 ほとんどすべての開発者は、プロセッサキャッシュが最近訪れたメモリ領域からのデータを格納する非常に小さいが高速なメモリであることを知っています-定義は短く、かなり正確です。 ただし、コードのパフォーマンスに影響する要因を理解するには、キャッシュのメカニズムに関する「退屈な」詳細を知る必要があります。
ほとんどすべての開発者は、プロセッサキャッシュが最近訪れたメモリ領域からのデータを格納する非常に小さいが高速なメモリであることを知っています-定義は短く、かなり正確です。 ただし、コードのパフォーマンスに影響する要因を理解するには、キャッシュのメカニズムに関する「退屈な」詳細を知る必要があります。
この記事では、キャッシュのさまざまな機能とパフォーマンスへの影響を示す一連の例を見ていきます。 例はC#で、言語とプラットフォームの選択はパフォーマンス評価と最終的な結論に影響しません。 当然、妥当な範囲内で、配列からの値の読み取りがハッシュテーブルへのアクセスと同等の言語を選択した場合、解釈に適した結果は得られません。 斜体は、翻訳者のメモです。
---habracut---
例1:メモリアクセスとパフォーマンス
2番目のサイクルは最初のサイクルよりどれくらい速いと思いますか?
int [] arr = new int [64 * 1024 * 1024];
//
for ( int i = 0; i < arr.Length; i++) arr[i] *= 3;
//
for ( int i = 0; i < arr.Length; i += 16) arr[i] *= 3;
最初のサイクルはすべての配列値に3を掛け、2番目のサイクルは16番目の値ごとに掛けます。 2番目のサイクルは最初のサイクルの作業の6%しか実行しませんが、最新のマシンでは両方のサイクルがほぼ同じ時間で実行されます:それぞれ80ミリ秒と78ミリ秒 (私のマシンで)。
答えは簡単です-メモリへのアクセス。 これらのサイクルの速度は、整数乗算の速度ではなく、主にメモリサブシステムの速度によって決まります。 次の例でわかるように、RAMアクセスの数は最初と2番目のケースで同じです。
例2:キャッシュラインの効果
掘り下げ-1と16だけでなく、他のステップ値を試してください:
for ( int i = 0; i < arr.Length; i += K /* */ ) arr[i] *= 3;
以下は、ステップKのさまざまな値に対するこのサイクルの実行時間です。
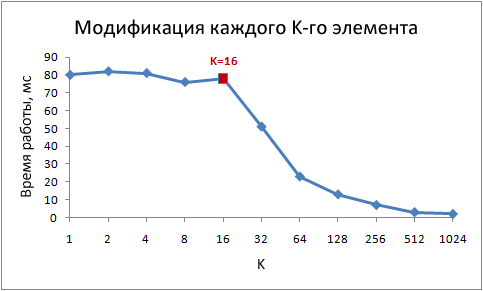
ステップ値が1〜16の場合、動作時間は実質的に変化しないことに注意してください。 ただし、値が16を超えると、ステップを2倍するたびに動作時間が約半分に減少します。 これは、サイクルが何らかの形で魔法のように速く動作し始めることを意味するのではなく、同時に繰り返される回数も減少します。 キーポイントは、1〜16のステップ値を持つ同じランタイムです。
これは、最新のプロセッサがメモリバイトにアクセスせず、キャッシュラインと呼ばれる小さなブロックにアクセスするためです。 通常、文字列サイズは64バイトです。 メモリから値を読み取ると、少なくとも1つのキャッシュラインがキャッシュに入ります。 この行からの値へのその後のアクセスは非常に高速です。
16のint値が64バイトを占有するという事実により、1から16までのステップのループは、同じ数のキャッシュライン、より正確には、アレイキャッシュのすべてのラインにアクセスします。 ステップ32で、2行ごとにアクセスし、ステップ64で4行ごとにアクセスします。
これを理解することは、いくつかの最適化方法にとって非常に重要です。 呼び出し回数は、メモリ内のデータの場所によって異なります。 たとえば、データの位置がずれているため、1つではなく2つのメモリアクセスが必要になる場合があります。 上記でわかったように、作業速度は2倍遅くなります。
例3:一次および二次キャッシュのサイズ(L1およびL2)
原則として、最新のプロセッサには2つまたは3つのレベルのキャッシュがあり、通常はL1、L2、およびL3と呼ばれます。 さまざまなレベルのキャッシュのサイズを調べるには、 CoreInfoユーティリティまたはWindows API関数GetLogicalProcessorInfoを使用できます。 どちらの方法も、各レベルのキャッシュラインのサイズに関する情報を提供します。
私のマシンでは、CoreInfoは32KB L1データキャッシュ、32KB L1命令キャッシュ、および4MB L2データキャッシュについて報告します。 各コアには独自の個人用L1キャッシュ、コアの各ペアに共通のL2キャッシュがあります。
