eBPFおよびbccツールでVFSを見る方法
カーネルが
sysfs
ファイルでどのように動作するかを理解する最も簡単な方法は、実際にこれを調べることです。ARM64を観察する最も簡単な方法は、eBPFを使用することです。 eBPF(Berkeley Packet Filterの略)は、特権ユーザーがコマンドラインから
query
できるカーネルで実行されている仮想マシンで構成されています 。 カーネルソースは、カーネルに何ができるかを読者に伝えます。 ビジーなシステムでeBPFツールを実行すると、カーネルが実際に行うことを示します。

幸いなことに、一般的なLinuxディストリビューションからパッケージとして入手でき、 Bernard Greggによって詳細に文書化されているbccツールを使用すると、eBPFを使い始めるのは簡単です。
bcc
ツールは、小さなCコードを挿入したPythonスクリプトです。つまり、両方の言語に精通している人なら誰でも簡単に変更できます。
bcc/tools
には80個のPythonスクリプトがあり
bcc/tools
。これは、開発者またはシステム管理者が問題の解決に適したものを選択できる可能性が高いことを意味します。
実行中のシステムでVFSが何をするかについての表面的なアイデアを得るには、
vfscount
または
vfsstat
試してください。 これは、例えば、
vfs_open()
と「彼の友人」への何十もの呼び出しが文字通り毎秒発生することを示します。
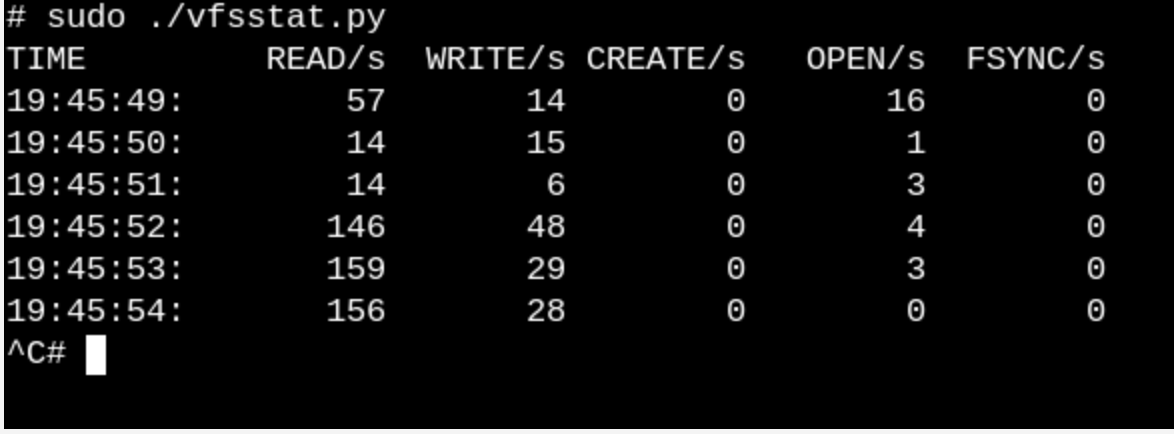
vfsstat.py
は、VFS関数呼び出しを単純にカウントするCコード挿入を含むPythonスクリプトです。
もっと簡単な例を挙げて、USBフラッシュドライブをコンピューターに挿入し、システムがそれを検出するとどうなるかを確認します。
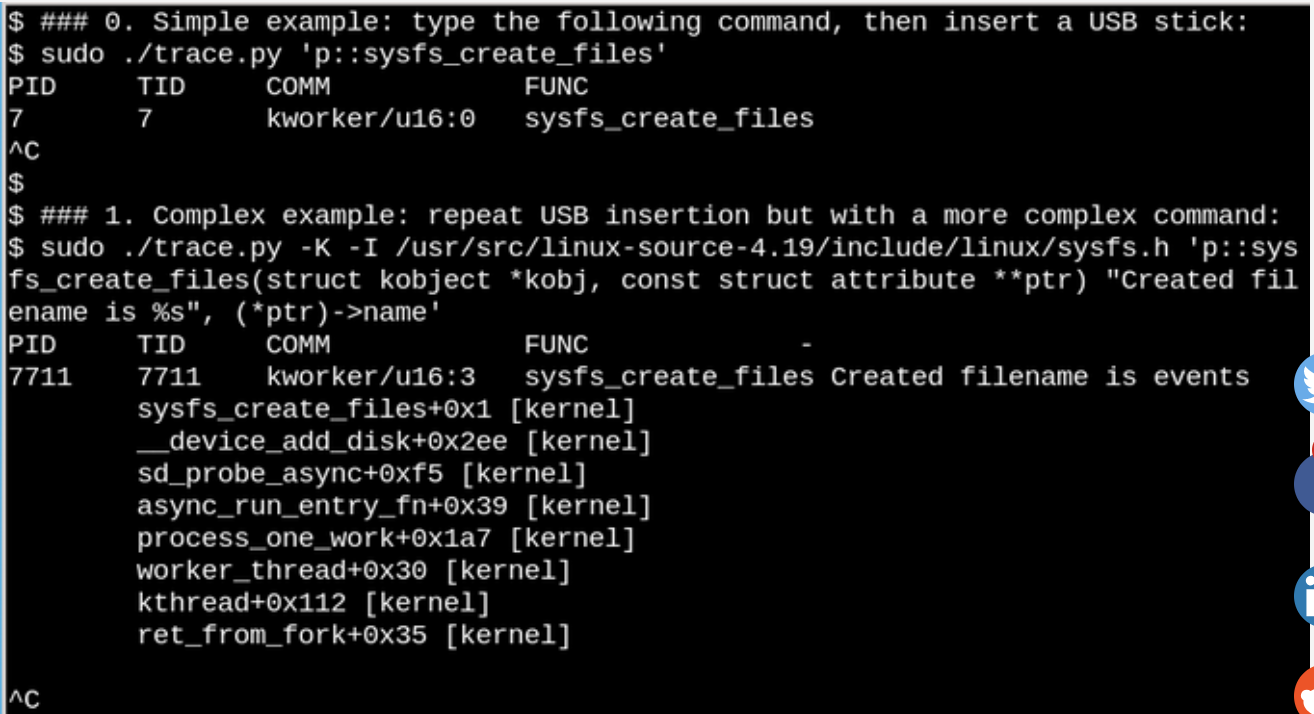
eBPFを使用すると、USBフラッシュドライブが挿入されたときに/sys
何が起こるかを確認できます。 簡単で複雑な例を次に示します。
上記の例では、
sysfs_create_files()
コマンドが
sysfs_create_files()
されると、
bcc
ツールtrace.pyがメッセージを表示します。
sysfs_create_files()
は、挿入されているフラッシュドライブへの応答として
kworker
ストリームを使用して起動されましたが、どのファイルが作成されましたか? 2番目の例は、eBPFの全機能を示しています。 ここで、
trace.py
は、カーネルバックトレース(-Kオプション)と
sysfs_create_files()
たファイルの名前を表示します。 単一ステートメントの挿入は、LLVM ジャストインタイムコンパイラーを実行するPythonスクリプトによって提供される簡単に認識可能なフォーマット文字列を含むCコードです。 彼は、カーネル内の仮想マシンでこの行をコンパイルして実行します。
