idf(t)はドキュメント全体とは無関係であるため、ドキュメントから独立していることに注意することが重要です。 これは、式を見てもわかりにくいです:
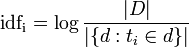
彼女はおそらくいくつかの説明が必要です。 だから| D | これは、ドキュメントの部隊の力です。つまり、ドキュメントの数だけです。 彼を知っているので、何も考慮する必要はありません。 対数の分母は、関心のあるトークンt_iを含むドキュメントdの数です 。
これはどのように計算できますか? 多くの方法がありますが、私は以下を提案します。 入力として、 tf(t、d)の異常値を計算したタスクの結果を使用します。これらは次のように見えたことを思い出してください。
1_the 3 1_to 1 ... 2_the 2 2_from 1 ... 37_ロンドン1
私たちの仕事は何でしょうか? 理解したい:たとえば、theという単語を含むドキュメントの数
the
? 一般的に、ソリューションは直感的です
2_the
などの各値を
2_the
、それをカップル(
2
、
the
)に分割し、マップ問題の出力に書き込みます。
1
すべてのドキュメントに対してこれを行うことにより、次の形式でデータを受け取ります。
1 1に 1 1から ロンドン1
さらにすべてが多かれ少なかれ明白です:reduce-taskはこのデータを受け取り(ユニットの用語とリストを受け取ります)、これらのユニットの数を考慮して以下を与えます:
2 1に 1から ロンドン1
証明するために必要でした。 idf(t)を直接計算するタスクは簡単になりました(ただし、単語のリストが非常に大きくなる可能性があるため、グリッド上でも実行できます)。
最後のステップでは、TF-IDFを直接カウントします。 これがトラブルの始まりです! 問題は、 2つのファイルがあることです 。1つはTF値、もう1つはIDF値です。 一般的なケースでは、どちらも記憶に登りません。 どうする 行き止まり!
行き止まりですが、実際はそうではありません。 奇妙な解決策ですが、パススルーなどのMap / Reduceで非常に人気があります。 例で私の考えを説明します。 TF値(上記を参照)を使用してファイルを処理するときに、ユニティではなく、マップタスクの
docID_tfValue
の組み合わせを記述し
docID_tfValue
か? 次のようになります:
1_3 1_3へ 2_2 2_1から ... ロンドン37_1
この単語またはその単語が属するドキュメントの数をカウントすることはできます。実際、ユニットを合計するのではなく、単にその数をカウントしました。 同時に、いくつかの追加データがあります。つまり、reduceタスクの出力を次のように変更できます。
2_1_3#ドキュメントの数-ドキュメントID-このドキュメント内の 2_2_2 1_1_3へ 1_2_1から ... ロンドン1_37_1
次の面白い状況があります-レデューサーは実際にはデータ量を削減しませんでしたが、いくつかの新しい特性を追加しました! 今何ができますか? はい、ほとんど何でも! Nと| D |の値を知っていると仮定します (つまり、ケース内のトークンの数とドキュメントの数)最も単純なMap / Reduceプログラム(Reduceは必要ありません)を実装できます。 着信回線ごとに、次の形式でデータを表示します
期間=キー (docCount、docId、countInDoc)= value.split( "_")
擬似コードが非常に条件付きであることを理解することを願っています(アンダースコア文字を使用して値を区切るのと同じように)-しかし、私にとっては本質は明らかです。 これで次のことができます。
tf = countInDoc / TOTAL_TOKEN_COUNT idf =ログ(TOTAL_DOC_COUNT / docCount) 結果= tf * idf 出力(キー= docId + "_" +用語、値=結果)
私たちは何をしましたか? TF-IDF値を取得しました。
この記事のフレームワークでは、テキスト本文のTF-IDF値を計算することで例を終了しました。 ケースのパワーを増やしてもメモリ不足の問題は発生せず、計算時間を増やすだけであることに注意してください(クラスターに新しいノードを追加することで解決できます)。 Map / Reduceで複雑なタスクを解決するためによく使用される、一般的なデータパススルーテクニックの1つを検討しました。 一般に、Map / Reduceアプリケーションの設計原則をいくつか学びました。 さらなる記事では、実際のデータに関するこの問題やその他の問題の解決策を、実用的なコードの例とともに検討します。
PSいつものように、質問、コメント、説明、レビューは大歓迎です! できる限り明確にしようとしましたが、完全には成功しなかったかもしれません-それについて私に書いてください!
家庭での読書には、ScribdのClouderaの仲間が投稿したスライドを表示することをお勧めします。
- Hadoopトレーニング#1:大規模な思考
- Hadoopトレーニング#2:MapReduceとHDFS
- ...およびこのシリーズの残りのプレゼンテーション。
興味のある方は、記事の英語版(全体)がこちらから入手できます: romankirillov.info/hadoop.html-PDF版もダウンロードできます。