Mutation testing in PHP: a qualitative measurement for code coverage
How to evaluate the quality of tests? Many rely on the most popular metric known to everyone - code coverage. But this is a quantitative, not a qualitative metric. It shows how much of your code is covered by tests, but not how well these tests are written.
One way to figure this out is by mutation testing. This tool, making small changes to the source code and re-running the tests after that, allows you to identify useless tests and low-quality coverage.
At the Badoo PHP Meetup in March, I talked about how to organize mutational testing for PHP code and what problems you might encounter. The video is available here , and for the text version, welcome to cat.
To explain what I mean, I'll show you a couple of examples. They are simple, exaggerated in places and may seem obvious (although real examples are usually quite complex and cannot be seen with their eyes).
Consider the situation: we have an elementary function that claims to be an adult, and there is a test that tests it. The test has a dataProvider, that is, it tests two cases: age 17 years and age 19 years. I think it’s obvious to many of you that isAdult has 100% coverage. The only line. It is performed by a test. Everything is great.

But upon closer inspection, it turns out that our provider is poorly written and does not test boundary conditions: the age of 18 is not tested as a boundary condition. You can replace the> sign with> =, and the test will not catch such a change.
Another example, a little more complicated. There is a function that builds some simple object containing setters and getters. We have three fields that we set, and there is a test that checks that the buildPromoBlock function really collects the object that we expect.

If you look closely, we also have setSomething, which sets some property to true. But in the test we don’t have such an assert. That is, we can remove this line from buildPromoBlock - and our test will not catch this change. At the same time, we have 100% coverage in the buildPromoBlock function, because all three lines were executed during the test.
These two examples lead us to what mutation testing is.
Before disassembling the algorithm, I will give a short definition. Mutation testing is a mechanism that allows us, making minor changes to the code, to imitate the actions of the evil Pinocchio or Junior Vasya, who came and began to break it purposefully, replace the> characters with <, = by! =, And so on. For each such change we make for good purposes, we run tests that should cover the changed row.
If the tests didn’t show us anything, if they didn’t fall, then they are probably not effective enough. They do not test boundary cases, do not contain assertions: perhaps they need to be improved. If the tests fall, then they are cool. They really protect against such changes. Therefore, our code is harder to break.
Now let's analyze the algorithm. It is quite simple. The first thing we do to perform mutation testing is to take the source code. Next, we get code coverage to know which tests to run for which string. After that, we go over the source code and generate the so-called mutants.
A mutant is a single code change. That is, we take a certain function where there was a> sign in comparison, in if, we change this sign to> = - and we get a mutant. After that we run the tests. Here is an example of a mutation (we replaced> with> =):

In this case, mutations are not made randomly, but according to certain rules. The mutation testing response is idempotent. No matter how many times we run mutational testing on the same code, it produces the same results.
The last thing we do is run the tests that cover the mutated line. Get it out of coverage. There are non-optimal tools that drive all the tests. But a good tool will drive away only those that are needed.
After that, we evaluate the result. Tests fell - then everything is fine. If they did not fall, then they are not very effective.
What metrics does mutation testing give us? It adds three more to code coverage, which we will talk about now.
But first, let's analyze the terminology.

