エントリーの代わりに。 のこぎりの議論をやめて、もっと良いものを作りましょう
Intelのブログの一部として、「複雑な」ITスタートアップを作成するというテーマをサポートしたいと思っています。 私はそのようなトピックを聞き、議論することにもっと興味があります。 おそらく、 ISNプラットフォームは、 やがて 、並列プログラミング、独自のライブラリの作成、およびこの種のその他の技術の分野での議論と新興企業の出現が始まる場所になるでしょう。 そして、おそらくKhabrahabarでは、外国企業の業績や私たちの削減に関する投稿が少なくなり、彼自身の経験、誰が何をどのように行うかについてのより興味深い記事があります。
宇宙におけるVivaCoreの場所
VivaCoreライブラリの場所をすぐに明確に特定します 。 VivaCoreライブラリは、長年開発されていない別のオープンライブラリOpenC ++に基づいて作成されました[1]。 VivaCoreは、OpenC ++ライブラリがVisual C ++ 8.0、9.0、10.0でコンパイルされたソースコードを解析できるようにするパッチ、修正、松葉杖、小道具、小道具のセットです。 つまり、特定の拡張機能と、C ++ 0xで登場し、Visual C ++ 10.0で実装された新しいコンストラクトをサポートするためです[2]。
VivaCoreは完全なライブラリではありません。 PVS-Studioに含まれる静的コードアナライザーを作成するメカニズムとして、VivaCoreを開発しています。 つまり、VivaCoreはPVS-Studioプロジェクトのこの部分であり、他の人がOpenC ++の改良および拡張バージョンを使用できるようにするためにオープンにすることにしました。
VivaCoreには多くの欠点があります。 一部のテンプレート構造の分析は完全には不可能であり、ドキュメントはありません。Unicode形式のコードを扱うことは不可能です。 C / C ++言語の解析と分析のための本格的なサポートが必要な場合、または独自のコンパイラ/開発環境を作成する予定の場合、VivaCoreライブラリは適していません。 この場合、プロのライブラリ、たとえば-EDGを使用する必要があります。 このようなライブラリのライセンス価格は、年間40,000ドルから250,000ドルの間で変動します。 この価格は、プロジェクトの成功を確信することなく、このような投資の準備ができていない多くのスタートアッププロジェクトにとって高すぎます。 この場合、VivaCoreライブラリが適切な妥協点となります。 それは無料で、完璧ではありませんが、かなり良いレベルでC / C ++で作業できます。 ほとんどのコードツールでは、このレベルで十分です。
GCCソースコードまたは他のオープンシステムに基づいてプロジェクトを構築しようとする機会があることに言及する必要があります。 これらのオプションには、長所と短所の両方があります。 実装がより簡単になり、より複雑になります。 法的側面も調整を行います。 VivaCoreライブラリについてお話ししたいのですが、調査、比較、選択は読者にお任せします。
VivaCoreライブラリにまだ興味がある場合は、この記事を読むと、VivaCoreライブラリをよりよく理解し、そのアプリケーションの可能な領域について話をすることができます。 ソースアーカイブ(VS2010のプロジェクト)は、 http ://www.viva64.com/en/vivacore-library/からダウンロードできます 。 随時更新しています。 トレーニングに関連する場合は、VivaCoreの操作に関するさまざまな質問に圧倒されないように事前に質問したいだけです。 本格的なプロジェクトをお持ちの場合は、もちろん、提案を試みるか、必要な機能の実装に関する合意を締結することができます。 パーサーなどの作成に関連するタームペーパー/卒業証書の割り当てを受けたときに、年に2回発生する学生の質問の流入を防ぎたいと思います。 :)
主な用語
先に進む前に、いくつかの用語の定義を簡単に説明します。