キャッシュマップへの論理プロセッサ: * ---データキャッシュ0、レベル1、32 KB、Assoc 8、LineSize 64 * ---命令キャッシュ0、レベル1、32 KB、Assoc 8、LineSize 64 -*-データキャッシュ1、レベル1、32 KB、Assoc 8、LineSize 64 -*-命令キャッシュ1、レベル1、32 KB、Assoc 8、LineSize 64 **-ユニファイドキャッシュ0、レベル2、4 MB、Assoc 16、LineSize 64 -*-データキャッシュ2、レベル1、32 KB、Assoc 8、LineSize 64 -*-命令キャッシュ2、レベル1、32 KB、Assoc 8、LineSize 64 --- *データキャッシュ3、レベル1、32 KB、Assoc 8、LineSize 64 --- *命令キャッシュ3、レベル1、32 KB、Assoc 8、LineSize 64 -**ユニファイドキャッシュ1、レベル2、4 MB、Assoc 16、LineSize 64
この情報を実験的に確認してください。 これを行うには、16番目の値ごとにインクリメントする配列を見ていきましょう。これは、各キャッシュラインのデータを簡単に変更する方法です。 最後に到達すると、最初に戻ります。 配列のさまざまなサイズを確認すると、配列が異なるレベルのキャッシュに収まらなくなると、パフォーマンスが低下するはずです。
コードは次のとおりです。
int steps = 64 * 1024 * 1024; //
int lengthMod = arr.Length - 1; // --
for ( int i = 0; i < steps; i++)
{
// x & lengthMod = x % arr.Length,
arr[(i * 16) & lengthMod]++;
}
テスト結果:

私のマシンでは、32 KBと4 MBが顕著になるとパフォーマンスが低下します。これは、L1キャッシュとL2キャッシュのサイズです。
例4:命令の並行性
それでは、他の何かを見てみましょう。 あなたの意見では、これらの2つのサイクルのどちらがより速く実行されますか?
int steps = 256 * 1024 * 1024;
int [] a = new int [2];
//
for ( int i = 0; i < steps; i++) { a[0]++; a[0]++; }
//
for ( int i = 0; i < steps; i++) { a[0]++; a[1]++; }
少なくともテストしたすべてのマシンで、2番目のサイクルはほぼ2倍の速度で実行されることがわかりました。 なんで? ループ内のコマンドには異なるデータ依存関係があるためです。 最初のコマンドには、次の依存関係のチェーンがあります。

2番目のサイクルでは、依存関係は次のとおりです。

近代的なプロセッサの機能部分は、原則として、非常に多くではなく、特定の数の特定の操作を同時に実行できます。 たとえば、2つのアドレスでL1キャッシュからのデータへの並列アクセスが可能であり、2つの単純な算術命令を同時に実行することもできます。 最初のサイクルでは、プロセッサはこれらの機能を使用できませんが、2番目のサイクルでは使用できます。
例5:キャッシュの結合性
キャッシュを設計するときに答える必要がある重要な質問の1つは、特定のメモリ領域からのデータをキャッシュセルに格納できるか、キャッシュセルの一部にのみ格納できるかです。 3つの可能な解決策:
- 直接マッピングキャッシュ 、RAM内の各キャッシュラインのデータは、1つの所定のキャッシュセルにのみ保存されます。 マッピングを計算する最も簡単な方法は、memory_line_index%cache_cellsです。 同じセルにマップされた2つのラインを同時にキャッシュに入れることはできません。
- N入力の部分連想キャッシュ 、各ラインはN個の異なるキャッシュセルに格納できます。 たとえば、16入力キャッシュでは、グループを構成する16個のセルの1つにラインを格納できます。 通常、インデックスの下位ビットが等しい行は、同じグループを分離します。
- 完全連想キャッシュ 、任意のラインを任意のキャッシュセルに格納できます。 このソリューションは、その動作がハッシュテーブルと同等です。
たとえば、私のマシンでは、4 MBのL2キャッシュは16入力の部分的連想キャッシュです。 すべてのRAMは、インデックスの最下位ビットによって行のセットに分割されます。各セットの行は、16個のL2キャッシュセルの1つのグループに対して競合します。
