記事は、 Jiga Akhaltsev 、 Jigaを代表して公開されています。
今日のTinkoff.ruは単なる銀行ではなく、IT企業です。 銀行サービスだけでなく、それらを取り巻くエコシステムを構築します。
Tinkoff.ruでは、さまざまなサービスとパートナーシップを結び、顧客サービスの品質を向上させ、改善を支援しています。 たとえば、これらのサービスの1つについて負荷テストとパフォーマンス分析を実施しました。これは、システムのボトルネックを見つけるのに役立ちました-OS構成に透過的な巨大ページが含まれています。
システムパフォーマンスの分析方法とその結果を知りたい場合は、catへようこそ。
問題の説明
現在、サービスアーキテクチャは次のとおりです。
- HTTP接続を処理するためのNginx Webサーバー
- PHPプロセス制御のPHP-FPM
- キャッシュ用のRedis
- データストレージ用のPostgreSQL
- ワンストップショッピングソリューション
次の高負荷時の販売で見つかった主な問題は、CPUの使用率が高いことでしたが、カーネルモードのプロセッサ時間(システム時間)は増加し、ユーザーモードの時間(ユーザー時間)よりも長くなりました。
- ユーザー時間-プロセッサーがユーザーのタスクに費やす時間。 これは、プロセッサを購入するときに支払う主なものです。
- システム時間-システムがページング、コンテキストの変更、スケジュールされたタスクの起動、およびその他のシステムタスクに費やす時間。
システムの主要な特性の決定
まず、生産性に近いリソースで負荷回路を収集し、通常の通常の負荷に対応する負荷プロファイルをコンパイルしました。
ガトリングバージョン3が砲撃ツールとして選択され、砲撃自体はgitlab-runnerを介してローカルネットワーク内で実行されました。 同じローカルネットワーク内のエージェントとターゲットの場所はネットワークコストの削減によるものであるため、システムが展開されているインフラストラクチャのパフォーマンスではなく、コード自体の実行の確認に重点を置いています。
システムの主要な特性を決定する場合、http構成で負荷が直線的に増加するシナリオが適しています。
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources() // .disableCaching // , "" . .disableFollowRedirect // /// MULTIPLIER JAVA_OPTS setUp( Scenario.inject( rampUsers(100 * MULTIPLIER) during (200 * MULTIPLIER seconds)) ).protocols(httpConfig) .maxDuration(1 hour)
