タスクの発生
約6か月前にキエフでBlogcampCEEが開催される予定でした。イベントに参加したい人は誰でも登録してプロフィールを記入する必要がありました。 当時、私は、インターネットプロジェクトのローカル市場、およびウクライナのIT市場とインターネット市場で誰が何をしているのかについてはほとんど知りませんでした。 このイベントの参加者の公開プロファイルにより、市場参加者(パーティ)の特定の写真を作成することができます。 同じページにある場合は、このような情報を使用すると便利です。 このすべてのデータを手動で収集するには、ページ間を移動してコピーアンドペーストするのに多くの時間を費やす必要があり、時間の経過に伴う更新もペンである必要があります。
道を探す
プログラミングスキルがあるため、何かを思いつくことができます。 そして、ご存知の通り、怠は進歩のエンジンです。 つい最近、同僚がAlexの htmlページからサイト評価を受け取る問題を解決しました。 そして、彼は生成されたスタイルを持つ偽のスパンの後ろに隠れていましたが、この値を直接伸ばすことはできませんでした。 そこで、私たちはWebHarvestに精通しました。 そして、彼らはこの問題を完全に解決し、SEOスペシャリスト向けのツールを作成するときに発生する同様の問題を解決しました。 結局、彼らは多くのデータ、ページランク、キーワードの強さ、競合他社の分析などを必要とします。 など また、情報の収集に関連するタスクの80%については、APIは存在しません。ページを実行してこの情報を収集するだけです。
したがって、WebHarvestライブラリ、Javaプログラミング言語(バックグラウンド)、 Antビルドツール、およびXMLをHTMLに変換するためのXSLTプロセッサーを使用して、BlogcampCEE Webサイト(必要な例)から読み取り可能な形式で必要な情報を取得した経験を共有したいと思います。
最初のアプローチ
その時に、サイトで発生するすべてのオープンイベントが追跡されるblogcampcee.com/ru/group/trackerページを見つけました。 その中には、Usernodeタイプのイベントがあります。これは、新しいユーザーの登録を意味し、ユーザープロファイルへのリンクが含まれています。
後で、ユーザーのみが表示されるblogcampcee.com/en/userlistページを見つけました。タスクのエントリポイントとして使用する方が論理的です。 しかし、すでに遅かった、すべてがすでに行われました。 彼女はあまり役に立たなかったであろうが、興味のない出来事の欠如と追加の型チェックのために仕事を加速した。 クリックから確実に保存されません。
タスクは、可能なすべてのページをスクロールし、ユーザーのページへのすべてのリンクを取得してから、各ユーザーを調べて必要な情報を収集することでした。
開発環境ではなく、WebharvestからGUIで構成ファイルを作成する必要がありますが、何もしないよりはましです。 デバッグも簡単ではありません。 ただし、少なくとも変数の状態は、実行中の任意の時点で表示できます。 そして、これはたくさんあります。
WebHarvest GUI
関数はfunctions.xmlファイルに転送され、メインの構成ファイルで使用されます。 リーフレットを歩き、ユーザーのページへのリンクを引き裂くのは別の機能です(WebHarvestの例からのいくつかの変更を取り入れています)。
メインのblogcamp.xml構成ファイルには、ユーザーページをナビゲートし、個人ページやプロジェクトサイトへのリンクなど、いくつかのフィールドを引き出すためのロジックが含まれており、これは私にとって最も興味深いものでした。 そして、カスタムxml形式( users-samples.xml )のこれらすべての情報は、ファイルに保存されます。
近代化
XMLファイルは読みにくいため、 users-style.xslは、読みやすく便利な外観にするために作成されています。