前処理は、入力 ".c / .cpp"ファイルを調べ、その中のプリプロセッサディレクティブを実行するメカニズムです。#includeディレクティブなどで指定された他のファイルの内容も含まれます。 結果は、プリプロセッサディレクティブを含まないファイルになり、使用されているすべてのマクロが展開され、対応するファイルの内容が#includeディレクティブに置き換えられます。 通常、前処理結果ファイルの接尾辞は「.i」です。 前処理の結果は、変換単位と呼ばれます。
解析は、文法構造を解析するために入力文字列を分析するプロセスです。 通常、構文解析は、字句解析と文法解析の2つのレベルに分けられます。
字句解析は、出力でトークン(または「トークン」)と呼ばれる文字のシーケンスを取得するために、文字の入力シーケンスを処理するプロセスです。 各トークンは、トークンのタイプと、必要に応じて対応する値を含む構造の形式で条件付きで表すことができます。 C ++の場合、トークンは「クラス」、「int」、「-」、「{」などです。
文法分析(文法分析)は、言語の語彙素(単語)の線形シーケンスを正式な文法と比較するプロセスです。 結果は通常、解析ツリーまたは抽象構文ツリーです。
抽象構文ツリー(AST)は、内部の頂点がプログラミング言語の演算子にマップされ、葉が対応するオペランドにマップされる、ラベルが付けられた有限のツリーです。 したがって、リーフは空の演算子であり、変数と定数のみを表します。 抽象構文ツリーは、プログラムのセマンティクスに影響を与えない構文規則のノードがないという点で、解析ツリー(DTまたは解析ツリー-PT)とは異なります。 ASTではオペランドのグループ化がツリー構造によって明示的に定義されているため、グループ化ブラケットはこの不在の典型的な例です。
メタプログラミングとは、作業の結果として他のプログラムを作成したり、実行中に自分自身を変更または補完したりするプログラムの作成です。 メタプログラミングでは、コード生成と自己修正コードという2つの主要な領域を区別できます。 次に、メタプログラミングをC / C ++ソースコードの生成と見なします。
構文ツリートラバーサル-さまざまな種類の情報、分析、または修正を収集するための、構文ツリーのすべての頂点とリーフのトラバーサル。
VivaCoreとは何ですか?
VivaCoreライブラリは、古いライブラリであるOpenC ++(OpenCxx)に基づいて構築されたオープンソースプロジェクトです。 VivaCoreライブラリはC ++で実装され、Visual Studio 2010でのコンパイルを目的としたプロジェクトです。ただし、特定のVisual C ++コンパイラ拡張機能は使用されておらず、少し適応した後、別の最新のコンパイラでプロジェクトをビルドできます。
VivaCoreライブラリは、OOOプログラム検証システムのスタッフによって作成および開発されました。 VivaCoreコード分析ライブラリには、コンピュータープログラムN 2008610480の状態登録証明書があります。
VivaCoreライブラリは無料で無料で使用できます。 ライセンスの制限は、プロジェクトがOpenC ++ライブラリとその拡張機能-VivaCoreに基づいていることを示す必要があることだけです。
まず、VivaCoreライブラリは、コードを操作するためのツールを作成または作成する予定の小規模企業(新興企業)にとって興味深いものです。 当然、許容されるすべての分野と適用方法をリストすることはできませんが、それでも、さまざまな角度からVivaCoreを表示するためのいくつかの方向に名前を付けます。 括弧内に、このクラスのソリューションに関連する製品の例が説明として示されています。 したがって、VivaCoreを使用すると、以下を開発できます。
- コードリファクタリングツール(VisualAssist、DevExpressリファクタリング、JetBrains Resharper);
- 一般的および特殊な目的の静的アナライザー(Viva64、lint、Gimpel Software PC-Lint、Parasoft C ++テスト);
- 動的コードアナライザー(Compuware BoundsChecker、AutomatedQA AQTime);