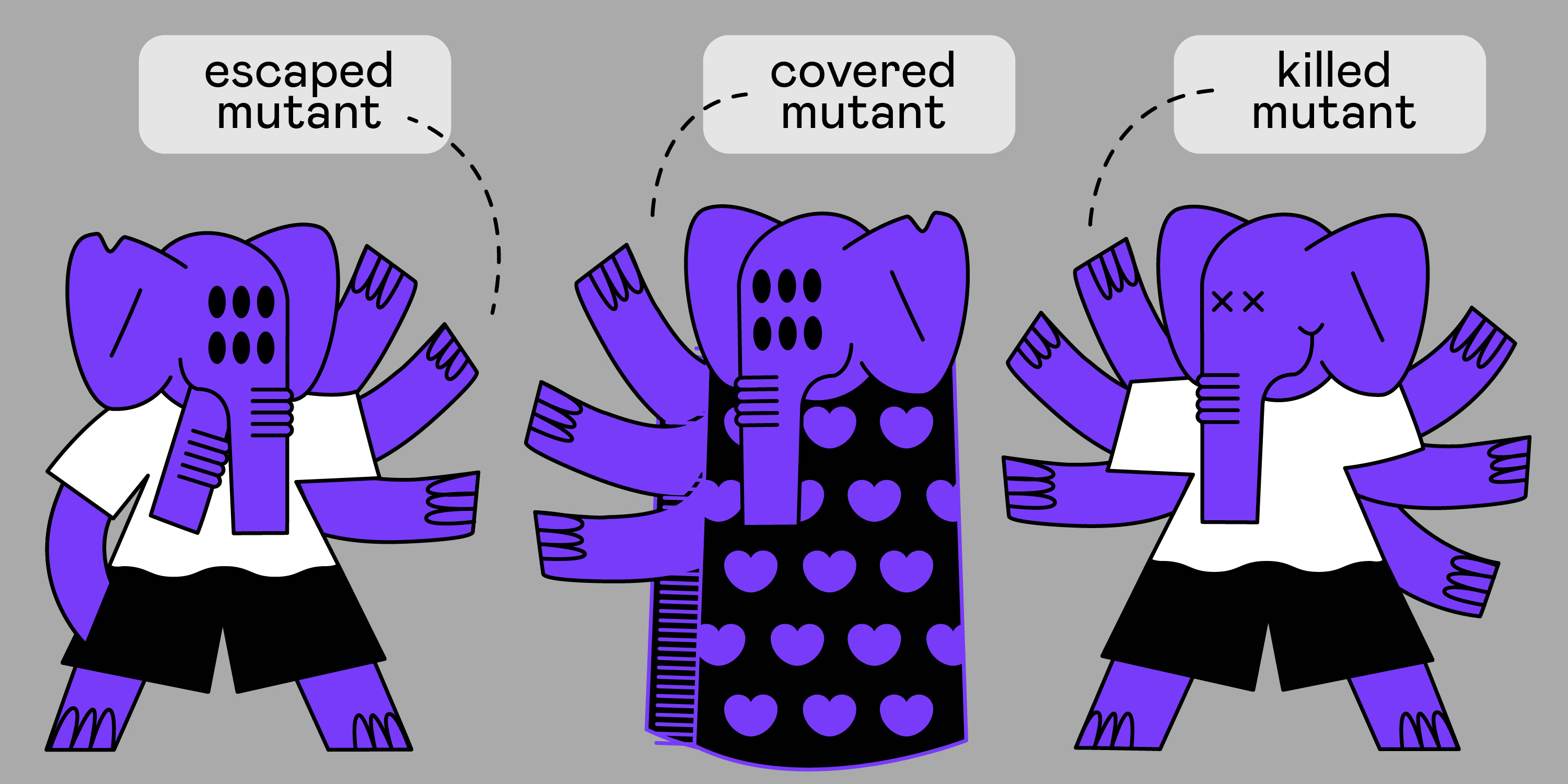
There is the concept of killed mutants: these are the mutants that our tests “nailed” (that is, they caught them).

There is the concept of escaped mutant (surviving mutants). These are the mutants who managed to avoid punishment (that is, the tests did not catch them).

And there are concepts covered mutant - a mutant covered by tests, and an uncovered reverse mutant that is not covered by any test at all (i.e. we have code, it has business logic, we can change it, but not a single test does not check for changes).
The main indicator that mutation testing gives us is the MSI (mutation score indicator), the ratio of the number of killed mutants to their total number.
The second indicator is mutation code coverage. It is just qualitative, not quantitative, because it shows how much business logic you can break and do it on a regular basis, our tests are caught.
