OpenMPの並列プログラミングの技術に精通していることに注意してください。 ディレクティブを考慮してください:アトミック、リダクション。
アトミックディレクティブ
配列の要素を要約するコードを考えてみましょう。
intptr_t A [1000]、合計= 0; for(intptr_t i = 0; i <1000; i ++) A [i] = i; for(intptr_t i = 0; i <1000; i ++) sum + = A [i]; printf( "Sum =%Ii \ n"、sum);
このコードの結果は次のとおりです。
合計= 499500 続行するには任意のキーを押してください。 。 。
ompおよびparallelディレクティブを使用して、このコードを並列化してみましょう。
#pragma omp parallel for for(intptr_t i = 0; i <1000; i ++) sum + = A [i];
残念ながら、作業中に競合状態が発生するため、このような並列化は正しくありません。 複数のスレッドは、読み取りと書き込みのために同時にsum変数にアクセスしようとします。 呼び出しのシーケンスは次のとおりです。
変数sumの値= 500; 最初のストリームのiの値= 1; 2番目のストリームのiの値= 501; スレッド1:プロセッサレジスタ=合計 スレッド2:プロセッサレジスタ=合計 スレッド1:プロセッサレジスタ+ = i ストリーム2:プロセッサレジスタ+ = i ストリーム2:sum =プロセッサレジスタ スレッド1:sum =プロセッサレジスタ 変数の値は、1002ではなくsum = 501です。
デモコードを実行して、実際の並列化の誤りを検証することもできます。 特に、私は受け取った:
合計= 486904 続行するには任意のキーを押してください。 。 。
クリティカルセクションは、一般的な変数の更新エラーを防ぐために使用できます。 ただし、変数「sum」が一般的で、演算子の形式がsum = sum + exprである場合、「atomic」ディレクティブがより便利な手段です。 一部のアトミック操作はプロセッサ命令で直接置き換えることができるため、アトミックディレクティブはクリティカルセクションよりも高速です。
このディレクティブは、直後の代入演算子を参照し、その左部分に共通変数を使用した正しい動作を保証します。 ステートメントの実行中、この変数へのアクセスは、操作を実行するスレッドを除く、現在実行中のすべてのスレッドに対してブロックされます。
アトミックディレクティブは、次のタイプの操作にのみ適用されます。
- X BINOP = EXPR
- X ++
- ++ X
- X--
- −−X
ここで、Xはスカラー変数、EXPRは変数xが存在しないスカラー型の式、BINOPはアンロード演算子+、*、-、/、&、^、|、<<、>>です。 他のすべての場合、アトミックディレクティブは使用できません。
コードの修正バージョンは次のとおりです。
#pragma omp parallel for
for(intptr_t i = 0; i <1000; i ++)
{
#pragma omp atomic
sum + = A [i];
}
このソリューションは正しい結果をもたらしますが、非常に非効率的です。 上記のコードの速度は、シーケンシャルバージョンの速度よりも遅くなります。 アルゴリズムの動作中、ロックは絶えず発生し、その結果、コアのほぼすべての作業が予想どおりに削減されます。 この例では、atomicディレクティブがどのように機能するかを示すためにのみ使用されます。 実際には、このディレクティブの使用は合理的であり、シェア変数へのアクセスは比較的まれです。 例:
符号なしカウント= 0;
#pragma omp parallel for
for(intptr_t i = 0; i <N; i ++)
{
//スロー関数
if(SlowFunction())
{
#pragma omp atomic
カウント++;
}
}
アトミックディレクティブが適用される式では、代入演算子の左側の変数でのみ機能するのはアトミックであり、右側の計算はアトミックである必要はないことに注意してください。 アトミックディレクティブが式で使用される関数の呼び出しに影響を与えない例を使用して、これを検討してください。
クラスの例
{
公開:
符号なしのm_value;
例():m_value(0){}
符号なしGetValue()
{
return ++ m_value;
}
符号なしのGetSum()
{
符号なし和= 0;
#pragma omp parallel for
for(ptrdiff_t i = 0; i <100; i ++)
{
#pragma omp atomic
sum + = GetValue();
}
戻り値;
}
};
この例にはレースステータスエラーが含まれており、返される値は開始ごとに変わる場合があります。 コードでは、「atomic」ディレクティブを使用して、変数「sum」の増加が保護されています。 ただし、アトミックディレクティブはGetValue()関数の呼び出しには影響しません。 呼び出しは並列スレッドで発生し、GetValue関数内で操作「++ m_value」を実行するとエラーが発生します。
削減指令
質問するのは理にかなっていますが、配列の要素をすばやく追加する方法は? 削減ディレクティブが役立ちます。
ディレクティブの形式:削減(演算子:リスト)
可能な演算子は、「+」、「*」、「-」、「&」、「|」、「^」、「&&」、「||」です。
リスト-一般的な変数の名前をリストします。 変数はスカラー型でなければなりません(たとえば、float、int、またはlongで、std :: vector、int []などではありません)。
動作原理:
- 各変数について、各スレッドでローカルコピーが作成されます。
- ローカルコピーは、演算子のタイプに従って初期化されます。 加算演算の場合-0またはその類似体、乗算演算の場合-1またはその類似体。 表N1も参照してください。
- 変数のローカルコピーが実行された後、並列ドメインのすべての演算子を実行した後、指定された演算子が実行されます。 演算子の実行順序は定義されていません。
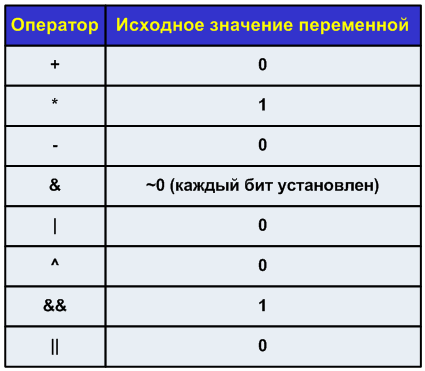
表N1-削減演算子
「削減」を使用すると、効率的に動作するコードは次の形式になります。
#pragma omp parallel for reduction(+:sum) for(intptr_t i = 0; i <1000; i ++) sum + = A [i];
Parallel Notesの次号では、続きます...