そして、XSLTプロセッサの出力でこのようなページを取得します。
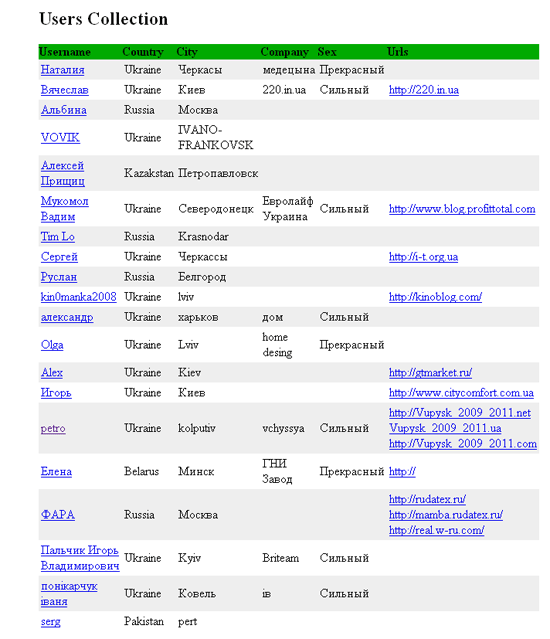
希望するユーザーリストの表示形式。
ミニプロジェクトの構造
WebHarvestは、必要な構成ファイルを供給して目的の結果を取得することにより、プロジェクトのライブラリとして便利に使用できる純粋なプログラマーツールです。 したがって、ホーンビームとXSL変換をAntの助けを借りて単一のプロセスに接続します。これは、あたかもそれがさらに複雑な製品に発展するかのように、または将来この全体がどのように呼ばれ、どこで開発されたかを思い出す必要がないようになります。 したがって、 build.xmlとそのような構造が判明しました。

今、将来、何が起こって何が起こっているのかを覚えて、これらの手順を繰り返す必要がある場合(そして、これはめったになく、多くの時間が経過した後、本当にそれが何であるかを完全に忘れる時間がある場合)、再開、繰り返し、編集し、など など
問題は解決しました。 必要な情報は、私にとって便利な形式で1ページにあります。 ボタンをクリックするだけで、プロセス全体が簡単に繰り返されます。これは、ユーザー数が増加し、時間が経つにつれてシートを更新する必要があるため、非常に重要です。
短所
最も重要なのは、シデ加工プロセスでのマルチスレッド化の欠如です。 チームツールはこの方法でのみ機能します。 これは私のタスクにとって重要ではありませんでした。 プログラム的に、あなたはやりたいことを自由に行うことができます。 そして、マルチスレッド化、並列化を整理し、N台のコンピューターのクラスターで分散モードで作業するには-してください。 すべてがあなたの手にあります。
ソリューション自体の完全に成功した構造ではありません。 すべてのユーザーリンクを決定するためのパッセージがすぐに作成され、その後、それらに対する処理が既に行われている場合 ユーザーのリンクを受信したらすぐに処理し、結果をファイルに保存することをお勧めします。 その後、接続が切断された場合など、最初からホーンビームを開始する必要はありませんが、すべてが横たわっている場所から続行できます。
結果のHTMLにはシリアル番号がありません。後で気づきましたが、XSLTを思い出すのが再びであるため、終了するのが面倒でした。
すべての構成ファイルにいくつかのコメント。 申し訳ありませんが、これは私を常に悩ませる惨劇です。 通常、彼らはプロジェクトの6ヶ月の仕事を祝った後に書かれ始め、あなたはメモリリソースが枯渇し、プロジェクトの添えものが止まるとは思わないことを理解しています:)
そして、さらに多くのものを見つけることができます。
素材
人生のすべてをすぐに試すことができない記事を読むとき、私はそれが好きではありません。 したがって、WebHarvestを含む完全なプロジェクトでアーカイブを投稿します 。 便利な作業のために、システムのどこからでもコマンドラインからAntを実行する必要があります。 重要! blogcampサイトを拷問しないでください。 イベントは通過しましたが、それでも、ホスティングとトラフィックが必ずしも無縁ではないためです。
XPathをあまり使用しない場合、これらすべてはすぐに忘れられます。 これらの技術の機能を更新(学習)するのに役立ったいくつかのリソースを以下に示します。
XPath仕様
XPathの記述例
おわりに
主な目標は、WebHarvestツールを使用する可能性を、達成されたプロジェクトのグラバーとして示すことです。
JavascriptとXQueryの使用、Cookieの保存、基本認証、ユーザーエージェントのなりすまし、カスタムリクエストヘッダーなど、タルサには十分な機能と工夫があります。 はい。作成者が後で父親を認識しないという認識を超えて、APIの一部を書き換えたりカスタマイズしたりできます。