - we see the 5689A0C6 characters in the updated stream, while in the original, between all these zeros we saw EDF10EB4.
Let's concentrate on exporting this data to a text file somewhere outside of SQL Server and do it with the help of the wonderful BCP command, which requires CMDSHELL to be enabled (note: you probably don’t want this on your production server):
And here is how big the stats.txt file will be in our ball:

Just a couple kilobytes! Easy to transmit, easy to manage.
On the main server, we will need to create a temporary table that will store the statistics stream before we can update statistics from it in our main SampleDataTable table (in practice, we can expand this table for many databases, tables, statistics).
Let's import the data from our text file into our new temporary table and see what we imported:

We can see the same data that we calculated on the replica, but this data is already on our main server and all that remains for us to do is update our statistics from them in the table. This operation can be performed using the UPDATE STATISTICS operation using the WITH STATS_STREAM = ... parameter
This script reads the imported value above (yes, I know - I did this example for one table and did not bother with multiple statistics, tables, databases, etc.), generates an UPDATE STATISTICS statement, displays it on the screen and, in the end, fulfills it.
Here is what I get in the output:
Running DBCC SHOW_STATISTICS on the main server gives me the very result I was hoping for - the same as what we saw on the replica. The circle is closed.
The really awesome part of this story is that the size of the object with statistics is very small and we can transfer it to the main server very easily / instantly.
If you have several AGs between the same replicas, where one replica is the main in one AG and the other is the main in the second, then you can insert BLOB data into the data stream between the replicas and add a tiny database with the transmitted data.
