はじめに
パターン認識、コンピュータービジョン、機械学習に関する一連の記事を続けます。 今日は、eigenfaceと呼ばれるアルゴリズムの概要を紹介します。

このアルゴリズムは、基本的な統計特性の使用に基づいています:平均( mat。Expectation )および共分散行列 。 主成分法を使用する 。 固有値や固有ベクトルなどの線形代数の概念にも触れます(wiki: ru 、 eng )。 さらに、多次元空間で作業します。
これがどれほど恐ろしく聞こえても、このアルゴリズムはおそらく私が考えた最も単純なアルゴリズムの1つであり、その実装は数十行を超えず、同時に多くのタスクで良い結果を示します。
私にとって、eigenfaceは、私が開発してきた過去1.5年以来興味深いものです。これには、さまざまなデータ配列を処理する統計アルゴリズムが含まれます。
ツールキット
私のささやかな経験のフレームワーク内で開発された方法論によると、いくつかのアルゴリズムを検討した後、C / C ++ / C#/ Pythonなどで実装する前に、数学モデルを迅速に(可能な限り)作成してテストする必要があります、何かを数えるために。 これにより、必要な調整を行ったり、エラーを修正したり、アルゴリズムについて考えたときに考慮されなかったものを発見したりできます。 これには、 MathCADを使用します。 MathCADの利点は、膨大な数の組み込み関数とプロシージャと共に、古典的な数学表記を使用することです。 大まかに言えば、数学を知っていて、数式を書くことができれば十分です。
アルゴリズムの要約
機械学習シリーズのアルゴリズムと同様に、固有顔を最初にトレーニングする必要があります。これには、認識したい顔の画像であるトレーニングセットが使用されます。 モデルがトレーニングされた後、いくつかの画像を入力し、その結果、質問に対する答えを取得します:トレーニングサンプルのどの画像が入力に例を持っている可能性が高いか、またはいずれにも対応していません。
アルゴリズムのタスクは、基本的なコンポーネント(画像)の合計として画像を表すことです:

ここで、iは元のサンプルの中央(つまり、マイナス)i番目の画像、w jは重み、u jは固有ベクトル(固有ベクトル、またはこのアルゴリズムのフレームワークでは固有フェイス)です。

上の図では、固有ベクトルの加重加算と平均の加算により元の画像を取得しています。 つまり wとuがあれば、元のイメージを復元できます。
トレーニングサンプルを新しい空間に投影する必要があります(通常、空間は元の2次元画像よりも次元がはるかに大きい)。各次元は、プレゼンテーション全体に一定の貢献をします。 主成分法を使用すると、ある意味で最適な場所にデータが配置されるように、新しいスペースの基礎を見つけることができます。 理解するために、新しい空間では、いくつかの次元(別名、主成分または固有ベクトルまたは固有面)がより一般的な情報を「運ぶ」一方、他の次元は特定の情報のみを運ぶと想像してください。 原則として、高次の次元(低い固有値に対応)は、最大の固有値に対応する最初の次元よりもはるかに有用性の低い情報(この場合、有用性はサンプル全体の一般化されたアイデアを与えるもの)を運びます。 有用な情報のみで寸法を残して、元のサンプルの各画像が一般化された形式で提示される特徴空間を取得します。 これは非常に単純化されたアルゴリズムの考え方です。
さらに、いくつかの画像を手元に用意して、事前に作成したスペースに表示して、このサンプルが最も近いトレーニングサンプルの画像を特定できます。 すべてのデータから比較的大きな距離にある場合、この画像は高い確率でデータベースに属していません。
より詳細な説明については、ウィキペディアの外部リンクリストを参照することをお勧めします。
小さな余談。 主成分分析の方法には、かなり広い用途があります。 たとえば、私の作品では、これを使用して、データ配列内の特定のスケール(時間的または空間的)、方向、または周波数のコンポーネントを選択しています。 データ圧縮の方法として、または多次元サンプルの初期寸法を縮小する方法として使用できます。
モデル作成
Olivetti Research Lab(ORL)Face Databaseを使用して、トレーニングサンプルをコンパイルしました。 40人の人々の写真が10枚あります。