- メタプログラミング(OpenTS)のサポートを含む、C / C ++言語の拡張。
- 自動コードテスト(Parasoft C ++テスト)
- たとえば、最適化のためのコード変換。
- シンタックスハイライト(Whole Tomato Software VisualAssist、最新の開発環境);
- コード文書構築システム(Synopsis、Doxygen);
- ソースコードの変更を制御したり、変更の進化を分析したりするためのツール。
- 言語の文法構造のレベルで重複コードを検索します。
- カウントメトリック(CおよびC ++コードカウンター-UDP);
- コーディング標準のサポート(Gimpel Software PC-Lint);
- 他のソフトウェアおよびハードウェアプラットフォーム(Viva64)へのコードの移行を容易にするツール。
- 自動コード生成;
- コードビジュアライザー、依存関係図を作成するためのシステム(ソースナビゲーター、CppDepend)。
- コードの書式設定(Ocher SourceStyler)。
VivaCoreライブラリとOpenC ++ライブラリの違い
VivaCoreライブラリとOpenC ++の主な違いは、それが生きているプロジェクトであり、機能を積極的に増やし続けていることです。 残念ながら、OpenC ++ライブラリは長い間開発されていません。 ライブラリの最新の変更は2004年に遡ります。 そして、新しいキーワードのサポートに関連する最後の変更は2003年に遡ります。 この修正は、wchar_tデータ型を追加しようとして失敗したため、さまざまなタイプの5つのエラーが発生しました。
OpenC ++と比較して、VivaCoreライブラリに実装されている新しい主要機能をリストします。
- クラシックC言語がサポートされています。 別のトークンセットが使用されます。これにより、変数に「class」という名前を付けたり、クラシックCスタイルで関数を宣言したりできます。PureC_Foo(ptr)char * ptr; {...}。
- VisualStudio 2005/2008/2010環境での開発で使用されるC ++言語構文の特定の機能をサポートするために、多くの作業が行われました。 たとえば、ライブラリはキーワード__noop、__ if_exists、__ ptr32、__ pragma、__ interfaceなどを処理します。
- 1998年のC ++言語標準で利用可能ないくつかの新しい構成体がサポートされていますが、OpenC ++には入りませんでした。 特に、テンプレートという単語を使用したテンプレート関数の呼び出しのサポート:object.template foo <int>();。
- C ++ 0x言語標準は、Visual C ++およびIntel C ++コンパイラがサポートするレベルでサポートされています。
- リテラル定数の値の計算が実装されています。
- このライブラリは、64ビットシステムで動作するように適合および最適化されています。
- 多数のエラーと欠点を修正しました。 それらの多くがあり、それらをここにリストし、不可能はありません。
- OpenMPディレクティブの解析がサポートされています。 確かに、それらの作業のほとんどはVivaCoreには存在しないVivaMPコードによって実行されます。 しかし、もしそうなら、書いてください-私たちはプロンプトを表示し、助けます
- long型のコーディングを実装しました。 以前は、127文字以下の特殊な文字列ですべての型がエンコードされていましたが、これでは十分ではありませんでした。 その結果、boostやlokiなどのライブラリでは、OpenC ++ライブラリが「狂って」しまい、正しく動作しませんでした。
VivaCoreライブラリの一般的な構造
VivaCoreライブラリの一般的な機能構造を図1に示します。

図1. VivaCoreライブラリの一般的な構造。
図2に示すように、入力で受信したプログラムのソースコードを処理する順序でライブラリの機能ブロックを検討します。各機能ブロックが実行するアクション、取得可能な情報、特定の目的のためにどのように変更できるかを検討してください。