L2キャッシュには65,536個のセル(4 * 2 20/64)があり、各グループは16個のセルで構成されているため、合計4,096個のグループがあります。 したがって、行インデックスの下位12ビットは、この行が属するグループを決定します(2 12 = 4 096)。 その結果、262 144の倍数(4 096 * 64)のアドレスを持つ行は、16セルの同じグループを共有し、その中の場所を求めて競合します。
結合性効果を明示するには、たとえば次のコードを使用して、1つのグループの多数の行を常に参照する必要があります。
public static long UpdateEveryKthByte( byte [] arr, int K)
{
const int rep = 1024 * 1024; //
Stopwatch sw = Stopwatch.StartNew();
int p = 0;
for ( int i = 0; i < rep; i++)
{
arr[p]++;
p += K; if (p >= arr.Length) p = 0;
}
sw.Stop();
return sw.ElapsedMilliseconds;
}
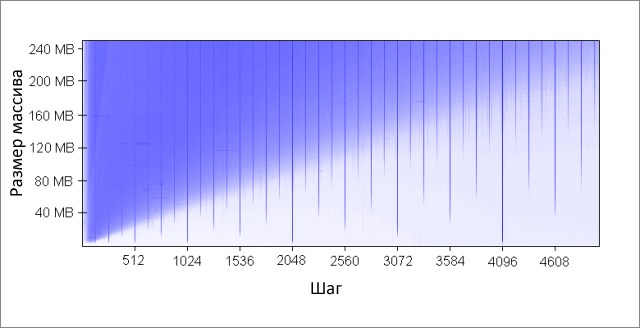
このメソッドは、配列のK番目の要素ごとにインクリメントします。 最後に到達すると、再び開始します。 かなり多数の反復(2 20 )の後、停止します。 さまざまなサイズの配列とステップKの値で実行しました。結果(青-長い実行時間、白-小さな):

青色の領域は、データが絶えず変化するため、キャッシュが必要なデータをすべて同時に収容できない場合に対応します 。 明るい青色は、約80ミリ秒、ほぼ白-10ミリ秒の動作時間を示します。
青い領域に対処しましょう:
- なぜ縦線が表示されるのですか? 垂直線は、1つのグループからアクセスされる行が多すぎる(16を超える)ステップ値に対応します。 このような値の場合、私のマシンの16入力キャッシュは、必要なすべてのデータを収容できません。
悪いステップ値のいくつかは、2の累乗:256と512です。たとえば、ステップ512と8 MBの配列を考えます。 このステップでは、512個のキャッシュグループ(262 144/512)のセルをめぐって互いに戦う32個のセクション(8 * 2 20/262 144)がアレイにあります。 セクション32、および各グループのキャッシュには16個のセルしかないため、全員に十分なスペースはありません。
2のべき乗ではないステップの他の値は、単に不運であり、同じキャッシュグループへの多数のアクセスを引き起こし、図に青い縦線が表示されます。 この時点で、数論の愛好家が考えるように招待されています。
- 4 MBの境界で垂直線が切れるのはなぜですか? 配列サイズが4 MB以下の場合、16入力キャッシュは完全な連想と同じように動作します。つまり、競合することなく配列内のすべてのデータを収容できます。 1つのキャッシュグループで競合するエリアは16個以下です(262 144 * 16 = 4 * 2 20 = 4 MB)。
- 左上に大きな青い三角形があるのはなぜですか? 小さなステップと大きな配列では、キャッシュが必要なすべてのデータに適合できないためです。 ここでは、キャッシュの結合性の程度が二次的な役割を果たします。制限はL2キャッシュのサイズに関連しています。
たとえば、16 MBの配列サイズと128のステップでは、128バイトごとにアクセスし、配列キャッシュの2行ごとに変更します。 キャッシュに2行ごとに保存するため、そのサイズは8 MBですが、私のマシンでは4 MBしかありません。
キャッシュが完全に関連付けられていても、8 MBのデータをキャッシュに保存することはできません。 512のステップと8 MBの配列サイズで既に調べた例では、必要なデータをすべて保存するために必要なキャッシュは1 MBだけですが、キャッシュの結合性が不十分なため、これを行うことはできません。
- 三角形の左側が徐々に強度を増しているのはなぜですか? 最大強度は、キャッシュラインのサイズに等しい64バイトのステップ値に該当します。 最初の例と2番目の例で見たように、同じ回線への順次アクセスには実質的に費用はかかりません。 16バイトのステップで、1つの価格で4つのメモリアクセスがあります。
ステップ値のテストでは反復回数が等しいため、ステップが安いほど時間が短縮されます。