この段階で、メインページを開いてすべてのリソースをダウンロードするスクリプトを実装しました

このテストの結果、最大性能は1500 rpsであり、負荷強度がさらに増加すると、softirq時間の増加に伴うシステムの劣化が発生しました。


Softirqは遅延割り込みメカニズムであり、kernel / softirq.sファイルに記述されています。 同時に、プロセッサへの命令のキューをたたき、ユーザーモードで有用な計算を行えないようにします。 割り込みハンドラーは、OSスレッドでのネットワークパケットの追加作業を遅らせることもできます(システム時間)。 ネットワークスタックの仕事と最適化について簡単には別の記事で見つけることができます。
主な問題の疑いは確認されませんでした。これは、ネットワークアクティビティが少なく、製品のシステム時間が非常に長いためです。
ユーザースクリプト
次のステップは、カスタムスクリプトを開発し、写真付きのページを開くだけではないことを追加することでした。 プロファイルには、静的なリソースを提供するWebサーバーではなく、サイトとデータベースのコードを最大限に含む、重い操作が含まれていました。
安定した負荷でのテストは最大値よりも低い強度で開始され、リダイレクト遷移が構成に追加されました。
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources() // .disableCaching // , "" . /// MULTIPLIER JAVA_OPTS setUp( MainScenario .inject(rampUsers(50 * MULTIPLIER) during (200 * MULTIPLIER seconds)), SideScenario .inject(rampUsers(100 * MULTIPLIER) during (200 * MULTIPLIER seconds)) ).protocols(httpConfig) .maxDuration(2 hours)
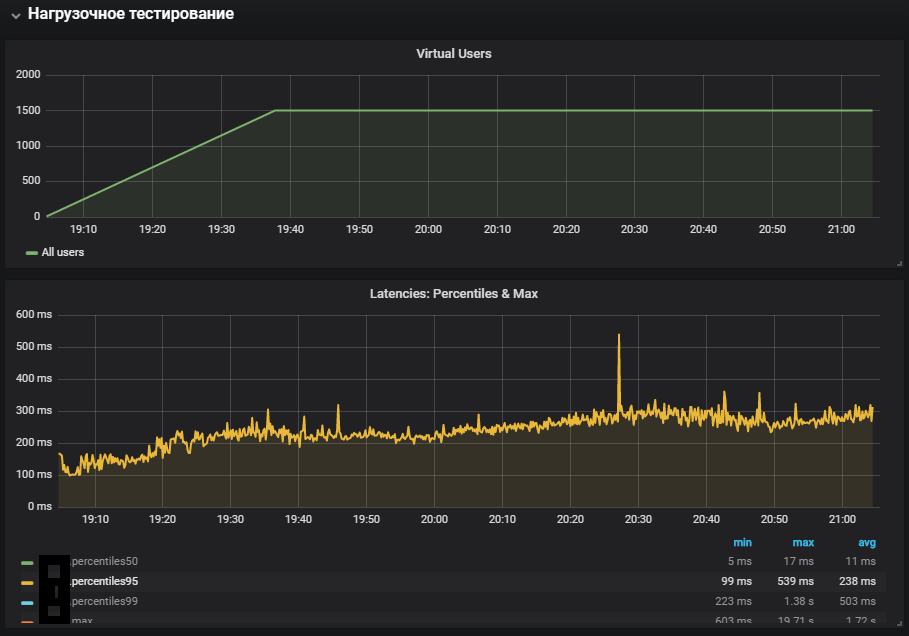

システムの最も完全な使用は、システム時間メトリックの増加と安定性テスト中の増加を示しました。 実稼働環境の問題が再現されました。
Redisとのネットワーキング
問題を分析するとき、システムのすべてのコンポーネントを監視して、それがどのように機能し、供給された負荷がシステムに与える影響を理解することが非常に重要です。
