入力コレクションがモノリシックのままであり、ワークフローがアイテムを1つずつ選択し始めると想像してください。 T.O. 選択は次のアクションに限定されます。
- ロックを設定する
- アイテム選択
- ロック解除
明らかに、これはインストール/ロック解除に大きなオーバーヘッドを与えます。 特に、ワークフローによる要素の高速処理の場合に顕著になります。 元のコレクションをパーツに分割することで、これを取り除くことができます。
機器の機能を最も効果的に使用して、処理の並列化を最大化するために、要素の入力シーケンスを分割する方法は? 一般的なケースでは、LINQ要求を処理するワーカースレッドの数のみが確実にわかっています。 各アイテムの処理時間を事前に予測することはできません。 また、コレクションの長さは不明です(もちろん、要素の数は事前に計算できますが、このアクションは潜在的に長く、リソースを大量に消費します)。 つまり、実行のスレッド間で要素を「公平に」分配することはできません。 最良の解決策は、ソースシーケンス全体を一度に共有するのではなく、異なるサイズの部分の形式でデータを出力することです。 Parallel Extensionsはまさにそれを行い、次のように機能します。
- 各ワークフローには、処理のための要素のキューがあります。
- キューの初期サイズは1、つまり ソースコレクションからストリームごとに1つの要素が選択されます。
- キューサイズが大きくなります。コレクションに再度アクセスすると、コレクションが2倍になります。 各スレッドのキューの長さは個別に計算され、特定の値まで増加します。その後、成長は停止します。
外観は次のとおりです。 時間0で、各ワーカースレッドはコレクションから1つのアイテムを受け取ります。
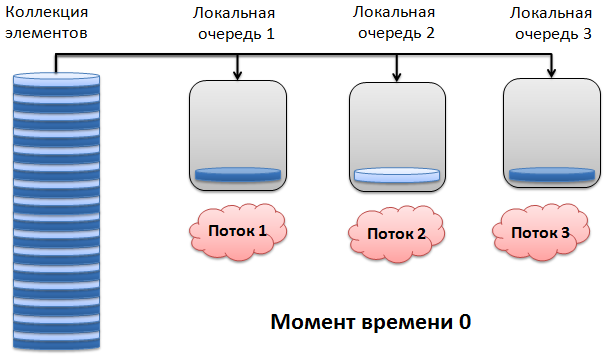
次の瞬間1で、ワークフロー1および2は要素の処理を終了し、入力コレクションから2つの要素を選択します。 同時に、スレッド3は最初に選択された要素を引き続き処理します。

時間が経過すると、ストリーム1と2は前のステップで取得した要素の処理を終了し、それぞれ4つの要素を受け取ります。 スレッド3も処理を完了し、2つの新しいスレッドを要求します。
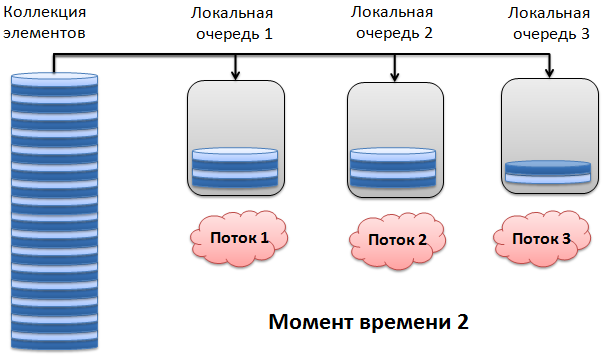
まあなど。 ここでは、ロードバランスが維持されます。1つのワーカースレッドが要素を処理する時間が長すぎると、残りのスレッドがコレクションからますます多くなり、全体的な効率が向上します。 ストリームキューは、サイズが512バイトに達するまで拡大します。 つまり、たとえばInt32型の要素の最大数は128です。
もちろん、考慮される方法は普遍的ではなく、場合によっては最良ではありません。 使用するソリューションにいくつかの追加を提供できます。 たとえば、各要素の平均処理時間を測定し、このパラメーターを考慮して部品のサイズを変更します。 しかし、Parallel Extensionsの開発者は、上記のアプローチを中止することにしました。 ほとんどのシナリオで実証済みであるため、実装されました。
ただし、元のコレクションの要素を配布する独自の原則を実装することは可能です。 Paralell Extensionsを使用するアプリケーションの例があります。 その中には、入力コレクションを分割する別の方法の実装があります。