キャッシュの結合性は、特定の条件下で証明できる興味深いものです。 この記事で説明した残りの問題とは異なり、それほど深刻ではありません。 間違いなく、これはプログラムを書くときに常に注意を払う必要があるものではありません。
例6:偽のキャッシュ分割
マルチコアマシンでは、キャッシュマッチングという別の問題が発生する場合があります。 プロセッサコアには、部分的または完全に分離されたキャッシュがあります。 私のマシンでは、L1キャッシュは(通常のように)別であり、各コアペアに共通の2つのL2キャッシュもあります。 詳細は異なる場合がありますが、一般的に、最新のマルチコアプロセッサにはマルチレベルの階層キャッシュがあります。 さらに、最速であるが最小のキャッシュは個々のコアに属します。
コアの1つがキャッシュの値を変更すると、他のコアは古い値を使用できなくなります。 他のコアのキャッシュの値を更新する必要があります。 さらに、キャッシュはラインレベルのデータで動作するため、キャッシュライン全体を完全に更新する必要があります。
この問題を次のコードで示します。
private static int [] s_counter = new int [1024];
private void UpdateCounter( int position)
{
for ( int j = 0; j < 100000000; j++)
{
s_counter[position] = s_counter[position] + 3;
}
}
4コアマシンで、4つのスレッドから同時にパラメーター0、1、2、3でこのメソッドを呼び出すと、操作時間は4.3秒になります。 しかし、パラメータ16、32、48、64でメソッドを呼び出すと、実行時間はわずか0.28秒になります。
なんで? 前者の場合、各瞬間にスレッドによって処理される4つの値はすべて、1つのキャッシュラインに分類される可能性が最も高くなります。 1つのコアが次の値を増やすたびに、他のカーネルにこの値を含むキャッシュセルを無効としてマークします。 この操作の後、他のすべてのカーネルは行を再度キャッシュする必要があります。 これにより、キャッシングメカニズムが動作不能になり、パフォーマンスが低下します。
例7:鉄の複雑さ
今でも、作業キャッシュの原則があなたにとって秘密ではないとき、鉄はあなたに驚きを与えます。 プロセッサーは、最適化方法、ヒューリスティック、および実装の他の微妙な点で互いに異なります。
一部のプロセッサのL1キャッシュは、異なるグループに属している場合は2つのセルに並行してアクセスできますが、1つに属している場合は連続的にしかアクセスできません。 私の知る限り、同じセルの異なる区画への並列アクセスを提供するものもあります。
プロセッサは、トリッキーな最適化であなたを驚かせることができます。 たとえば、スプリットキャッシュに関する前の例のコードは、思ったように自宅のコンピューターでは機能しません。最も単純な場合、プロセッサーは作業を最適化し、悪影響を減らすことができます。 コードがわずかに変更されると、すべてが所定の位置に収まります。
奇妙な鉄の癖の別の例を次に示します。
private static int A, B, C, D, E, F, G;
private static void Weirdness()
{
for ( int i = 0; i < 200000000; i++)
{
<- >
}
}
<some code>の代わりに3つの異なるオプションを使用すると、次の結果が得られます。

フィールドA、B、C、Dの増分には、フィールドA、C、E、Gの増分よりも時間がかかります。さらに奇妙なことに、フィールドAおよびCの増分には、フィールドA、C、 および E、Gよりも時間がかかります。これの理由は何ですか?しかし、おそらくそれらはメモリバンクに接続されています( はい、あなたの考えではなく、通常の3リットルのメモリの節約バンクに接続されています )。 このテーマについて考えて、コメントで話してください。
私はマシン上で上記のことを観察しませんが、時には異常に悪い結果があります-ほとんどの場合、タスクスケジューラは独自の「修正」を行います。
この例から次の教訓を学ぶことができます。鉄の挙動を完全に予測することは非常に困難です。 はい、たくさん予測できますが 、測定とテストを通じて予測を常に確認する必要があります。
おわりに
上記のすべてが、プロセッサキャッシュの設計の理解に役立つことを願っています。 これで、取得した知識を実際に使用して、コードを最適化できます。
* Source code was highlighted with Source Code Highlighter .