今、私はそれができることを自慢できます:
var DB = new QueryManager(1, @"Output\md.zip", true, 0.4, @"Output\index.zip", 50, @"Output\imd.zip", 0.0, true);
var firstObjectID = DB.AddObject(new MyClass{ Name = "Hello", Data = "World!" });
var secondObjectID = DB.AddObject(new MyClass{ Name = "Hi", Data = "People!" });
var firstSelectedObject = DB.Select(firstObjectID).Data as MyClass;
var secondSelectedObject = DB.Select(secondObjectID).Data as MyClass;
Console.WriteLine("First object ID: {0}\nSecond object ID: {1}\n", firstObjectID, secondObjectID);
Console.WriteLine("First selected object: {0}", firstSelectedObject.Name + ", " + firstSelectedObject.Data);
Console.WriteLine("Second selected object: {0}", secondSelectedObject.Name + ", " + secondSelectedObject.Data);
DB.Dispose();
var DB2 = new QueryManager(1, @"Output\md.zip", false, 0.4, @"Output\index.zip", 50, @"Output\imd.zip", 0.0, true);
var firstSelectedObject2 = DB2.Select(firstObjectID).Data as MyClass;
var secondSelectedObject2 = DB2.Select(secondObjectID).Data as MyClass;
トーキングクラス図(完全ではない-使用する必要があるもの):
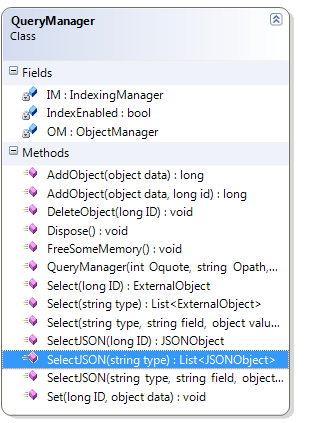 |
memcachedのシンプルさに触発されたので、それほど多くのリクエストはありません。 要求は、十分なRAMがある場合にのみトリガーされます。
正直なところ、私はこの技術を使用してデータ構造を読み取り/ディスクに保存します。 OSOSDB自体が、クールなNewtonsoft.Jsonシリアライザーと.NET用の標準アーカイブツールを使用しているため、非常に便利です。 これにより、データスキームを事前に作成する必要なく、ディスクに任意のデータ構造を配置できます。これは、N個のオブジェクトの一部で行われ、Nを指定できます。
「なぜ自転車を生産するのか?」という質問を楽しみにしています-大きなファイルの処理は多くの場合より高速であり、開発者がアプリケーションでこれをより効率的に行う方法に気付いた場合、記録のパフォーマンスは大幅に向上します(当然、信頼性は犠牲になります)。