And the last metric is covered MSI, i.e. a softer MSI. In this case, we calculate MSI only for those mutants that were covered by tests.
Why did less than half of the programmers hear about this tool? Why is it not used everywhere?
The first problem (one of the main ones) is the speed of mutation testing. In the code, if we have dozens of mutation operators, even for the simplest class, we can generate hundreds of mutations. For each mutation, you will need to run tests. If we have, say, 5,000 unit tests that run for ten minutes, mutational testing can take hours.
What can be done to level this? Run tests in parallel, in multiple threads. Throw streams into several cars. It works.
The second way is incremental runs. There is no need to count mutational indicators for the entire branch each time - you can take branch diff. If you use feature-brunches, it will be easy for you to do this: run tests only on those files that have changed, and see what is going on in the wizard, compare, analyze.
The next thing you can do is mutation tuning. Since mutation operators can be changed, you can set certain rules by which they work, then you can stop some mutations if they knowingly lead to problems.
An important point: mutational testing is only suitable for unit tests. Despite the fact that it can be run for integration tests, this is obviously a failed idea, because integration (like end-to-end) tests run much slower and affect much more code. You simply will never wait for the results. In principle, this mechanism was invented and developed exclusively for unit testing.
The second problem that can arise with mutation tests is the so-called endless mutants. For example, there is simple code, a simple for loop:

If you replace i ++ with i--, then the cycle will turn into an infinite. Your code will stick for a long time. And mutational testing quite often generates such mutations.
The first thing you can do is mutation tuning. Obviously, changing i ++ to i-- in a for loop is a very bad idea: in 99% of cases, we will end up with an infinite loop. Therefore, we have forbidden to do this in our tool.
The second and most important thing that will protect you from such problems is the timeout for the run. For example, the same PHPUnit has the ability to complete the test by timeout, regardless of where it is stuck. PHPUnit through PCNTL hangs up callbacks and calculates the time itself. If the test fails for a certain period, it simply nails it and such a case is considered a killed mutant, because the code that generated the mutations is really checked by a test that really catches the problem, indicating that the code has become inoperative.
This problem exists in the theory of mutation testing. In practice, it is not often encountered, but you need to know about it.
Consider a classic example illustrating it. We have a multiplication of variable A by -1 and division of A by -1. In the general case, these operations lead to the same result. We change the sign of A. Accordingly, we have a mutation that allows two signs to change among themselves. The logic of the program by such a mutation is not violated. Tests and should not catch it, should not fall. Due to such identical mutants, some difficulties arise.
There is no universal solution - everyone solves this problem in his own way. Perhaps some sort of mutant registration system will help. We at Badoo are thinking about something similar now, we will mimic them.
There are two well-known tools for mutational testing: Humbug and Infection. When I was preparing the article, I wanted to talk about which one is better and come to the conclusion that this is Infection.
But when I went to the Humbug page, I saw the following there: Humbug declared itself obsolete in favor of Infection. Therefore, part of my article turned out to be meaningless. So Infection is a really good tool. I must say thanks to borNfree from Minsk who created it. It really works cool. You can take it directly from the box, put it through and run it.
We really liked Infection. We wanted to use it. But they could not for two reasons. Infection requires code coverage to run tests for mutants correctly and precisely. Here we have two ways. We can calculate it directly in runtime (but we have 100,000 unit tests). Or we can calculate it for the current master (but the assembly on our cloud of ten very powerful machines in several threads takes an hour and a half). If we do this on every mutational run, the tool will probably not work.
There is an option to feed the finished one, but in the PHPUnit format, this is a bunch of XML files. In addition to the fact that it contains valuable information, they drag along a bunch of structure, some brackets and other things. I figured that in general, our code coverage will weigh about 30 GB, and we need to drag it across all the cloud machines, constantly read from disk. In general, the idea is so-so.
