パート2.データ収集。
パート3.基本的な指標。
パート4.統計から分析まで
ウェブ分析の世界への旅を続けます。 最後の部分では、統計の分析と収集したデータからの情報の取得についに取り組みました。 ユーザーの行動を追跡できることがわかりましたが、この行動の理由はわかりません。 また、目的のアクションを刺激し、望ましくないアクションを防ぐには、これらのアクションの理由を正確に知る必要があります。
経験豊富なアナリストは、どのようにしてユーザーの「頭の中に入り込み」、サイト上で平均化されたデータのみを持っているのでしょうか? 魔法はありません。 彼らはこれらのアウゲアンean舎を分解する手順を実行します。
-データのセグメント化:すべてのユーザーを特定の基準に基づいてグループに分割し、すべてのユーザーの動作ではなく、これらの各グループの動作を個別に考慮します。
-仮定を立ててテストします。彼らは現在の状況についての可能性のある説明を探し出し、これらの仮定に基づいて状況に影響を与え、結果を観察します。
データのセグメンテーション
「データをセグメント化しないことは人道に対する罪です」
アビナッシュ・コシク
平均化は、あなたが最も恐れる必要があるものです。 もちろん、広告からのユーザーの統計情報をランダムな訪問者の統計情報と要約することができます。 すべての都市および国からの訪問を追加します。 人気のジョークのように、「遺体安置所を含む病院の平均気温」を考慮してください。 ただし、この場合、最小限の有用なデータを受け取ることになり、それらから導き出される結論はほとんどの場合間違っています。
始める前に、ユーザーについて知っていることをすべて忘れてください。 公平な統計を分析する必要があります。2つのことがあなたを止めることができます。ユーザーについてのあなた自身の意見を利用しようとすることと、聴衆全体の「平均的な肖像」を作りたいという欲求です。 反対は真実です。ポートレートやグループが異なるほど、これらの各グループを満足させる方法について学ぶことができます。
セグメンテーションは、ページが表示されるときにWeb分析システムが記憶するパラメーターによって可能です。 例:
-地域別
-ユーザーがアクセスしたサイトのアドレスへ
-検索エンジンであなたのサイトを見た人のために-リクエストにより、彼がそれを見つけるのを助けました
-広告から来た人のために-広告と広告プラットフォームによって
-ユーザーに表示される最初のページまで
-コンピューターの技術的能力とユーザーのインターネット接続による
-ユーザーが以前にサイトにアクセスしたかどうか
-サイトでのユーザーのアクションによる。
セグメンテーションの仕組みの簡単な例を次に示します。
あなたはオンラインストアの所有者であり、もちろん、あなたはその収益性をどのように高めることができるかを気にかけています。 Google Analyticsにアクセスすると、次の図が表示されます。
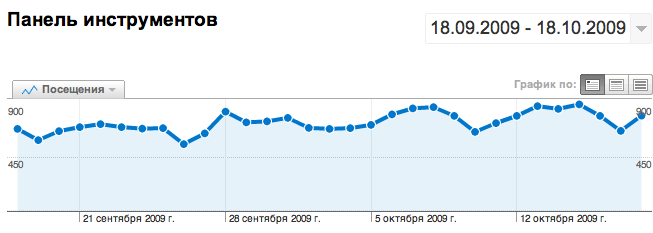
これは、すべてのユーザーの平均データです。 ダイナミクスのみに関心がある場合があります-それらの変動は、状況が変化したことを示す信号であり、追加の調査を行う必要があります。 しかし、データが可能なすべてのパラメーターによってセグメント化される、本当の啓示がさらに深く、私たちを待っています。
たとえば、「コンテンツ」セクションに行きましょう。 リストはすぐに(サイトに正しいタイトルタグがある場合)どのページについて話しているかを理解するので、「見出しによるコンテンツ」アイテムを使用すると便利です。
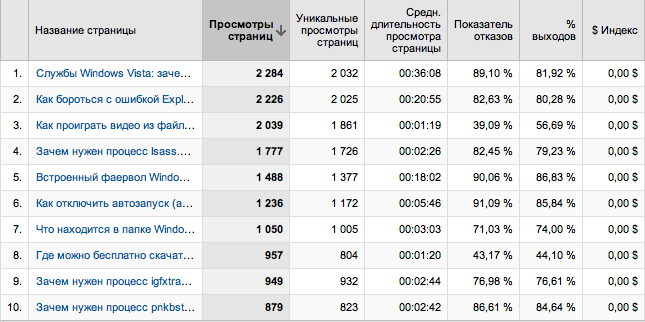