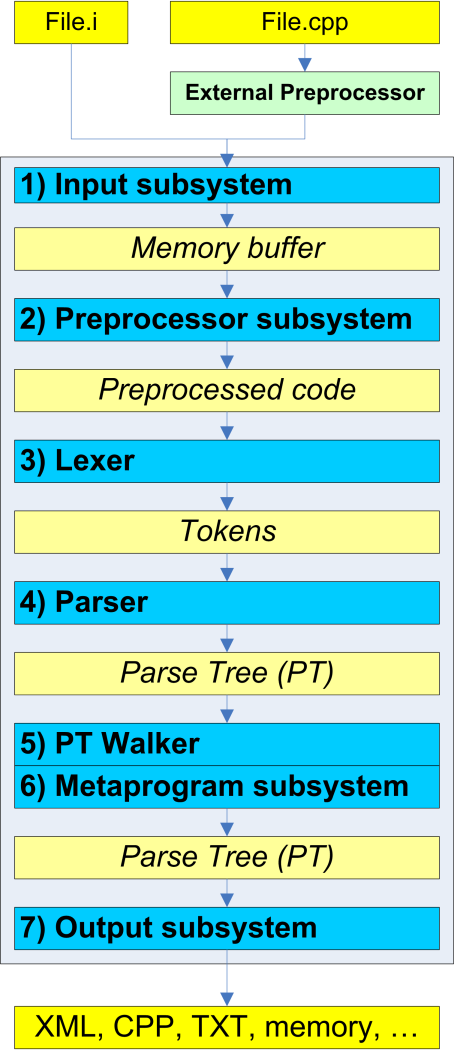
図2-コード処理のシーケンス。
1)入力サブシステム
VivaCoreライブラリは、プリプロセッサによって以前に処理されたソースC / C ++コードのみを正しく使用できます。 現在、PVS-Studioで前処理されたファイルを生成するために、Visual C ++コンパイラが使用されています。 作業後、拡張子が「i」の処理済みファイルが取得され、VivaCoreが機能します。
場合によっては、未加工のC / C ++ファイルを入力に送信できますが、この場合、ファイルをトークンに分割するレベル以上でVivaCoreを操作する必要はありません。 これは、メトリックやその他の目的を数えるのに十分かもしれません。 ただし、解析ツリー(PT)を構築して分析しようとしないでください。結果は処理にほとんど役に立たない可能性が高いためです。
前処理されたコードがあれば、ユーザーはそれをファイルまたはメモリ内のバッファの形でデータ入力サブシステムに転送できます。 入力サブシステムの目的は、転送されたデータをVivaCoreライブラリの内部構造に配置することです。 入力サブシステムは、システムライブラリと見なされるものとユーザーライブラリと見なされるものを報告する構成データも受け入れます。
2)プリプロセッササブシステム
このサブシステムは、古典的な意味でのコードの前処理を実行しないことを強調したいと思います。 前に述べたように、前処理されたコードはすでにVivaCoreライブラリに送信されているはずです。 考慮されたサブシステムは、次のタスクに役立ちます。
- プログラムテキストを行に分割し、2つの論理グループに分割します。 最初のグループには、システムコード(コンパイラライブラリコードなど)が含まれます。 分析対象の2番目のユーザーコード。 その結果、静的アナライザーを開発するときに、ユーザーはシステムライブラリのコードを分析するかどうかを決定する機会を得ます。
- メモリ内のプログラムテキストの特別な変更。 例は、CまたはC ++言語に関連しないコードから特定の開発環境から構造を削除することです。 たとえば、Viva64アナライザーは、Visual Studioヘッダーファイルで使用可能なSA_SuccessやSA_FormatStringなどのキーコンストラクトを削除します。これらは、Visual Studioに組み込まれた静的アナライザー向けです(C / C ++のコード分析について説明しています)。
3)字句解析(レクサー)
そのため、開発者にとって実用的なレベルのデータ処理レベルに到達しました。 コードをトークンに分析した後、ユーザーは多くのメトリックをカウントし、さまざまなアプリケーションで特定の構文強調アルゴリズムを実装する機会があります。
VivaCoreレキシカルアナライザーは、プログラムテキストをトークンタイプのオブジェクトのセットに解析し(Token.hファイルを参照)、トークンのタイプ、プログラムテキスト内の位置、および長さに関する情報が含まれます。 トークンタイプはtokennames.hファイルにリストされています。 トークンのタイプの例:
CLASS-言語「クラス」のキーワード
WCHAR-言語「wchar_t」のキーワード
必要に応じて、ユーザーはトークンのセットを展開できます。 これは、特定の言語実装の特定の構文がサポートされている場合、または独自の言語拡張機能を開発する場合に必要になる場合があります。
トークンを追加する場合、tokennames.hファイルでトークンを宣言し、Lex.ccファイルのテーブル「table」/「tableC」/ tableC0xxに追加する必要があります。 最初のテーブルはC ++ファイルを処理するためのもので、2番目はCファイル用、3番目はC ++ 0x用です。 複数のテーブルが存在する理由は、C、C ++、C ++ 0xのトークンのセットが異なるためです。 たとえば、C言語ではCLASSトークンはありません。Cでは「クラス」という単語はキーワードではなく、変数の名前を示すことができるためです。
