正規表現のテストとデバッグには、RegexBuddyプログラム(http://www.regexbuddy.com)が理想的です。 次の例をデバッグするには、ページのHTMLを[テスト]タブにコピーするか、自分でいくつかのタグを挿入する必要があります。
タスクは、HTML内のすべてのIMGタグを検索し、タグからSRCおよびALT属性の値を抽出することです。
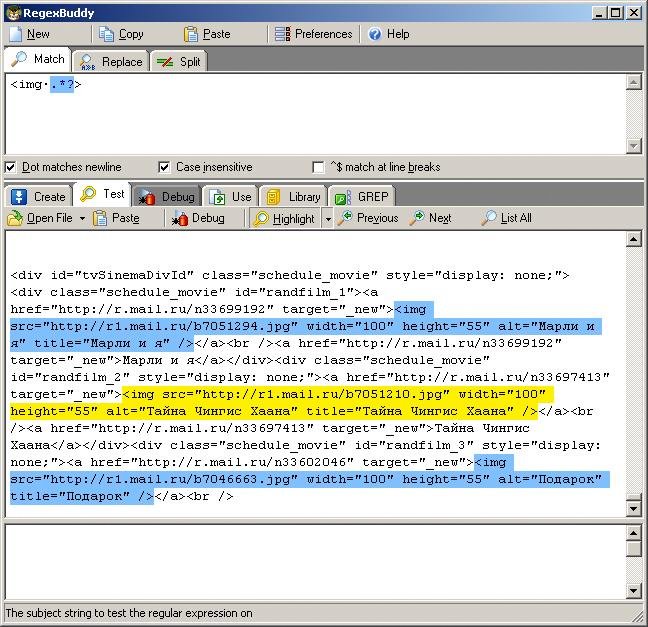
すべてのHTMLタグを見つけるタスクの最初の部分は、次の正規表現によって非常に簡単に解決されます。
<img .*?>
「ドットが改行と一致する」と「大文字と小文字を区別しない」を忘れずに確認してください
表現
.*?
必要なものではありません。 IMGタグ内には多くの属性があり、任意の順序で、属性値を単一引用符または二重引用符で囲むことも、引用符で囲まないこともできます。
最初にSRC属性をキャッチしてみましょう
\s+src\s*=\s*
この式は、前の空白文字と、等号の前後のオプションの空白文字をキャッチします。
式では、属性の値は考慮されません。属性の値は、単一引用符または二重引用符で囲むことができます。
そしてここで、BackreferencesとNamed Capturing Groupが助けになります。
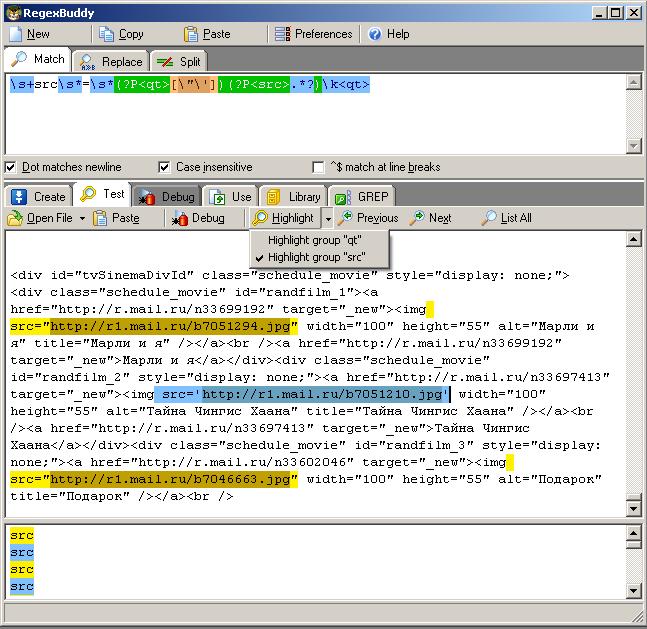
\s+src\s*=\s*(?P<qt1>[\"\'])(?P<src>.*?)\k<qt1>
したがって、式
(?P<qt1>[\"\'])
は、名前付きグループ" qt1 "に文字を含む"または'を作成します。
次に、名前付きグループsrcがあります。このグループでは、すべての文字が閉じ引用符まで遅延キャプチャされます。
後方参照
\k<qt1>
は、終了引用符が先頭で使用され、名前qt1でキャプチャされた引用符と一致することを保証します。
図で、RegexBuddyデバッガーがsrcという名前のグループのシンボルを暗い色で強調表示していることに注目してください。
同様に、altのレギュラーを構築できます。
属性alt、src、およびその他すべて
(.*?)