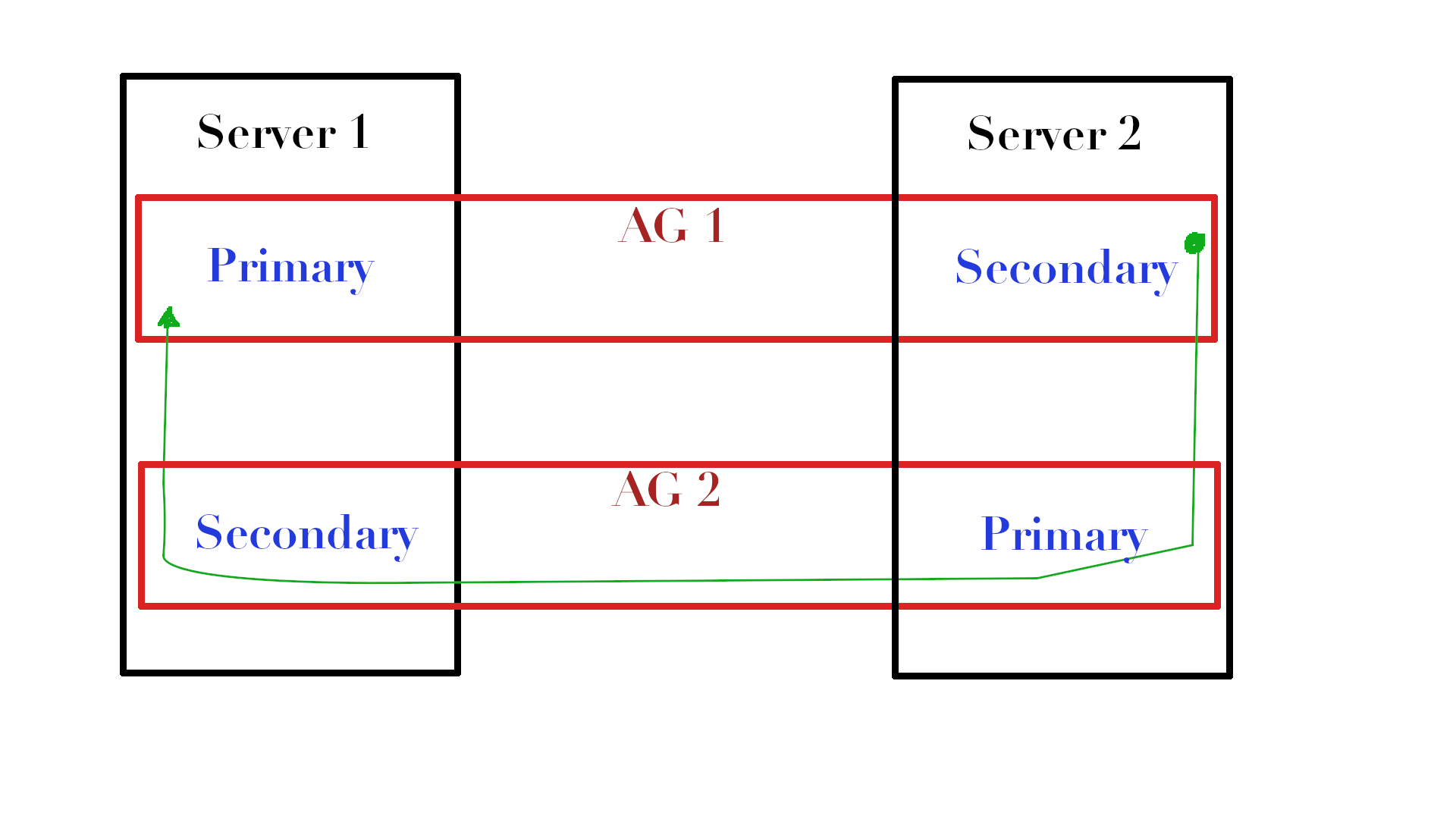
Look at the picture. If we have two AGs (AG1 & AG2) that are located on different servers and we have a specific table on Server1 in AG1 for which we want to update statistics, then on Server2 we can copy this table (let's call it dbo.MyTable ) in tempdb, update, and, using AG2, send the object with the statistics stream back to Server1, where you simply import the statistics from this stream into the statistics we need.
Yes, I know, it sounds confusing, but just think of it as a feedback channel through which the results are delivered, instead of putting them on file balls.
You may have a few objections, for example:
This is a channel with feedback from the replica to the main server - after we pledged the transaction in the synchronous AG, the main server will wait for confirmation from the replica - and I think that this channel can be used to implement this improvement. Look at the picture that was taken in a post by Simon Su .
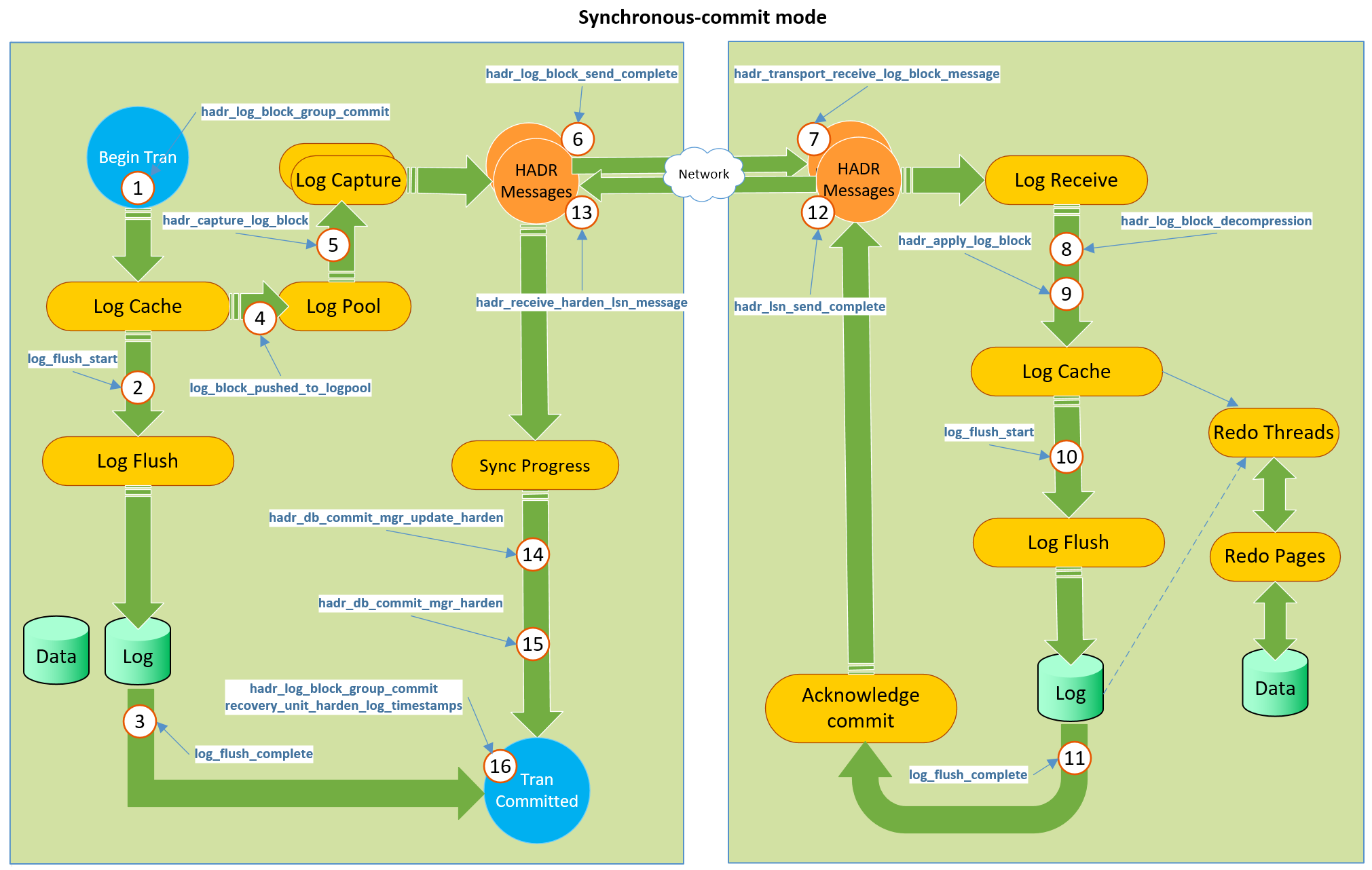
Which represents the entire mechanism of the existing feedback channel. The replica, using step 12 and subsequent, confirms to the primary server that the information has been saved. The same channel can be used to send a statistics flow object after recounting on a replica. Of course, we will not have to use tempdb for this purpose, but create an in-memory object inside the database that should not be permanently stored (look at your In-Memory OLTP Schema-Only tables, or think about NOLOGGING tables in Oracle), and should be removed at the end of the operation - that would be really cool.
This should not depend on whether the synchronous replica or not - most of the time statistics are not updated every couple of seconds and this leads us to the second part of the idea - to make a call to update statistics on the main server with a parameter such as
where the SECONDARY parameter indicates where the operation is to be performed.
