self
、CSVでの作業、例外の処理について話しましょう。
コンピュータープログラムの説明と議論では、しばしば比fig的な人間の比metaを使用します。 たとえば、クラスにいる、またはメソッド呼び出しから戻ると言います。 たとえば、
object.respond_to?("x")
ように、2番目の人に言うのが理にかなっている場合があります。 そして、プログラムが解釈される間、コンテキストは何度も変わります。
どこでもいくつかのオブジェクトは同じことを意味します。たとえば、
def
や
class
などの数字やキーワードです。 ただし、ほとんどの要素の意味はコンテキストに依存します。
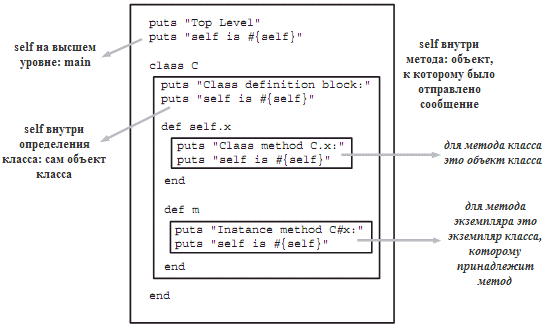
自己および現在のオブジェクト
Rubyの基礎の1つは、
self
キーワードを通じてアクセス可能な現在のオブジェクトです。 プログラムの作業の各時点で、
self
は1つだけであり、いくつかのルールを使用してこのオブジェクトを認識できます。 まず、コンテキストを知る必要があります。コンテキストの種類はほとんどありません。ここでは、トップレベル、クラス定義ブロック、モジュール定義ブロック、メソッド定義ブロックです。
最高レベルは、クラスおよびモジュールの外部で記述されたコードを指します。 たとえば、新しい
.rb
ファイルを開いて
x=1
のみを書き込む場合、最高レベルの
ローカル変数を作成します。 書いたら
def m
end
次に、最高レベルのメソッドを取得します。 最高レベルでは、Rubyは起動時の
self
を提供し、それを識別しようとすると
main
を返します。
main
は、自身を参照するときにデフォルトの
self
オブジェクトを使用する特別な用語です。
クラスまたはモジュールの定義では、
self
はクラスオブジェクトそのものです。デモは次のとおりです。
インスタンスメソッド定義内のclass C
puts "Started class C:"
puts self # C
module M
puts "Module C::M:"
puts self # C::M
end
puts "Back C:"
puts self # C
end
self
は扱いにくいため、ここにあります。 インタープリターは
def/end
ブロックを読み取ると、すぐにメソッドを定義します。 ただし、メソッド内のコードは、オブジェクトによって呼び出されたときにのみ実行されます。これは、このメソッドの
self
となります。
self
行動の簡単な要約を次に示します。
.txtのDb
多くのアプリケーションでは、データを保存および操作する必要があります。 このためにファイルが開かれ、必要な変更が行われ、結果が画面に表示されるか、ファイルに保存されます。 ただし、状況によっては、データベースが必要です。 データベースは、体系的な方法でコンピューター上のデータを整理および保存するためのシステムです。 データベースは、プログラム自体によって操作されるテキストファイルのように単純なものでも、たとえば、専用サーバーに分散されたテラバイトのデータで構成される複雑なものでもかまいません。 ちなみに、この場合もRubyを使用できますが、最も単純なデータベースのオプションを検討します。
データベースは、CSV(コンマ区切り値)の場合のように、カンマで区切られた各データ項目の属性を保存できる単純なテキストファイルにすることができます。 たとえば、CSVデータを書き込む
db.txt
ファイルを作成してみましょう。
Fred Bloggs,Manager,Male,45
Laura Smith,Cook,Female,23
Debbie Watts,Professor,Female,38
各行は個別の人物を表し、各属性はコンマで区切られています。
Rubyには、CSVデータを含むテキストファイルを操作しやすいシンプルなデータベースとして使用できる標準のcvsライブラリが含まれています。 ライブラリにはCSVクラスが含まれており、作業に役立ちます。 CSVクラスの
read
メソッドを使用してCVSファイルから配列にデータを読み込み、配列からスレッドを読み取り、変更します。
require 'csv'
a= CSV . read ( 'db.txt' )
puts a. inspect
puts a [ 0 ][ 0 ] # Fred Bloggs
puts a [ 1 ][ 0 ] # Laura Smith
puts a [ 2 ][ 0 ] # Debbie Watts
a [ 1 ][ 1 ] = "Marine"
p ( a [ 1 ]) # ["Laura Smith", "Marine", "Female", "23"]
必要なデータが得られたので、CSVを保存し直す必要があります。csvモジュールがすべてを行います。
CSV . open ( 'bd.txt' , 'w' ) do |csv|
a. each do |a|
csv << a
end
end
例外
どのプログラムでも、物事が正しい方向に進まない場合があります:人々が間違ったデータを入力したり、数えているファイルが存在しない(またはそれらへのアクセス権がない)、メモリ不足などです。そのような状況から抜け出す方法はいくつかあります。 プログラムを終了する最も簡単な方法は、何か問題が発生した場合です。
それほど根本的ではない解決策は、各メソッドが処理の成功を示すステータスデータのようなものを返す必要があることです。その後、メソッドから受信したデータをテストする必要があります。 ただし、各結果をテストすると、コードが読めなくなります。
別の代替アプローチは、例外を使用することです。 何か問題が発生した場合(つまり、例外条件が表示された場合)、例外がスローされます。 高レベルでは、プログラムはそのようなシグナルの出現を監視し、特定の方法でそれに応答するコード(例外ハンドラー)を持ちます。
また、1つのプログラムには多くの例外ハンドラーがあり、それぞれが特定のタイプのエラーを処理します。 例外は、必要なものが満たされるまですべてのハンドラーを通過し、存在しない場合はプログラムが終了します。 この動作は、C ++、Java、およびRubyに存在します。
テキストエディタを想像してください。 ユーザーは[名前を付けて
SaveAs
]ダイアログに名前を入力し、[
]をクリックする必要があります。 ユーザー自身が入力するデータを決定するため、このファイルを書き込む権利があるかどうか、ディスクに空き領域があるかどうかはわかりません。 例外を使用します。
text = editor ()
location = ask_user ()
begin
File . open ( location, w ) do |file|
save_work ( file, text )
end
rescue
puts " . : #{$!}"
end
何か問題が発生しても、プログラムはシャットダウンせず、データは失われず、2度目のチャンスがあります。
begin
と
rescue
間
begin
すべて保護されています。 例外が発生した場合、制御は
rescue
と
end
間のブロックに渡されます。 グローバル変数
$!
エラーメッセージを送信し、画面に表示されます。 特定の種類の例外のみを制御するために、
rescue
から記述します。 たとえば、ファイルの書き込み時にエラーのみを処理するには、
rescue IOError
という式を使用し
rescue IOError
。 1つのハンドラーで複数のタイプの例外をキャッチする場合、それらをコンマで区切ってリストするか、(より便利な)各タイプのハンドラーを作成します。
rescue IOError
puts -- $!.
rescue SystemCallError
puts -- $!.
end
エピローグ
はい、純粋なRubyを忘れないでください。可能な限り必要なことを書いていきます。 たぶん作品はぎくしゃくしているかもしれませんが、私は現時点であなたが興味を持っているものを書いています-あなたもそれが好きであることを望みます。 いつものように-コメントを待っています!