sysfs_create_files ()
関数の完全な署名を2番目のコマンドで再現して、フォーマット文字列がパラメーターの1つを参照できるようにする必要があります。 このCコードフラグメントのエラーは、認識可能なCコンパイラエラーになります。 たとえば、-lオプションを省略すると、「BPFテキストのコンパイルに失敗しました」と表示されます。CおよびPythonに精通している開発者は、
bcc
ツールを簡単に展開および変更できます。
USBドライブが挿入されると、カーネル
kworker
は、PID 7711が
sysfs
«events»
ファイルを作成した
kworker
ストリームであることを示します。 したがって、
sysfs_remove_files()
を
sysfs_remove_files()
た呼び出しは、ドライブを削除すると
events
ファイルが削除されたことを示します。これは、参照カウントの一般的な概念に沿っています。 同時に、USBドライブの挿入中に
sysfs_create_link ()
を表示すると、少なくとも48のシンボリックリンクが作成されていることがわかります。
では、イベントファイルの意味は何ですか? cscopeを使用して__device_add_disk()を検索すると、 disk_add_events()が
disk_add_events ()
、
"media_change"
または
"eject_request"
いずれかをイベントファイルに書き込むことができます。 ここで、カーネルブロックレイヤーは、ユーザースペースに「ディスク」の外観と抽出を通知します。 この研究方法は、ソースからのみすべてがどのように機能するかを理解しようとする場合と比較して、USBドライブを挿入する例によってどれほど有益であるかに注意してください。
読み取り専用ルートファイルシステムにより、組み込みデバイスが可能
もちろん、サーバーやコンピューターの電源を切ってプラグをコンセントから抜くことはありません。 しかし、なぜですか? 物理ストレージデバイスにマウントされたファイルシステムには保留中のレコードがあり、そのステータスを記録するデータ構造はストレージ内のレコードと同期されない可能性があるためです。 これが発生すると、システム所有者は、次のブートが
fsck filesystem-recovery
ユーティリティを実行するのを待たなければならず、最悪の場合、データを失います。
ただし、ルーター、サーモスタット、自動車だけでなく、多くのIoTデバイスがLinuxを実行していることは誰もが知っています。 これらのデバイスの多くには実質的にユーザーインターフェイスがなく、「クリーン」にそれらをオフにする方法はありません。 Linuxの制御デバイスの電源が絶えず上下するときに、放電したバッテリーで車を始動することを想像してください。 エンジンが最終的に動作を開始したときに、システムが長い