ユーザーが開いたページで訪問を分割しました。 ここにはもっと興味深いものがあります。 見ることができます:
-最も頻繁にアクセスされるページ(ページビュー)
-最も遅れるのはどれか(平均ページビュー時間)
-このページからサイトの表示を開始した訪問者のうち、別のページに切り替えなかったが、すぐにサイトを閉じたユーザーの割合(直帰率)
-このページでサイトの閲覧を終了した訪問者の割合(離脱の割合)。
パラメータ計算の精度は、収集されるデータの量に依存することに注意してください。 たとえば、ページを10回表示し、2回拒否された場合、直帰率が20%であることを確信することはできません:より多くの統計を収集することにより、結果を調整でき、実際の数字は10%と30%の両方を拒否できます。 最初の近似として、値の変動が測定量の根のプラスまたはマイナスであると仮定できます。 したがって、たとえば、90〜110人のユーザーの出席率の変動は、規模の体系的な変化を意味しません。 全身の変化は時々目に見えますが、これに頼るべきではありません。 従来の統計システムでは傾向線を作成できないため、正確な測定のために、統計をExcelに読み込むか、大きな測定間隔をとることができます。 後でデータの信頼性を計算するためのより正確な式を示します。
これに関連するGoogleアナリティクスの使用を妨げる問題が1つあります。インジケーターでページを並べ替えると、最も人気のないものが上がります。
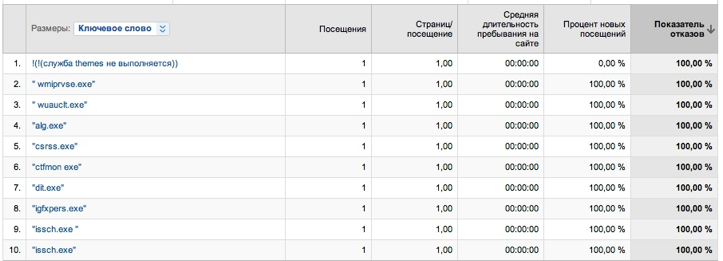
なぜこれが起こっているのかは明らかですが、このデータは役に立たないため、精度がゼロです。 ページ、キーワード、またはその他のセグメントの数に応じてさまざまな方法でこれを処理できます。正直なところ、Excelでインプレッションの降順で並べ替えてテーブルをエクスポートし、それから「ロングテール」を切り取って並べ替えるよりも良い方法はわかりません他の分野で。
これがなぜ必要なのかは明らかです。これらのパラメーターのいずれかが異常なセグメントは、特に重要です。他のセグメントの値は明らかに多かれ少なかれです。 これは通常、次の理由で発生します。
-トラフィックの違い:このセグメントを表すユーザーは他のユーザーとは異なります。 たとえば、モスクワのみで機能するオンラインストアの場合、エカテリンブルクからの訪問者は不適切であり、彼らにとっては失敗が多く、目標が少なく、表示深度が低くなります。
-ページの品質の違い。 ページがそのコンテンツをユーザーから隠し、サイトで何ができるかを理解する助けにならず、さらに先へ進む必要があることを彼に納得させない場合、ユーザーはサイトで失われる可能性が高くなります。 西側では、説得デザインは全体的な規律ですが、それについては後で詳しく説明します。
-多くの人がサイトとのユーザーインタラクションのモデルを簡素化しようとするときに忘れてしまうのは、ページにアクセスしたユーザーの目標とページのコンテンツの対応です。 この種の典型的な間違いは、ホームページを広告キャンペーンのランディングページとして使用することです。 特定の製品の割引を約束する広告をクリックすると、ユーザーは大規模なストアのメインページに表示されます。 この場合、彼はすでに期待していたものを望んでいないか、見つけることができない可能性が高くなります。 同様のエラーは、より多くの訪問者を誘引しようとして、広告主がバナーに「25%割引!」と書き込み、ウェブサイトのエントリページでオファーを「忘れる」と発生します。
これら3つのカテゴリについて議論し、仮説を作成してテストし、サイトにとって重要な指標を増やすことができます。
以下の部分では、分析計画の作成、各主要パラメーターの統計に基づく仮定の構築、およびそれらのチェックについて説明します。