And just like with backups, we should be able to specify the preferred replica to perform UPDATE STATISTICS (or any other operation in the future) in the settings.
I am sure that this feature will encourage many Enterprise Edition users to migrate to the new version of SQL Server, which will allow distributing heavy operations between replicas.
As for the current situation - I see for sure how this solution can be automated using Powershell.
Microsoft, it's your turn! ;)
Vote for the proposed feature here .
Translator's Note: Any suggestions and comments regarding translation and style are welcome, as usual.
I usually called primary replica in translation “primary server”, and secondary replica - simply a replica. Perhaps this is not entirely correct, but my ear hurts less than the "primary" and "secondary" replicas on msdn.
In fact, the impossibility of storing this information in a database on a replica is still a headache (and think about things like CDC for even more discomfort).
But stop complaining, here is the main idea: dear Microsoft, let us use our cues to update statistics ... well, and do a lot more on them.
There is always * a way, or something
*almost always
Let's list the known basic details of a possible solution on Enterprise Edition MS SQL Server:
- we can make replicas readable and read data from them (not that you always had to do this, but if you really know what you are doing ...);
- we can copy our objects to Tempdb (yes, your multi-terabyte tables are probably not very suitable for such an operation), or to another database that is writable;
- we can write the results to a shared folder that is accessible to both replicas (let it be a text file in a file share);
- we can export statistics as a blob from SQL Server;
- we can import the downloaded blob into the statistics.
let's do that
I have a test AG on a pair of virtual machines with SQL Server 2017 (you can use any version) and I will create a simple table in which I want to update the statistics.