アルゴリズムの実装を説明するために、ここでMathCADの関数と式を含むスクリーンショットを挿入し、それらについてコメントします。 行こう
1。

faceNumsは、トレーニングで使用される顔番号のベクトルを設定します。 varNumsはバリアント番号を設定します(データベースの説明によれば、同じ人物の10個の画像ファイルのそれぞれに40個のディレクトリがあります)。 トレーニングセットは4つの画像で構成されています。
次に、ReadData関数を呼び出します。 データのシーケンシャルな読み取りと画像のベクトルへの変換を実装します(TwoD2OneD関数)。
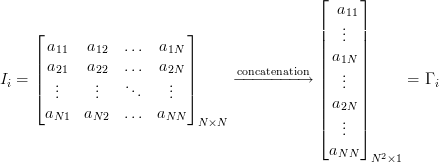
したがって、出力には、各列がベクトルに展開された「イメージ」である行列があります。 このようなベクトルは、多次元空間内の点と見なすことができ、次元はピクセル数によって決定されます。 私たちの場合、92x112サイズの画像は10304要素のベクトルを与えるか、10304次元空間に点を設定します。
2.トレーニングセット内のすべての画像を、平均画像を減算して正規化する必要があります。 これは、すべての画像に共通する要素を削除して、一意の情報のみを残すために行われます。

AverageImg関数は、平均のベクトルをカウントして返します。 このベクトルを画像に「ロール」すると、「平均化された顔」が表示されます。

Normalize関数は、各画像から平均値のベクトルを減算し、平均サンプルを返します。

3.次のステップは、トレーニングセット内の各画像の固有ベクトル(固有フェース)uと重みwの計算です。 つまり、これは新しいスペースへの移行です。

共分散行列を計算し、主成分(固有ベクトルでもあります)を見つけ、重みを考慮します。 アルゴリズムを詳しく知る人は数学に入ります。 この関数は、重み行列、固有ベクトル、固有値を返します。 これは、新しいスペースに表示するために必要なすべてのデータです。 この場合、トレーニングセットの要素の数に応じて、4次元空間で作業します。残りの10304-4 = 10300次元は縮退しているため、考慮しません。
一般に、固有値は必要ありませんが、いくつかの有用な情報をそれらから追跡できます。 それらを見てみましょう:
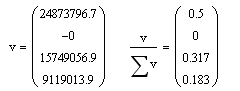
固有値は、実際には主成分の各軸に沿った分散を示します(各成分は空間の1つの次元に対応します)。 正しい式、このベクトルの合計= 1を見てください。各要素は、データの合計分散への寄与を示しています。 1および3の主要コンポーネントが合計0.82になることがわかります。 つまり 次元1および3には、すべての情報の82%が含まれています。 2番目の次元は折りたたまれており、4番目の次元は情報の18%を伝達するため、必要ありません。
認識
モデルが構成されます。 テストします。