組み合わせます。
結果の規則性は少し複雑に見えるので、最初に説明します。
式
(?:)
()
に似ていますが、最初の角かっこ
(?:)
内の値は結果に取り込まれません。
通常のスケジュールは次のようになります。
<img(?: (?: src)|(?: alt)|(?: ) )*/?>
つまり imgフィールドは、「src属性」または「alt属性」または残りの部分を満たすことができ、これらすべてがグループに結合され、複数回繰り返すことができます。
IMGタグは、オプションのマークで終了します/
取得するものは次のとおりです。
<img(?:(?:\s+src\s*=\s*(?P<qt1>[\"\'])(?P<src>.*?)\k<qt1>)|(?:\s+alt\s*=\s*(?P<qt2>[\"\'])(?P<alt>.*?)\k<qt2>)|(?:.*?))*/?>

少し残った。 引用符が指定されていない場合の対処方法
この場合、式
\s+src\s*=\s*(?P<qt>[\"\'])(?P<src>.*?)\k<qt>
2つのオプションに分割
\s+src\s*=\s*( | )
したがって、srcがsrc属性の値である拡張オプションは、引用符の有無にかかわらず理解されます。
<img(?:(?:\s+src\s*=\s*(?:(?:(?P<qt1>[\"\'])(?P<src>.*?)\k<qt1>)|(?:(?P<src>\S+))))|(?:\s+alt\s*=\s*(?P<qt2>[\"\'])(?P<alt>.*?)\k<qt2>)|(?:.*?))*/?>
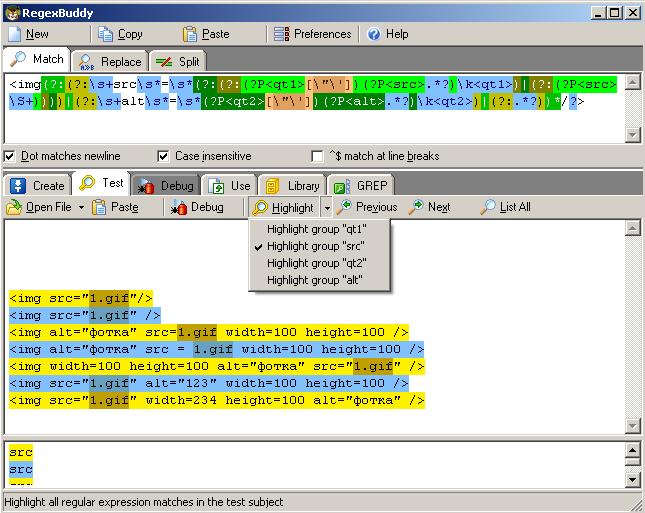
特に腐食性が高いので、altも引用なしで理解できるように、規則性を拡張しましょう。 (この場合、当然、値にスペースを含めることはできません)
UPD:このレギュラーは普遍的であると主張していません。 コメントアウトされたブロック、javascriptの断片、PREのようなブログ、実際には画像が表示されないブログなどの内部で誤検知の可能性があります。
ページ全体を解析する場合は、ページからスクリプトとコメントを削除することをお勧めします。PREブロック(別の通常のブロック)ですが、フォームの構造に関する問題は解決しません。
onmouseover = "document.write( '<img src = ...')"
UPD2:記事が出版前よりも少なくなった後のカルマ...動機付け!
UPD3:トピックに最も適したブログに移動しました。誰もオブジェクトを望んでいません:)