Here is a script to create a table and insert a million rows into it:
DROP TABLE IF EXISTS dbo.SampleDataTable; CREATE TABLE dbo.SampleDataTable ( C1 BIGINT NOT NULL, C2 BIGINT NOT NULL, CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1) ); INSERT INTO dbo.SampleDataTable WITH (TABLOCK) SELECT t.RN, t.RN FROM ( SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM sys.objects t1 CROSS JOIN sys.objects t2 CROSS JOIN sys.objects t3 CROSS JOIN sys.objects t4 CROSS JOIN sys.objects t5 ) t OPTION (MAXDOP 1);
Now let's create the ST_SampleDataTable_C2 statistics for column c2
CREATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2);
And then I will insert 1000 rows, which will be very important and because of which I really need to update the statistics.
set nocount on; INSERT INTO dbo.SampleDataTable WITH (TABLOCK) SELECT 10000000 + t.RN, 999999999 FROM ( SELECT TOP (1000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM sys.objects t1 CROSS JOIN sys.objects t2 CROSS JOIN sys.objects t3 CROSS JOIN sys.objects t4 CROSS JOIN sys.objects t5 ) t OPTION (MAXDOP 1);
Now I have 1000 entries in which, in column C2, the value is 999999999. And this definitely means the Ascending Key Problem and I really need to update the statistics ... on the replica so that I don’t strain the main server with calculations and prevented him from serving customers.
Using the good old DBCC SHOW_STATISTICS command, let's examine our statistics.
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')
Everything is perfect in our kingdom and our statistics are in perfect order, although it only takes into account 1 million lines and there is no that harmful thousand lines, which, ultimately, should become part of these statistics.
Also, we can see the statistics stream using the STATS_STREAM parameter of the DBCC SHOW_STATISTICS command:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;
It’s just a character set that blogs have been writing about for years, but I'm still not sure if this is a fully documented feature (although it never stopped people from using it).
On the cue
Let's copy our table on a replica to tempdb (although my AG is in synchronous mode, the same thing can be done in asynchronous, just the data can come with a slight delay).
use TempDB; DROP TABLE IF EXISTS dbo.SampleDataTable; CREATE TABLE dbo.SampleDataTable ( C1 BIGINT NOT NULL, C2 BIGINT NOT NULL, CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1) ); INSERT INTO dbo.SampleDataTable SELECT C1, C2 FROM AvGroupDb.dbo.SampleDataTable;
Now we are ready to update the statistics with a full scan in tempdb on the replica.
use TempDB; UPDATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2) WITH FULLSCAN;
( Translator's note - Nico forgot to create statistics, and uses the incorrect syntax of the UPDATE STATISTICS operation, instead of UPDATE it should be CREATE, i.e. the statistics are not updated, but created )
Go back to DBCC SHOW_STATISTICS and look at it:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')
It looks completely different from what it was on the main server - only 3 lines versus 178, but it describes the data perfectly - we have a million unique lines and 1000 lines with the same C2 column value - the histogram is as good as possible .
Let's look at the statistics flow:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;
You don’t need to be a genius to notice that the stream looks completely different - we see the 5689A0C6 characters in the updated stream, while in the original, between all these zeros we saw EDF10EB4.
Let's concentrate on exporting this data to a text file somewhere outside of SQL Server and do it with the help of the wonderful BCP command, which requires CMDSHELL to be enabled (note: you probably don’t want this on your production server):
EXEC xp_cmdshell 'BCP "DBCC SHOW_STATISTICS(''AvGroupDb.dbo.SampleDataTable'', ''ST_SampleDataTable_C2'') WITH STATS_STREAM" queryout \\SharedServer\Tempdb\stats.txt -c -T';
And here is how big the stats.txt file will be in our ball:
Just a couple kilobytes! Easy to transmit, easy to manage.
Back to the main server
On the main server, we will need to create a temporary table that will store the statistics stream before we can update statistics from it in our main SampleDataTable table (in practice, we can expand this table for many databases, tables, statistics).