実験、VivaCoreの学習、または実際的な目的として、トークンのリストを非構造化テキストの形式で取得するか、次の形式でDumpEx関数を使用できます。
258 LC_ID 5
258 lc_id 5
91 [1
262 6 1
93] 1
59; 1
303構造6
123 {1
282文字4
42 * 1
258ロケール6
4)文法アナライザー(パーサー)
グラマーアナライザーは、派生ツリー(DT)を構築するように設計されており、これをさらに分析および変換できます。 VivaCoreライブラリの文法アナライザは、抽象構文ツリー(AST)ではなく、解析ツリーを構築することに注意してください。 これにより、ユーザーがCまたはC ++言語に追加できるメタプログラム構成のサポートを簡単に実装できます。
VivaCoreライブラリでのツリーの構築は、Parserクラスの関数で発生します。 ツリーのノードとリーフは、基本クラスNonLeafとLeafからクラスが継承されるオブジェクトです。 図3は、ツリーを表すために使用されるクラス階層の一部を示しています。

図3.解析ツリーの構築に使用されるクラス階層の一部。
図からわかるように、Ptreeクラスは他のすべてのユーザーの基本クラスであり、他のクラスと連携するための単一のインターフェースを編成する役割を果たします。 Ptreeクラスには、子孫に実装された純粋な仮想関数のセットがあります。 たとえば、関数 "virtual bool IsLeaf()const = 0;"は、NonLeafクラスとLeafクラスに実装されています。 実際には、クラスはこの関数のみを実装し、クラスの階層をより論理的で美しいものにするために必要です。
ツリーの操作はライブラリのかなりの部分を占めるため、Ptreeにはツリーノードを操作するための多数の関数セットがあります。 便宜上、これらの関数は、Lisp言語のリストを操作する関数に類似しています。 それらのいくつかを以下に示します。Car、Cdr、Cadr、Cddr、LastNth、Length、Eq。
例として、文法アナライザの操作の一般的なアイデアを得るために、次のコードから構築される解析ツリーを提供します。
int MyFoo(定数フロート値)
{
if(値<1.0)
return sizeof(unsigned long *);
戻り値* 4.0f <10.0f? 0-1
}
残念ながら、構文解析ツリー全体を表すことはできないため、図4.1-4.4の部分で説明します。

図4.1。 セマンティックツリーノードのカラーコード。
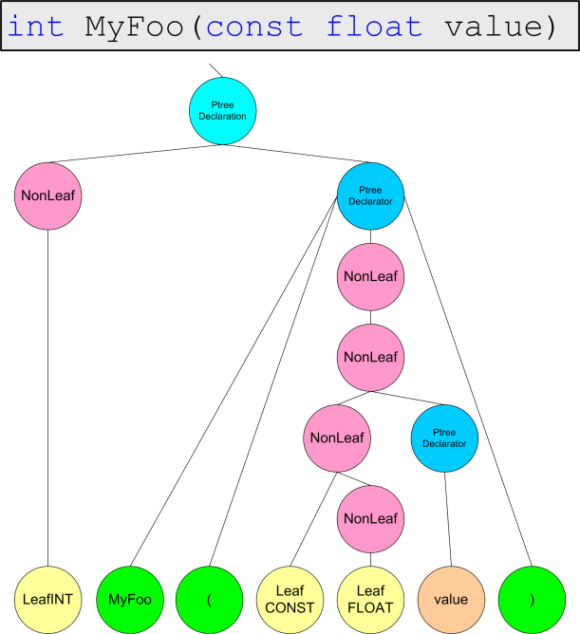
図4.2。 関数ヘッダーの表示。

図4.3。 身体機能の表現。
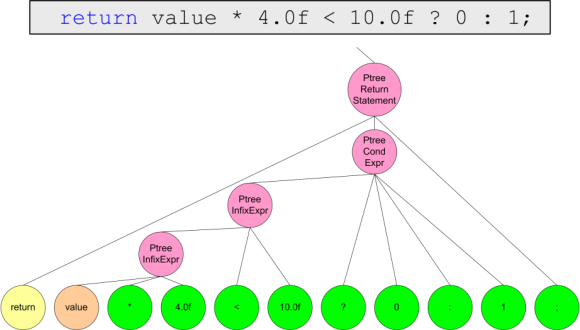
図4.4。 身体機能の表現。
アナライザーの作業のもう1つの重要なコンポーネントについて言及する必要があります。 これは、Encodingクラスに実装されているさまざまなオブジェクト(関数、変数など)のタイプに関する情報を取得しています。 型情報は、特別にエンコードされた文字列として表示されます。その形式はEncoding.ccファイルにあります。 ライブラリには、型情報を取得できる特別なTypeInfoクラスもあります。 たとえば、IsFunction、IsPointerType、IsBuiltInTypeなどの関数を使用すると、処理中の要素のタイプを簡単に識別できます。
新しいタイプのノードまたはリーフを追加する方法の説明は重要なタスクであり、このレビュー記事では説明できません。 合理的な解決策は、PtreeExprStatementなどのクラスの1つを選択し、このクラスのオブジェクトが作成されるコード内のすべての場所を表示し、それらを操作することです。
最後に取得した解析ツリーは、「。s / .cpp」ファイル形式で保存できますが、ほとんど意味がありません。 この機能は、解析ツリーを変更した後、次のステップで発生する可能性があります。 ツリーをプログラムコードの形式で保存したので、入力で得たものを正確に取得できます。 ただし、これはレクサーとパーサーに加えられた変更をテストするのに非常に役立ちます。
