データの処理と分析に関心があるシステムのユーザーには、システムで発生した変更に関する特別なレポートを表示する機会を与える必要があります。 レポート情報を必要とするシステムのユーザーは、明らかに、システムに登録されているアクティビティに適用されるアクティビティのフィールドでそれを使用します。 その結果、システムは非常に多くのレポートフォームを提供できるようになり、各ユーザーが仕事でそれらの組み合わせを適切に使用できるようになります。
この問題は、次の2つの方法で解決できます。
- 設計段階で、あらゆる種類の静的(既製)レポートテンプレートを計画し、ユーザーの要求に応じてデータを入力します。
- OLAP(Online Analytical Processing)分析テクノロジを使用して動的にレポートを作成し、次にOLAPを作成します。
テンプレートの設計段階で間違いを犯す可能性が非常に高いため、明らかに、最初の方法は実際には非常に困難です。 2番目の方法の欠点には、分析を実行できる測定のセットが限られていることが含まれます。 分析のタスクは、ユーザーの最大ニーズを満たしつつ、レポートにアクセスできないデータセットを最小化することであると仮定すると、問題の解決策は2つの提案された方法の組み合わせになります。 さらに、顧客が先験的にシステムに期待していることを考えると、ユーザー要件の大部分は静的テンプレートでカバーされます。 次に、OLAPメカニズムにより、より「高度な」分析条件の動的レポートを作成し、システムにデータを入力するダイナミクスを記述し、データの変化のベクトルの方向を示すことができます。
設計段階で特定の手順を使用して技術的ソリューションを説明するには、データベースの設計方法に目を向ける必要があります。 それらのいくつかがありますが、説明されているケースでは、2つだけを考慮する価値があります:
- オンライントランザクション処理(OLTP)
- オンライン分析処理(OLAP)
最初のアプローチは、「許容される抽象化-エンティティ-テーブル」という形式のいくつかの正規化ルールが実行される場合の「標準」データベース設計を意味します。 このフォームでは、システムデータベースが設計されています。 一連の関連データが最小限の重複フィールドを持つデータベースに存在し、その結果、他のすべてが等しい場合に最小限のスペースを使用する場合、効果的な冗長性を考慮してデータを保存するのに最適です。 このアプローチは、2番目(OLAP)の反対であり、その必須条件は、データとデータ間の関係の最大許容非正規化です。
OLAPデータ分析の技術は、いわゆる 多次元OLAPキューブは、多くの変数(または測定値)の関数にすぎず、その値のセット(いわゆるファクト)は、システムの何らかの質的な状態を表します。 この関数の一部のディメンション(キューブなど)を入力パラメーターとして指定することにより、動的レポートテンプレートでの使用に適した一連のデータを取得できます。 明らかに、このようなデータのセットを迅速に取得するためには、各次元の値の有限セットを事前に知る必要があります。 したがって、OLAP設計におけるリンクと重複データの冗長性は、達成される目標の観点からは不利ではありません。
- 目的の測定値の計算の最小化
- システムの状態の値の計算の最小化(事実)
そのような測定の一般的な例は次のとおりです。
- 測定としての時間
- ディメンションとしてのエンティティ属性
- キューブ値としてのエンティティの数