CREATE TABLE dbo.TempStats( Stats_Stream VARBINARY(MAX), Rows BIGINT, DataPages BIGINT );
Let's import the data from our text file into our new temporary table and see what we imported:
BULK INSERT dbo.TempStats FROM '\\SharedServer\Tempdb\stats.txt' SELECT * FROM dbo.TempStats;
We can see the same data that we calculated on the replica, but this data is already on our main server and all that remains for us to do is update our statistics from them in the table. This operation can be performed using the UPDATE STATISTICS operation using the WITH STATS_STREAM = ... parameter
DECLARE @script NVARCHAR(MAX) SELECT @script = 'UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM = ' + CONVERT(nvarchar(max), [Stats_Stream],1) FROM dbo.TempStats PRINT @script; EXECUTE sp_executesql @script;
This script reads the imported value above (yes, I know - I did this example for one table and did not bother with multiple statistics, tables, databases, etc.), generates an UPDATE STATISTICS statement, displays it on the screen and, in the end, fulfills it.
Here is what I get in the output:
UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM =
Running DBCC SHOW_STATISTICS on the main server gives me the very result I was hoping for - the same as what we saw on the replica. The circle is closed.
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2');
The really awesome part of this story is that the size of the object with statistics is very small and we can transfer it to the main server very easily / instantly.
Not so basic scenario.
If you have several AGs between the same replicas, where one replica is the main in one AG and the other is the main in the second, then you can insert BLOB data into the data stream between the replicas and add a tiny database with the transmitted data.
Look at the picture. If we have two AGs (AG1 & AG2) that are located on different servers and we have a specific table on Server1 in AG1 for which we want to update statistics, then on Server2 we can copy this table (let's call it dbo.MyTable ) in tempdb, update, and, using AG2, send the object with the statistics stream back to Server1, where you simply import the statistics from this stream into the statistics we need.
Yes, I know, it sounds confusing, but just think of it as a feedback channel through which the results are delivered, instead of putting them on file balls.
Place for doubt
You may have a few objections, for example:
- why should I do this on a replica if I can safely do it on the main server? (well, the idea is to offload the main server)
- but don’t we, potentially, load the replica (yes, but if it is idle, that is why we want to use its power)
- and we can’t act on the main server somehow? (no, we just read the data from the replica and send back a couple of kilobytes, which in our century gigabytes and terabytes sounds like "shtoa?") ( Note translator - in general, just in case of readable replica AG, we can )
- What if in the middle of the process the main server starts updating the statistics on its own? (in this case, it can either interrupt the second process, or restart with the updated data).
AG Feedback Channel
This is a channel with feedback from the replica to the main server - after we pledged the transaction in the synchronous AG, the main server will wait for confirmation from the replica - and I think that this channel can be used to implement this improvement. Look at the picture that was taken in a post by Simon Su .
Which represents the entire mechanism of the existing feedback channel. The replica, using step 12 and subsequent, confirms to the primary server that the information has been saved. The same channel can be used to send a statistics flow object after recounting on a replica. Of course, we will not have to use tempdb for this purpose, but create an in-memory object inside the database that should not be permanently stored (look at your In-Memory OLTP Schema-Only tables, or think about NOLOGGING tables in Oracle), and should be removed at the end of the operation - that would be really cool.
General thoughts
This should not depend on whether the synchronous replica or not - most of the time statistics are not updated every couple of seconds and this leads us to the second part of the idea - to make a call to update statistics on the main server with a parameter such as
UPDATE STATISTICS dbo.MyAwesomeTable(HugeImportantStatOnC17) WITH FULLSCAN, SECONDARY
where the SECONDARY parameter indicates where the operation is to be performed.
And just like with backups, we should be able to specify the preferred replica to perform UPDATE STATISTICS (or any other operation in the future) in the settings.
I am sure that this feature will encourage many Enterprise Edition users to migrate to the new version of SQL Server, which will allow distributing heavy operations between replicas.
As for the current situation - I see for sure how this solution can be automated using Powershell.
Microsoft, it's your turn! ;)
Vote for the proposed feature here .
Translator's Note: Any suggestions and comments regarding translation and style are welcome, as usual.
I usually called primary replica in translation “primary server”, and secondary replica - simply a replica. Perhaps this is not entirely correct, but my ear hurts less than the "primary" and "secondary" replicas on msdn.
All Articles