ユーザーが実装する任意の形式でさらに処理するためにツリーを保存する機能は非常に興味深いものです。 例は、前述のコードの次のテキスト表現です。
PtreeDeclaration:[
0
ノンリーフ:[
LeafINT:int
]
PtreeDeclarator:[
葉:MyFoo
葉:(
ノンリーフ:[
ノンリーフ:[
ノンリーフ:[
LeafCONST:const
ノンリーフ:[
LeafFLOAT:フロート
]
]
PtreeDeclarator:[
葉:値
]
]
]
葉:)
]
[{
ノンリーフ:[
PtreeIfStatement:[
LeafReserved:if
葉:(
PtreeInfixExpr:[
LeafName:値
葉:<
葉:1.0
]
葉:)
PtreeReturnStatement:[
LeafReserved:戻り
PtreeSizeofExpr:[
葉:sizeof
葉:(
ノンリーフ:[
ノンリーフ:[
LeafUNSIGNED:署名なし
LeafLONG:長い
]
PtreeDeclarator:[
葉:*
]
]
葉:)
]
葉:;
]
]
PtreeReturnStatement:[
LeafReserved:戻り
PtreeCondExpr:[
PtreeInfixExpr:[
PtreeInfixExpr:[
LeafName:値
葉:*
葉:4.0f
]
葉:<
葉:10.0f
]
葉:?
葉:0
葉::
葉:1
]
葉:;
]
]
葉:}
}]
]
この形式は、例として示されています。
5)解析ツリーのバイパス
静的コードアナライザーまたはコードドキュメント構築システムの開発者にとって最も興味深いステップは、Walker、ClassWalker、およびClassBodyWalkerクラスを使用して解析ツリーを調べることです。 解析ツリーを数回バイパスすることができます。これにより、複数のパスでコードを変更するシステムを作成したり、以前のツリーウォークで既に蓄積された知識を考慮して分析したりできます。
Walkerクラスは、基本的なC / C ++言語構造をバイパスするために使用されます。
ClassWalkerクラスはWalkerクラスを継承し、C ++に存在するクラスの詳細に関連する機能を追加します。
ご注意 正直に言うと、OpenC ++でもこれらのクラスの機能は混在しており、VivaCoreではWalkerクラスとClassWalkerクラスがさらに大きくなりました。 それらを1つにまとめることはできますが、そのような作業には意味がありません。
クラス本体を解析する必要がある場合、ClassBodyWalkerクラスのオブジェクトが一時的に作成および使用されます。
VivaCoreライブラリに変更を加えない場合、ツリーのすべての要素を単純に通過します。 この場合、ツリー自体は変更されません。
ユーザーがツリーの頂点を変更する機能を実装する場合、ライブラリはツリーを再構築できます。 たとえば、単項演算を変換するコードを考えます:
Ptree * ClassWalker :: TranslateUnary(Ptree * exp)
{
名前空間PtreeUtilを使用します。
Ptree * unaryop = exp-> Car();
Ptree * right = PtreeUtil :: 2番目(exp);
Ptree * right2 =翻訳(右);
if(right == right2)
return exp;
他に
帰る
新規(GC_QuickAlloc)
PtreeUnaryExpr(unaryop、PtreeUtil ::リスト(right2));
}
式を単項演算の右側に変換することにより、結果のツリーが変更される場合、単項演算ノードが変更(再作成)されることに注意してください。 これにより、上位ノードの再構築が必要になる場合があります。
明確にするために、この例をより詳細に検討してください。
特定の式に対する単項演算であり、PtreeUnaryExprタイプのノードの処理が開始されます。 exp-> Car()演算を使用して取得されるリストの最初の要素は、直接単項演算です。 PtreeUtil :: Second(exp)を使用して抽出される2番目の要素は、単項演算が適用される式です。