The second problem was even more significant. We have a wonderful SoftMocks library. It allows us to deal with legacy code, which is difficult to test, and successfully write tests for it. We are actively using it and are not going to refuse it in the near future, despite the fact that we are writing new code so that we do not need SoftMocks. So, this library is incompatible with Infection, because they use almost the same approach to mutating changes.
How do SoftMocks work? They intercept file inclusions and replace them with modified ones, that is, instead of executing class A, SoftMocks create class A in another place and connect another one instead of the original one. Infection acts in exactly the same way, only it works through stream_wrapper_register () , which does the same thing, but at the system level. As a result, either SoftMocks or Infection can work for us. Since SoftMocks are necessary for our tests, it is very difficult to make these two tools friends. This is probably possible, but in this case we get into Infection so much that the meaning of such changes is simply lost.
Overcoming difficulties, we wrote our little instrument. We borrowed mutation operators from Infection (they are cool written and very easy to use). Instead of starting mutations through stream_wrapper_register (), we run them through SoftMocks, that is, we use our tool from the box. Our toolza is friends with our internal code coverage service. That is, on demand it can receive coverage for a file or for a line without running all the tests, which happens very quickly. However, it is simple. If Infection has a bunch of all sorts of tools and features (for example, launching into multiple threads), then there is nothing like that in ours. But we use our internal infrastructure to mitigate this shortcoming. For example, we run the same test run in several threads through our cloud.
How do we use it?
The first is a manual run. This is the first thing to do. All tests that you write are manually verified by mutation testing. It looks something like this:

I ran a mutation test for some file. Got the result: 16 mutants. Of these, 15 were killed by tests, and one fell with an error. I did not say that mutations can generate fatalities. We can easily change something: make the return type invalid, or something else. It’s possible, it’s considered a killed mutant, because our test will begin to fall.
Nevertheless, Infection distinguishes such mutants in a separate category for the reason that sometimes it is worth paying special attention to errors. It happens that something strange happens - and the mutant is not quite correctly considered to be killed.
The second thing we use is the report on the master. Once a day, at night, when our development infrastructure is idle, we generate a report on code coverage. After that, we make the same mutation testing report. It looks like this:

If you ever looked at the report on code coverage of PHPUnit, you probably noticed that the interface is similar, because we made our tool by analogy. He simply calculated all the key indicators for a particular file in a directory. We also set certain goals (in fact, we took them from the ceiling and do not comply yet, since we have not yet decided what goals should be guided by each metric, but they exist so that it is easy to build reports in the future).
And the last thing, the most important, which is a consequence of the other two. Programmers are lazy people. I am lazy: I like everything to work and I don’t have to make extra gestures. We made it so that when a developer pushes his own branch, the indicators of his branch and brunch master are automatically incrementally counted.

For example, I ran two files and got this result. In the master I had 548 mutants, 400 were killed. According to another file - 147 versus 63. In my branch, the number of mutants in both cases increased. But in the first file, the mutant was nailed, and in the second - he escaped. Naturally, the MSI indicator fell. Such a thing allows even people who do not want to waste time to run mutational testing with their hands, see what they have done worse, and pay attention to it (exactly the same way as reviewers do in the process of code review).
It is still difficult to give any numbers: we had no indicator, now it has appeared, but there is nothing to compare with.
I can say that mutational testing gives in terms of psychological effect. If you start to run your tests through mutation testing, you unwittingly start writing better tests, and writing quality tests inevitably leads to a change in the way you write code - you start thinking that you need to cover all the cases that you can break, you start it better structure, make it more testable.
This is an exclusively subjective opinion. But some of my colleagues gave roughly the same feedback: when they began to constantly use mutational testing in their work, they began to write tests better, and many said that they began to write code better.
Code coverage is an important metric that needs to be monitored. But this indicator does not guarantee anything: it does not mean that you are safe.
Mutation testing can help make your unit tests better, and tracking code coverage makes sense. There is already a tool for PHP, so if you have a small project without troubles, then grab and try today.