Redisモニタリングの出現により、システムの一般的なメトリックではなく、その特定のコンポーネントを見ることが可能になりました。 ストレステストのシナリオも変更されました。これは、追加の監視とともに、問題のローカライズへのアプローチに役立ちました。

監視では、RedisがCPU使用率と同様の状況を見ましたが、CPU時間の主な使用率がSET操作、つまり値を保存するためのRAMの割り当てにある間、システム時間はユーザー時間よりもかなり長くなります。

Redisとのネットワーク相互作用の影響を排除するために、仮説をテストし、RedisをtcpソケットではなくUNIXソケットに切り替えることが決定されました。 これは、php-fpmがデータベースに接続するフレームワークで行われました。 ファイル/yiisoft/yii/framework/caching/CRedisCache.phpで、host:portの行をハードコードredis.sockに置き換えました。 この記事でソケットのパフォーマンスについて詳しく読んでください 。
/** * Establishes a connection to the redis server. * It does nothing if the connection has already been established. * @throws CException if connecting fails */ protected function connect() { $this->_socket=@stream_socket_client( // $this->hostname.':'.$this->port, "unix:///var/run/redis/redis.sock", $errorNumber, $errorDescription, $this->timeout ? $this->timeout : ini_get("default_socket_timeout"), $this->options ); if ($this->_socket) { if($this->password!==null) $this->executeCommand('AUTH',array($this->password)); $this->executeCommand('SELECT',array($this->database)); } else { $this->_socket = null; throw new CException('Failed to connect to redis: '.$errorDescription,(int)$errorNumber); } }