OLTPデータベースの設計は、有効なディメンションの値の過剰な数を最小限に抑えるように設計されているため、キューブのデータソースとしては適していません。 測定が十分に完了するために、システムの元のデータベースは、いわゆる データウェアハウス-タスクの条件を満たす、専用のOLAPデータベース。 レポートで使用されるデータのソースとして機能します。
前述のことから、データ分析の問題を解決する場合、次のステートメントが当てはまるということになります。
- 特別な変換を使用して、メインデータベースからデータベースデータにデータを入力する必要があります
- レポート(静的および動的)の場合、DBストレージが使用され、システムおよびその他の機器のAWPについては、システムのメインDBが使用されます
- レポートを作成するときにシステムが消費するリソースとデータベースでの残りの作業は並行して分散されるため、2つの独立した実行プロセスに分割され、互いに干渉しません。
このアプローチには2つの欠点があります。
- メインデータベースからストレージに値を抽出するデータ変換を作成する必要があります
- 変換は理論的にリソースを集中的に使用するため、一定の間隔で実行できます。
指定された時間間隔は、ユーザーにとって重要な場合があります。これは、ユーザーの間に「古いデータ」と呼ばれるシステムの状態があるためです。 これは、レポートが非正規化変換の最後の実行の時間より長く、その後の変換の時間より短い特定の時点で作成された場合、ユーザーに関係のないデータを表示することを意味します。 そのようなデータの期限が切れる時間は、設定された起動間隔以下になります。
したがって、データ分析の2番目のタスクは、変換機能の最小の複雑さで時間間隔を最小化するタスクです。 システム開発者は、このタスクに高い優先度を与える必要があります。
実用的なソリューション
キューブが非正規化データを最も効率的に使用するには、ストレージ構造が次の条件を満たす必要があります。
- データベースは、測定値と事実の表で構成されています
- ファクトは、システムの定性的特性である多次元関数(キューブ)の計算値です
- 事実自体が次元であり、その逆もある
- テーブルは、特定のディメンションから事実を取得するためのアルゴリズム的な方法が少なくとも1つあるように接続する必要があります。
実際には、これらの4つの条件は、スノーフレークデータベーステーブルのトポロジによって特徴付けられます。
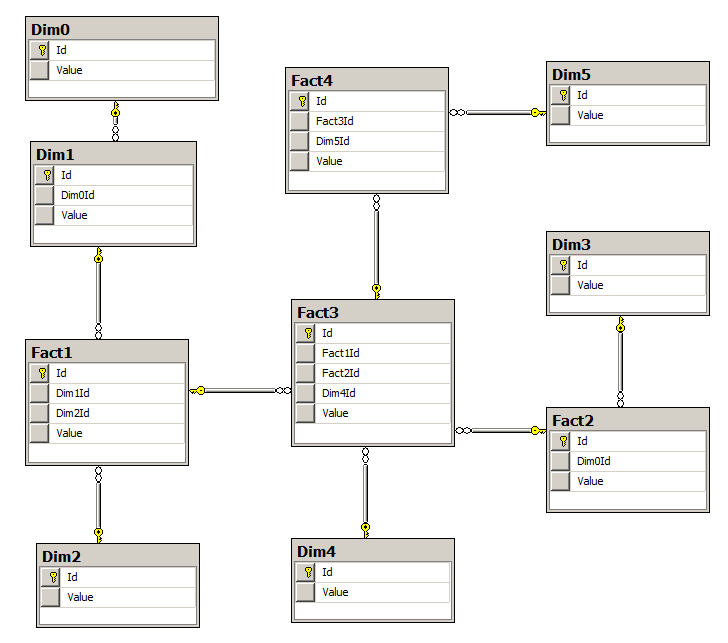
図1:スノーフレークデータベースストレージの実用的な実装例
ここで、Valueはディメンション、ファクトの値です。
実際には、非正規化変換はストアドプロシージャで指定され、指定された間隔でJOBのようなデータベースプロセスで実行されます。
静的レポートテンプレートは、受信方法のみが動的テンプレートと異なります。 動的バージョンでは、テンプレートはユーザーが特別なプログラムを使用して作成されますが、静的テンプレートはユーザーが編集することはできず、ユーザーが固定リストから手動で選択する必要があります。
テンプレートはパラメータ化できます。 この場合、そのような値は、特殊なパラメーターの形式で特別なインターフェイスクエリ言語を介してキューブに転送されます。
分析とレポートの問題に対する産業用ソリューションの例は、Microsoft Analysis ServicesとMicrosoft Reporting Servicesです。