Start at least by running a mutation test manually. Take this simple step and see what it gives you. I’m sure you will like it.
One way to figure this out is by mutation testing. This tool, making small changes to the source code and re-running the tests after that, allows you to identify useless tests and low-quality coverage.
At the Badoo PHP Meetup in March, I talked about how to organize mutational testing for PHP code and what problems you might encounter. The video is available here , and for the text version, welcome to cat.
What is mutation testing
To explain what I mean, I'll show you a couple of examples. They are simple, exaggerated in places and may seem obvious (although real examples are usually quite complex and cannot be seen with their eyes).
Consider the situation: we have an elementary function that claims to be an adult, and there is a test that tests it. The test has a dataProvider, that is, it tests two cases: age 17 years and age 19 years. I think it’s obvious to many of you that isAdult has 100% coverage. The only line. It is performed by a test. Everything is great.
But upon closer inspection, it turns out that our provider is poorly written and does not test boundary conditions: the age of 18 is not tested as a boundary condition. You can replace the> sign with> =, and the test will not catch such a change.
Another example, a little more complicated. There is a function that builds some simple object containing setters and getters. We have three fields that we set, and there is a test that checks that the buildPromoBlock function really collects the object that we expect.
If you look closely, we also have setSomething, which sets some property to true. But in the test we don’t have such an assert. That is, we can remove this line from buildPromoBlock - and our test will not catch this change. At the same time, we have 100% coverage in the buildPromoBlock function, because all three lines were executed during the test.
These two examples lead us to what mutation testing is.
Before disassembling the algorithm, I will give a short definition. Mutation testing is a mechanism that allows us, making minor changes to the code, to imitate the actions of the evil Pinocchio or Junior Vasya, who came and began to break it purposefully, replace the> characters with <, = by! =, And so on. For each such change we make for good purposes, we run tests that should cover the changed row.
If the tests didn’t show us anything, if they didn’t fall, then they are probably not effective enough. They do not test boundary cases, do not contain assertions: perhaps they need to be improved. If the tests fall, then they are cool. They really protect against such changes. Therefore, our code is harder to break.
Now let's analyze the algorithm. It is quite simple. The first thing we do to perform mutation testing is to take the source code. Next, we get code coverage to know which tests to run for which string. After that, we go over the source code and generate the so-called mutants.
A mutant is a single code change. That is, we take a certain function where there was a> sign in comparison, in if, we change this sign to> = - and we get a mutant. After that we run the tests. Here is an example of a mutation (we replaced> with> =):
In this case, mutations are not made randomly, but according to certain rules. The mutation testing response is idempotent. No matter how many times we run mutational testing on the same code, it produces the same results.
The last thing we do is run the tests that cover the mutated line. Get it out of coverage. There are non-optimal tools that drive all the tests. But a good tool will drive away only those that are needed.
After that, we evaluate the result. Tests fell - then everything is fine. If they did not fall, then they are not very effective.
Metrics
What metrics does mutation testing give us? It adds three more to code coverage, which we will talk about now.
But first, let's analyze the terminology.
There is the concept of killed mutants: these are the mutants that our tests “nailed” (that is, they caught them).
There is the concept of escaped mutant (surviving mutants). These are the mutants who managed to avoid punishment (that is, the tests did not catch them).
And there are concepts covered mutant - a mutant covered by tests, and an uncovered reverse mutant that is not covered by any test at all (i.e. we have code, it has business logic, we can change it, but not a single test does not check for changes).
The main indicator that mutation testing gives us is the MSI (mutation score indicator), the ratio of the number of killed mutants to their total number.
The second indicator is mutation code coverage. It is just qualitative, not quantitative, because it shows how much business logic you can break and do it on a regular basis, our tests are caught.
And the last metric is covered MSI, i.e. a softer MSI. In this case, we calculate MSI only for those mutants that were covered by tests.
Mutation Testing Issues
Why did less than half of the programmers hear about this tool? Why is it not used everywhere?