式が変換され、結果が変数right2に配置されます。 このアドレスが既存のものと異なる場合、これは式が変更されたことを意味します。 この場合、PtreeUnaryExpr型の新しいオブジェクトが作成され、TranslateUnary関数から返されます。 それ以外の場合、何も変更されず、入力されたとおりに同じオブジェクトが返されます。
ユーザーがツリーの走査中に情報を収集する必要がある場合、またはツリーを変更する必要がある場合、最も自然な方法でClassWalkerクラスとClassBodyWalkerクラスを継承します。
Viva64静的アナライザーから取得した最も単純な例を示します。この例では、throwオペレーターを通過するときに特殊な分析が行われます。
Ptree * VivaWalker :: TranslateThrow(Ptree * p){
Ptree * result = ClassWalker :: TranslateThrow(p);
Ptree * oprnd = PtreeUtil :: 2番目(結果);
// oprnd == nullptrの場合、これは「throw;」です。
if(oprnd!= nullptr){
if(!CreateWiseType(oprnd)){
結果を返す;
}
if(IsErrorActive(115)&&
!ApplyRuleN10(oprnd-> m_wiseType.m_simpleType))
{
AddError(VivaErrors :: V115()、p、115);
}
}
結果を返す;
}
まず、ClassWalker :: TranslateThrow(p)を使用して、標準のノード変換が実行されます。 次に、必要な分析が実行されます。 すべてがシンプルで非常にエレガントです。
ツリートラバーサルについては、さまざまなスコープ内のさまざまなオブジェクトのタイプに関する情報を提供する非常に重要なクラスEnvironmentについても説明する必要があります。
envオブジェクトで表されるEnvironmentクラスを使用してdeclTypeInfoオブジェクトタイプを取得する例:
TypeInfo declTypeInfo;
if(env-> Lookup(decl、declTypeInfo)){
...
}
6)メタプログラミングのサポート
メタプログラミングが自然に不可欠な部分である言語があります。 例としては、「Nemerleでのメタプログラミング」[4]の記事に記載されているNemerle言語があります。 しかし、C / C ++の場合、すべてがより複雑であり、メタプログラミングは次の2つの方法で実装されます。
- C ++のテンプレートとCのプリプロセッサ。 このパスには多くの制限があります。
- 外部言語ツール。 ジェネレーター言語は、プログラマーの側で自動的にまたは最小限の労力で、パラダイムルールまたは必要な特殊機能を実装するようにコンパイルされます。 実際、高レベルのプログラミング言語が作成されています。 VivaCoreライブラリを使用して、このようなシステムを作成できます。
VivaCoreが構築されているOpenC ++ライブラリは、もともとC ++コードの変換専用に考案されました。 ライブラリは、C ++言語の特定のバージョンを使用できるシステムの一部でした。
また、OpenC ++に基づいて、T ++プログラミング言語用のOpenTSランタイム環境は、ロシア科学アカデミーのソフトウェアシステム研究所で作成されました。 これはC ++言語であり、コードセクションの自動並列化のために追加の構造が導入されています。 簡単にするために、これを一種のOpenMPテクノロジーアナログと呼びます。 この例は、メタプログラミングタスクにOpenC ++ライブラリを使用する可能性を示しています。 VivaCoreライブラリはこれらの機能を適宜継承しました。
VivaCoreライブラリ内のメタプログラミングでは、独自のプログラミング言語を作成するために、C / C ++言語の構文と機能を拡張する可能性を理解する必要があります。 新しいメタ言語は、プリプロセッサとコンパイラ間の中間リンクとして実装できます。 一般的な場合、機能スキームは図5に示すように表すことができます。