残念ながら、これはあまり効果がありませんでした。 CPU使用率は少し安定しましたが、問題は解決しませんでした-CPU使用率のほとんどはカーネルモードコンピューティングでした。
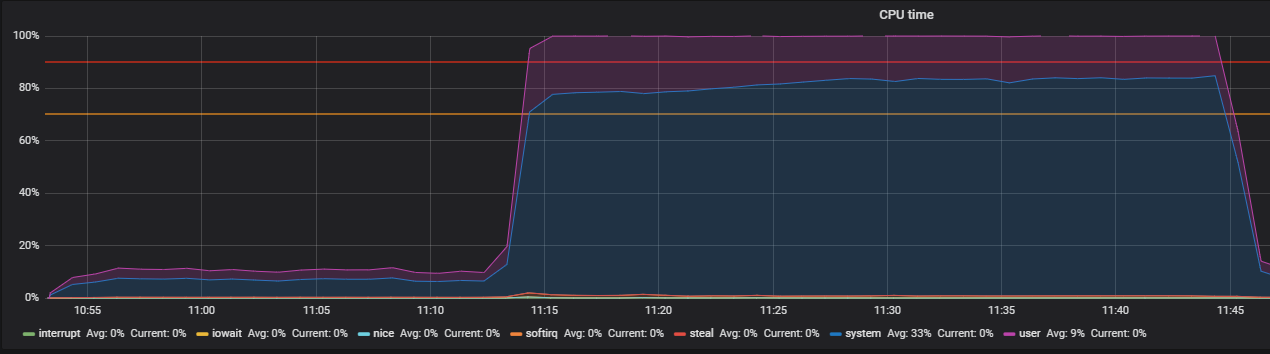
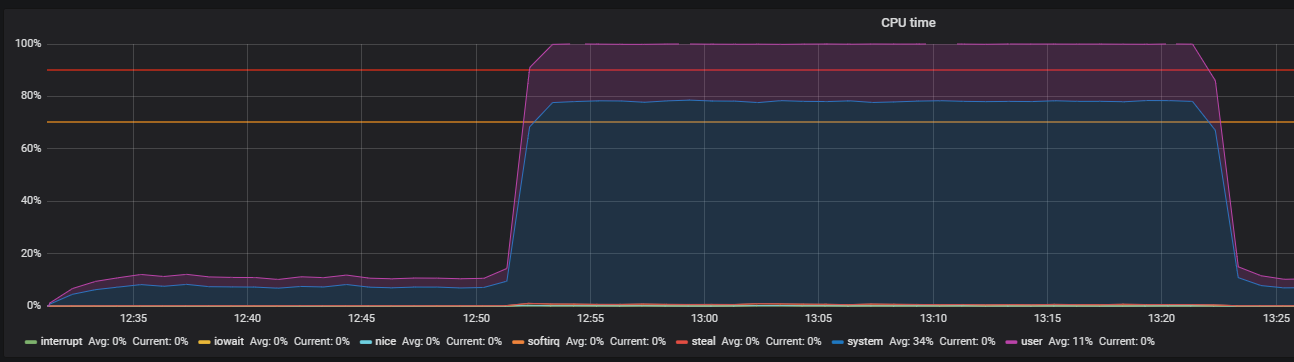
ストレスを使用してTHP問題を特定するベンチマーク
ストレスユーティリティは、問題の場所を特定するのに役立ちました-POSIXシステム用の単純なワークロードジェネレーターは、CPU、メモリ、IOなどの個々のシステムコンポーネントをロードできます。
テストはハードウェアとOSバージョンで行われます:
Ubuntu 18.04.1 LTS
12Intel®Xeon®CPU
このユーティリティは、次のコマンドを使用してインストールされます。
sudo apt-get install stress
負荷がかかった状態でCPUがどのように使用されるかを見て、300秒間の平方根を計算するワーカーを作成するテストを実行します。
-c, --cpu N spawn N workers spinning on sqrt() > stress --cpu 12 --timeout 300s stress: info: [39881] dispatching hogs: 12 cpu, 0 io, 0 vm, 0 hdd
このグラフは、ユーザーモードでの完全な使用率を示しています。つまり、システムサービスコールではなく、すべてのプロセッサコアがロードされ、有用な計算が実行されます。
次のステップは、ioを集中的に使用するときにリソースを使用することです。 sync()を実行する12人のワーカーを作成して、300秒間テストを実行します。 syncコマンドは、メモリにバッファリングされたデータをディスクに書き込みます。 カーネルは、頻繁に(通常は遅い)ディスクの読み取りおよび書き込み操作を回避するために、データをメモリに保存します。 sync()コマンドは、メモリに保存されているすべてのものがディスクに書き込まれるようにします。
-i, --io N spawn N workers spinning on sync() > stress --io 12 --timeout 300s stress: info: [39907] dispatching hogs: 0 cpu, 0 io, 0 vm, 12 hdd