Low speed
The first problem (one of the main ones) is the speed of mutation testing. In the code, if we have dozens of mutation operators, even for the simplest class, we can generate hundreds of mutations. For each mutation, you will need to run tests. If we have, say, 5,000 unit tests that run for ten minutes, mutational testing can take hours.
What can be done to level this? Run tests in parallel, in multiple threads. Throw streams into several cars. It works.
The second way is incremental runs. There is no need to count mutational indicators for the entire branch each time - you can take branch diff. If you use feature-brunches, it will be easy for you to do this: run tests only on those files that have changed, and see what is going on in the wizard, compare, analyze.
The next thing you can do is mutation tuning. Since mutation operators can be changed, you can set certain rules by which they work, then you can stop some mutations if they knowingly lead to problems.
An important point: mutational testing is only suitable for unit tests. Despite the fact that it can be run for integration tests, this is obviously a failed idea, because integration (like end-to-end) tests run much slower and affect much more code. You simply will never wait for the results. In principle, this mechanism was invented and developed exclusively for unit testing.
Endless mutants
The second problem that can arise with mutation tests is the so-called endless mutants. For example, there is simple code, a simple for loop:
If you replace i ++ with i--, then the cycle will turn into an infinite. Your code will stick for a long time. And mutational testing quite often generates such mutations.
The first thing you can do is mutation tuning. Obviously, changing i ++ to i-- in a for loop is a very bad idea: in 99% of cases, we will end up with an infinite loop. Therefore, we have forbidden to do this in our tool.
The second and most important thing that will protect you from such problems is the timeout for the run. For example, the same PHPUnit has the ability to complete the test by timeout, regardless of where it is stuck. PHPUnit through PCNTL hangs up callbacks and calculates the time itself. If the test fails for a certain period, it simply nails it and such a case is considered a killed mutant, because the code that generated the mutations is really checked by a test that really catches the problem, indicating that the code has become inoperative.
Identical mutants
This problem exists in the theory of mutation testing. In practice, it is not often encountered, but you need to know about it.
Consider a classic example illustrating it. We have a multiplication of variable A by -1 and division of A by -1. In the general case, these operations lead to the same result. We change the sign of A. Accordingly, we have a mutation that allows two signs to change among themselves. The logic of the program by such a mutation is not violated. Tests and should not catch it, should not fall. Due to such identical mutants, some difficulties arise.
There is no universal solution - everyone solves this problem in his own way. Perhaps some sort of mutant registration system will help. We at Badoo are thinking about something similar now, we will mimic them.
This is a theory. What about PHP?
There are two well-known tools for mutational testing: Humbug and Infection. When I was preparing the article, I wanted to talk about which one is better and come to the conclusion that this is Infection.
But when I went to the Humbug page, I saw the following there: Humbug declared itself obsolete in favor of Infection. Therefore, part of my article turned out to be meaningless. So Infection is a really good tool. I must say thanks to borNfree from Minsk who created it. It really works cool. You can take it directly from the box, put it through and run it.
We really liked Infection. We wanted to use it. But they could not for two reasons. Infection requires code coverage to run tests for mutants correctly and precisely. Here we have two ways. We can calculate it directly in runtime (but we have 100,000 unit tests). Or we can calculate it for the current master (but the assembly on our cloud of ten very powerful machines in several threads takes an hour and a half). If we do this on every mutational run, the tool will probably not work.
There is an option to feed the finished one, but in the PHPUnit format, this is a bunch of XML files. In addition to the fact that it contains valuable information, they drag along a bunch of structure, some brackets and other things. I figured that in general, our code coverage will weigh about 30 GB, and we need to drag it across all the cloud machines, constantly read from disk. In general, the idea is so-so.
The second problem was even more significant. We have a wonderful SoftMocks library. It allows us to deal with legacy code, which is difficult to test, and successfully write tests for it. We are actively using it and are not going to refuse it in the near future, despite the fact that we are writing new code so that we do not need SoftMocks. So, this library is incompatible with Infection, because they use almost the same approach to mutating changes.