fsck
なしでブートするのはどうですか? そして答えは簡単です。 組み込みデバイスは、読み取り専用ルートファイルシステム(
ro-rootfs
(読み取り専用ルートファイルシステム)と略記)に依存しています。
ro-rootfs
は、本物ほど明白ではない多くの利点があります。 1つの利点は、Linuxプロセスが書き込みできない場合、マルウェアが
/usr
または
/lib
書き込むことができないことです。 もう1つは、サポートスタッフがローカルシステムと名目上同一のローカルシステムを使用するため、リモートデバイスのフィールドサポートには、ほとんど変更できないファイルシステムが重要であることです。 おそらく最も重要な(しかし最も陰湿な)利点は、ro-rootfsにより、システム設計の段階であっても、変更するシステムオブジェクトを決定することを開発者に強制することです。 プログラミング言語のconst変数ではよくあることですが、ro-rootfsの操作は不快で痛みを伴う場合がありますが、それらの利点は簡単に追加のオーバーヘッドを回収します。
rootfs
専用の
rootfs
を作成するには
rootfs
組み込み開発者にとって余分な労力が必要です。そこでVFSが登場します。 Linuxでは、
/var
内のファイルが書き込み可能であることが必要です。さらに、組み込みシステムを実行する多くの一般的なアプリケーションは、
$HOME
構成
dot-files
を作成しようとします。 ホームディレクトリの構成ファイルの解決策の1つは、通常、
rootfs
予備的な生成とアセンブリです。
/var
、可能なアプローチの1つは、書き込み可能な別のセクションにマウントすることです。一方、
/
マウント自体は読み取り専用です。 別の一般的な代替手段は、バインドまたはオーバーレイマウントの使用です。
リンク可能で重複するマウント、コンテナによる使用
man mount
コマンドの実行は、
man mount
バインドとオーバーラップについて学ぶ最良の方法です。これにより、開発者とシステム管理者は、ある方法でファイルシステムを作成し、それを別の方法でアプリケーションに提供できます。 組み込みシステムの場合、これは読み取り専用フラッシュドライブの
/var
にファイルを保存できることを意味しますが、起動時に
tmpfs
から
/var
へのパスをオーバーレイまたはリンクすると、アプリケーションはそこにメモを書き込むことができます(スクローリング)。 次回有効にすると、
/var
への変更は失われます。 オーバーレイマウントは、
tmpfs
とその下にあるファイルシステムの結合を作成し、
ro-tootf
既存のファイルを修正できるとされていますが、リンクされたマウントは、
ro-rootfs
パスで書き込み可能な新しい空の
tmpfs
フォルダーを表示できます。
overlayfs
は
proper