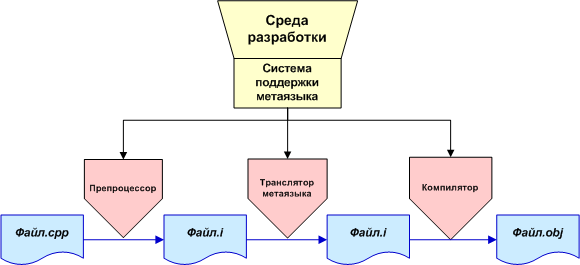
図5.コンパイルプロセスへのメタ言語翻訳者の参加。
VivaCoreを使用すると、プログラムを次のように変換できます。 構文解析ツリーが構築されています。 次に、ツリーノードのトラバーサルがあり、新しい言語のコンストラクトであるノードがC / C ++言語コンストラクトに変わります。 必要な機能を備えた新しいサブツリーが構築されます。 この場合、親ノードはメタ言語構造を持つノードではなく、C / C ++言語要素から作成されたこれらのサブツリーを指し始めます(上記の「解析ツリーのウォーク」も参照)。
必要に応じて、このようなパッセージをいくつか作成して、新しい言語の他の構成から新しい言語の構成を作成できるようにすることができます。
処理後、新しいツリーをC / C ++のプログラムのテキストに保存し、コンパイラを使用してアセンブルします。
ご注意 読者を惑わさないために、残念ながらこれは理論的にすべてであるとすぐに言わなければなりません。 OpenC ++に対する編集と拡張の数が、プログラムを変換するメカニズムに影響するかどうかはテストしませんでした。 このメカニズムは使用しないため、結果としてテストしません。 残念ながら、エラーと欠陥があると確信しています。その結果、出力のプログラムのテキストは入力のプログラムのテキストに対応しません。 私は開業医であり、そのような事に幸運を信じていませんし、間違いはそこにあるはずです。 したがって、変換ツールの作成を開始する場合は、これに備えて、scらないでください。 より良い書き方で、多分一緒に世界を改善するでしょう(図書館の意味で)。
メタプログラミングの詳細については、OpenC ++ライブラリ[5]の利用可能なドキュメントを参照してください。
7)結果の保存
VivaCoreライブラリ内のソースコード処理の任意の段階で必要な情報を保存できます。 特に、結果および修正された解析ツリーは、プログラムテキストまたはその他の形式で保存できることを説明しました。 繰り返しません。 また、必要な情報を収集するタスクに、たとえば静的分析やメトリックのカウント中にさまざまな方法でアプローチできることも明らかです。
VivaVisualCodeデモプロジェクト
VivaCoreライブラリの使用方法をより明確に示すために、 http: //www.viva64.com/en/vivacore-library/からダウンロードできるデモプロジェクトVivaVisualCodeを作成しました。
VivaVisualCodeは、構築された解析ツリーをグラフィカルに表示し、そのノードに関する情報を表示できます。
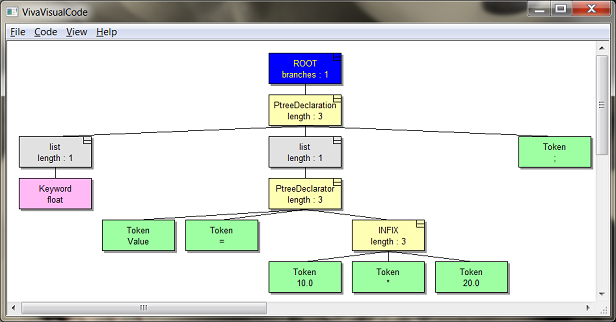
図6. VivaVisualCodeによってコード「float Value = 10.0 * 20.0;」用に構築された解析ツリーの例。
結論の代わりに
Evgeny Zuevによるコンパイラの開発における彼の経験についての記事「 まれな職業 」を読者に提供したいと思います。 この記事はこの投稿とは関係ありませんが、非常に面白いのでお勧めします。
書誌リスト
- OpenC ++ライブラリ。 http://www.viva64.com/go.php?url=16
- アンドレイ・カルポフ。 C ++コードおよび新しいC ++ 0x言語標準の静的分析。 http://www.viva64.com/art-2-1-1708094805.html
- ジョナサン・バートレット。 メタプログラミングの技術、パート1:メタプログラミング入門。 http://www.viva64.com/go.php?url=39
- カミル・スカルスキ。 Nemerleのメタプログラミング。 http://www.viva64.com/go.php?url=40
- Grzegorz Jakack。 OpenC ++-C ++メタコンパイラおよびイントロスペクションライブラリ。 http://www.viva64.com/go.php?url=41