How do SoftMocks work? They intercept file inclusions and replace them with modified ones, that is, instead of executing class A, SoftMocks create class A in another place and connect another one instead of the original one. Infection acts in exactly the same way, only it works through stream_wrapper_register () , which does the same thing, but at the system level. As a result, either SoftMocks or Infection can work for us. Since SoftMocks are necessary for our tests, it is very difficult to make these two tools friends. This is probably possible, but in this case we get into Infection so much that the meaning of such changes is simply lost.
Overcoming difficulties, we wrote our little instrument. We borrowed mutation operators from Infection (they are cool written and very easy to use). Instead of starting mutations through stream_wrapper_register (), we run them through SoftMocks, that is, we use our tool from the box. Our toolza is friends with our internal code coverage service. That is, on demand it can receive coverage for a file or for a line without running all the tests, which happens very quickly. However, it is simple. If Infection has a bunch of all sorts of tools and features (for example, launching into multiple threads), then there is nothing like that in ours. But we use our internal infrastructure to mitigate this shortcoming. For example, we run the same test run in several threads through our cloud.
How do we use it?
The first is a manual run. This is the first thing to do. All tests that you write are manually verified by mutation testing. It looks something like this:
I ran a mutation test for some file. Got the result: 16 mutants. Of these, 15 were killed by tests, and one fell with an error. I did not say that mutations can generate fatalities. We can easily change something: make the return type invalid, or something else. It’s possible, it’s considered a killed mutant, because our test will begin to fall.
Nevertheless, Infection distinguishes such mutants in a separate category for the reason that sometimes it is worth paying special attention to errors. It happens that something strange happens - and the mutant is not quite correctly considered to be killed.
The second thing we use is the report on the master. Once a day, at night, when our development infrastructure is idle, we generate a report on code coverage. After that, we make the same mutation testing report. It looks like this:
If you ever looked at the report on code coverage of PHPUnit, you probably noticed that the interface is similar, because we made our tool by analogy. He simply calculated all the key indicators for a particular file in a directory. We also set certain goals (in fact, we took them from the ceiling and do not comply yet, since we have not yet decided what goals should be guided by each metric, but they exist so that it is easy to build reports in the future).
And the last thing, the most important, which is a consequence of the other two. Programmers are lazy people. I am lazy: I like everything to work and I don’t have to make extra gestures. We made it so that when a developer pushes his own branch, the indicators of his branch and brunch master are automatically incrementally counted.
For example, I ran two files and got this result. In the master I had 548 mutants, 400 were killed. According to another file - 147 versus 63. In my branch, the number of mutants in both cases increased. But in the first file, the mutant was nailed, and in the second - he escaped. Naturally, the MSI indicator fell. Such a thing allows even people who do not want to waste time to run mutational testing with their hands, see what they have done worse, and pay attention to it (exactly the same way as reviewers do in the process of code review).
results
It is still difficult to give any numbers: we had no indicator, now it has appeared, but there is nothing to compare with.
I can say that mutational testing gives in terms of psychological effect. If you start to run your tests through mutation testing, you unwittingly start writing better tests, and writing quality tests inevitably leads to a change in the way you write code - you start thinking that you need to cover all the cases that you can break, you start it better structure, make it more testable.
This is an exclusively subjective opinion. But some of my colleagues gave roughly the same feedback: when they began to constantly use mutational testing in their work, they began to write tests better, and many said that they began to write code better.
findings
Code coverage is an important metric that needs to be monitored. But this indicator does not guarantee anything: it does not mean that you are safe.
Mutation testing can help make your unit tests better, and tracking code coverage makes sense. There is already a tool for PHP, so if you have a small project without troubles, then grab and try today.
Start at least by running a mutation test manually. Take this simple step and see what it gives you. I’m sure you will like it.
All Articles