種類のファイルシステムですが、バインディングマウントはVFS名前空間に実装されます 。
重ねてリンクされたマウントの説明に基づいて、 Linuxコンテナがそれらを積極的に使用していることに誰も驚かない。 systemd-nspawnを使用して、
bcc
mountsnoop
ツールを使用してコンテナを起動するとどうなるかを見てみましょう。

system-nspawn
呼び出すと、
mountsnoop.py
中に
mountsnoop.py
開始されます。
何が起こったのか見てみましょう:
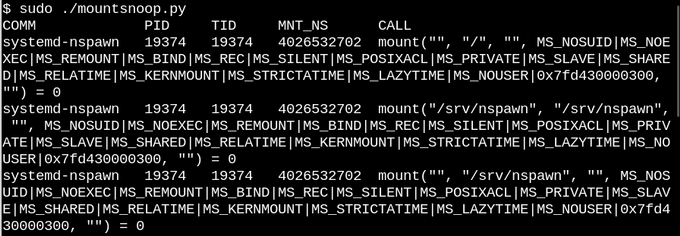
コンテナーが「ロード」されている間に
mountsnoop
を実行すると、コンテナーランタイムが接続されているマウントに大きく依存していることが
mountsnoop
ます(長い出力の先頭のみが表示されます)。
ここで、
systemd-nspawn
は
sysfs
ホストの
procfs
と
sysfs
選択されたファイルを、その
rootfs
へのパスとしてコンテナに提供し
rootfs
。 バインディングマウントを設定する
MS_BIND
フラグに加えて、マウントされたシステムの他のいくつかのフラグは、ホスト名前空間とコンテナの変更の関係を決定します。 たとえば、バインディングマウントは、
/proc
および
/sys
変更をコンテナにスキップするか、呼び出しに応じてそれらを非表示にすることができます。
おわりに
Linuxの内部構造を理解することは、カーネル自体に大量のコードが含まれ、
glibc
ようなCライブラリのLinuxユーザー空間アプリケーションとシステムコールインターフェイスを残すため、不可能なタスクのように思えるかもしれません。 進歩させる1つの方法は、ユーザー空間に面するシステムコールとヘッダー、およびカーネルのメイン内部インターフェイス(
file_operations
テーブルなど)を理解することに重点を置いて、1つのカーネルサブシステムのソースコードを読み取ることです。 ファイル操作は「すべてがファイルである」という原則を提供するため、それらの管理は特に便利です。 最上位ディレクトリ
fs/
のCソースファイルは、仮想ファイルシステムの実装を表します。仮想ファイルシステムは、一般的なファイルシステムとストレージデバイスの広く比較的単純な互換性を提供するシェルレイヤーです。 Linuxネームスペースを介したバインディングおよびオーバーレイによるマウントは、読み取り専用のコンテナーとルートファイルシステムを作成できるVFSの魔法です。 ソースコード学習、eBPFコアツールおよびその
bcc
インターフェイスとの組み合わせ
カーネルの研究をこれまで以上に簡単にします。
友人、この記事を書くのはあなたにとって役に立ちましたか? 何かコメントやコメントがありますか? また、Linux管理者コースに興味のある方は、4月18日に開催される一般公開日にご招待します。
最初の部分。