プロセッサは主にカーネルモードで呼び出しを処理し、iowaitで少し処理していることがわかります。また、ディスクへの35k ops書き込みも確認できます。 この動作は、システム時間が長い問題に似ており、その原因を分析しています。 しかし、ここにはいくつかの違いがあります:これらはiowaitであり、iopsはそれぞれ生産的な回路よりも大きく、これは私たちの場合には合いません。
あなたの記憶をチェックする時です。 次のコマンドを使用して、300秒間メモリを割り当てて解放する20人のワーカーを起動します。
-m, --vm N spawn N workers spinning on malloc()/free() > stress -m 20 --timeout 300s stress: info: [39954] dispatching hogs: 0 cpu, 0 io, 20 vm, 0 hdd
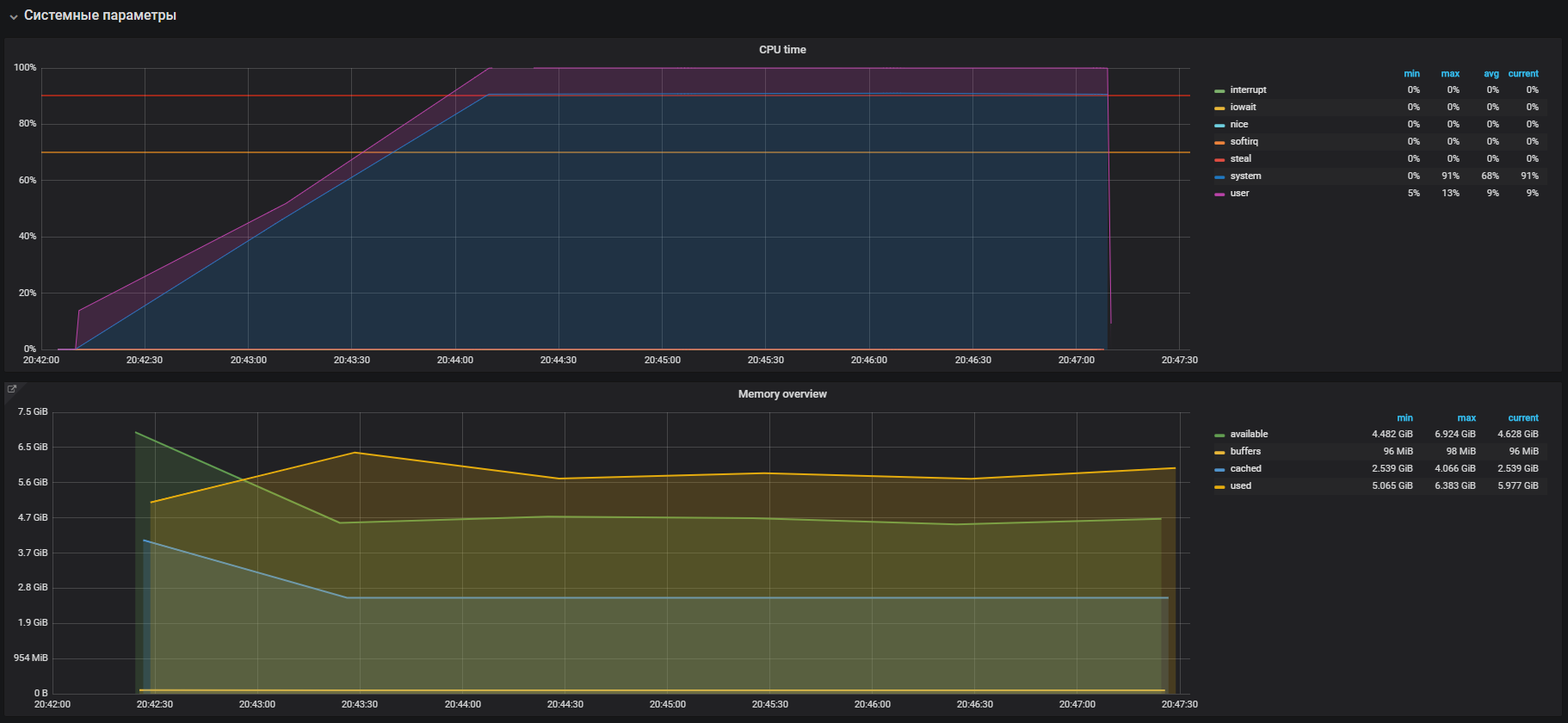
すぐに、システムモードでCPUの使用率が高くなり、ユーザーモードでCPUの使用率が少し高くなり、2 GBを超えるRAMが使用されることがすぐにわかります。
このケースは、負荷テストでメモリを大量に使用することで確認されるprodの問題と非常によく似ています。 したがって、メモリ操作で問題を探す必要があります。 メモリの割り当てと解放はそれぞれmalloc呼び出しとfree呼び出しを使用して行われ、これらは最終的にカーネルシステムコールによって処理されます。つまり、システム時間としてCPU使用率に表示されます。
ほとんどの最新のオペレーティングシステムでは、ページングを使用して仮想メモリが編成されます。このアプローチでは、メモリ領域全体が固定長のページに分割されます(たとえば、4096バイト(多くのプラットフォームのデフォルト))。たとえば、2 GBのメモリを割り当てる場合、メモリマネージャは動作する必要があります500,000ページ以上。 このアプローチでは、管理に大きなオーバーヘッドがあり、Huge PageとTransparent Huge Pagesテクノロジーがそれらを削減するために発明されました。たとえば、ページサイズを最大2MBまで増やすことができるため、メモリヒープ内のページ数が大幅に削減されます。 テクノロジー間の唯一の違いは、Huge Pageの場合、環境を明示的に設定し、プログラムの操作方法を教える必要があるのに対して、Transparent Huge Pagesはプログラムに対して「透過的に」機能することです。
THPと問題解決
トランスペアレントヒュージページに関する情報をグーグル検索すると、検索結果に「THPをオフにする方法」という質問のあるページが多数表示されます。