24個の要素の新しい選択を作成しています。 最初の4つの項目は、トレーニングセットと同じです。 残りは、トレーニングセットの異なるバージョンの画像です。

次に、データをロードし、Recognizeプロシージャに渡します。 その中で、各画像は平均化され、主成分の空間にマッピングされ、重みwが見つかります。 ベクトルwがわかったら、既存のオブジェクトのどれに最も近いかを判断する必要があります。 これを行うには、dist関数を使用します(パターン認識問題の古典的なユークリッド距離の代わりに、異なるメトリックを使用することをお勧めします: マハロノビス距離 )。 この画像が最も近くにあるオブジェクトの最小距離とインデックスが見つかります。
上記の24個のオブジェクトのサンプルでは、分類子の効率は100%です。 しかし、1つのニュアンスがあります。 ソースデータベースにない画像を入力に適用すると、ベクトルwが計算され、最小距離が検出されます。 したがって、基準Oが導入されます。最小距離<Oの場合、画像が認識可能なクラスに属することを意味し、最小距離> Oの場合、そのような画像はデータベースにありません。 この基準の値は経験的に選択されます。 このモデルでは、O = 2.2を選択しました。
トレーニングルームにいない人のサンプルを作成し、分類器が偽サンプルをどの程度効果的に除外するかを見てみましょう。
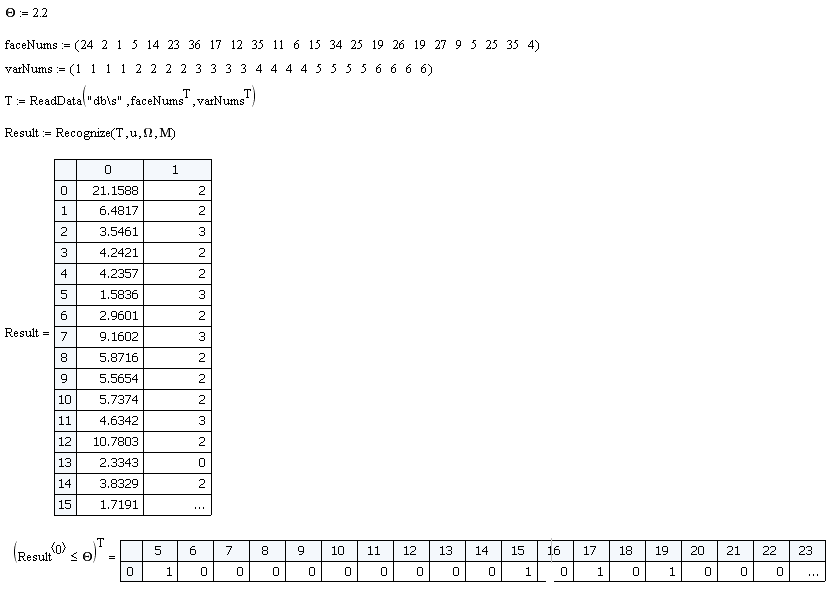
24個のサンプルのうち、4個の誤検出があります。 つまり 効率は83%でした。
おわりに
一般的に、シンプルでオリジナルのアルゴリズム。 繰り返しますが、より大きな次元の空間では、多くの有用な情報が「隠されている」ことを証明しています。これはさまざまな方法で使用できます。 other他の高度な技術と一緒に、eigenfaceを使用してタスクの解決の効率を改善できます。
たとえば、単純な距離分類器を分類器として使用します。 ただし、 サポートベクターマシンやニューラルネットワークなど、より高度な分類アルゴリズムを適用することもできます。
次の記事では、サポートベクターマシンについて説明します。 比較的新しく非常に興味深いアルゴリズムで、多くのタスクでNSの代替として使用できます。
記事を書くときに、次の資料が使用されました。
onionesquereality.wordpress.com
www.cognotics.com
材料:
MathCAD 14の計算シート
UPD:
私は多くの不可解で恐ろしい数学を見ています。 2つの方法があります。
1.アルゴリズムのすべてのアクションのポイント全体を理解したい場合は、基本的なことを理解することから始める必要があります。 行列、主成分の方法、固有ベクトルと値の意味と意味。 それが何であるかを知っていれば、すべてが明らかになります。
2.アルゴリズムを単に実装して使用する場合は、MathCADの計算シートをダウンロードします。 パラメータを実行、監視、変更します。 画面の床で計算が行われ、行列の乗算よりも複雑なものはありません(固有ベクトルを計算するための組み込み関数を除き、それを使用する必要はありません)。 これは、 python 、 matlab 、 C ++での実装を支援するためのものです 。