結局のところ、この「クールな」機能はRed Hat CorporationによってLinuxカーネルに導入されました。この機能の本質は、アプリケーションが実際のHuge Pageで動作するかのようにメモリを透過的に動作できることです。 ベンチマークによると、THPは抽象アプリケーションを10%高速化します。プレゼンテーションで詳細を確認できますが、実際にはすべてが異なります。 場合によっては、THPはシステムのCPU消費を不当に増加させます。 詳細については、Oracleの推奨事項を参照してください。
パラメータを確認します。 判明したように、THPはデフォルトでオンになっています。次のコマンドでオフにします。
echo never > /sys/kernel/mm/transparent_hugepage/enabled
THPをオフにする前と後に、負荷プロファイルでテストで確認します。
setUp( MainScenario.inject( rampUsers(150) during (200 seconds)), Peak.inject( nothingFor(20 minutes), rampUsers(5000) during (30 minutes)) ).protocols(httpConfig)

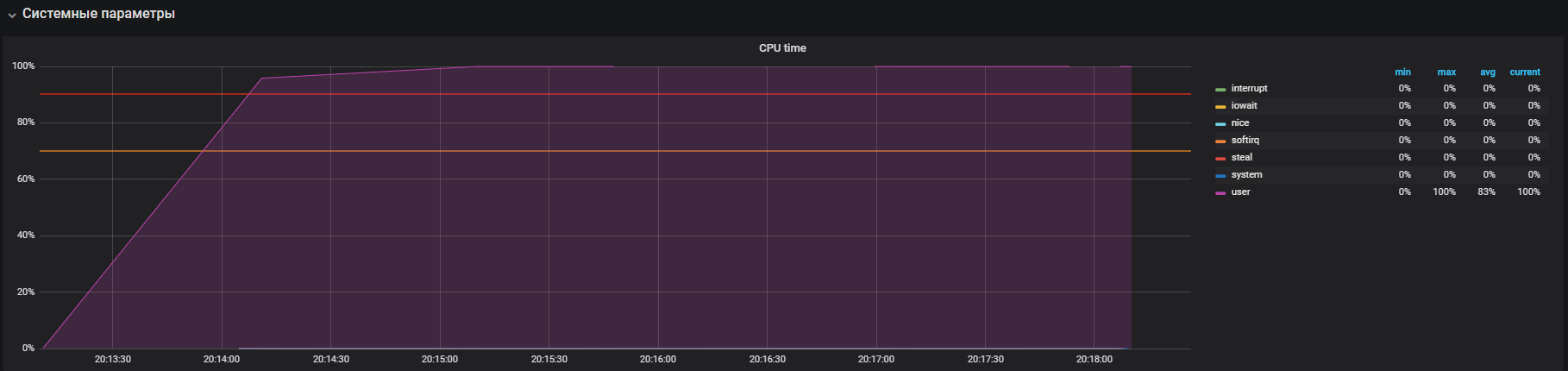
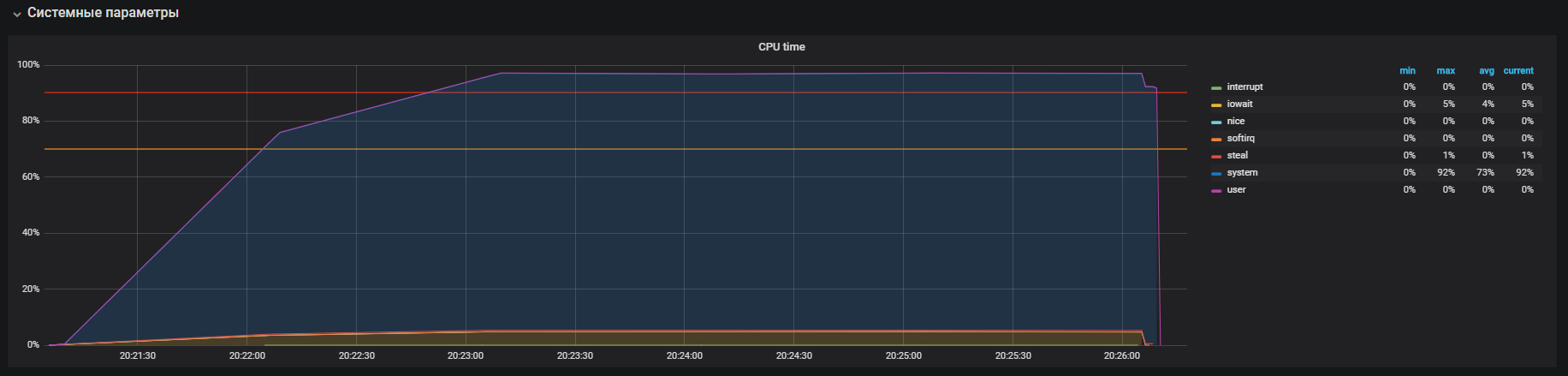
THPをオフにする前にこの写真を見ました

THPをオフにすると、リソース使用率がすでに低下していることがわかります。
主な問題はローカライズされました。 理由はOSでデフォルトで有効化されていました
透明な大きなページのメカニズム。 THPオプションを無効にした後、システムモードでのCPU使用率が少なくとも2倍減少し、ユーザーモード用のリソースが解放されました。 主な問題の分析中に、OSとRedisのネットワークスタックとの相互作用の「ボトルネック」も発見されました。これが、より深い研究の理由です。 しかし、これはまったく異なる話です。
おわりに
結論として、パフォーマンスの問題を正常に検索するためのヒントをいくつか紹介します。
- システムのパフォーマンスを調査する前に、そのアーキテクチャとコンポーネントの相互作用を注意深く理解してください。
- すべてのシステムコンポーネントの監視を構成し、標準のメトリックが十分でない場合は追跡し、さらに深くして拡張します。
- 使用済みシステムのマニュアルをお読みください。
- OSおよびシステムコンポーネントの構成ファイルのデフォルト設定を確認します。