ゾエはゾエではない
ちなみに、これはもう1つのJavaScriptの奇妙さの例ではありません。 本書の著者である翻訳者は、今日公開している翻訳版では、既存のほとんどすべてのプログラミング言語を使用したときに同じ問題がどのように現れるかを示すことができると述べています。 特に、Python、Go、さらにはシェルスクリプトについても説明しています。 これに対処する方法は?
背景
数年前、Unicodeの問題に最初に遭遇したのは、ユーザーのアドレス帳とソーシャルネットワークから連絡先リストをインポートするアプリケーションを(Objective-Cで)書いた後、重複を除外しました。 特定の状況では、一部の人がリストに2回載っていることが判明しました。 これは、プログラムによれば、名前が同じ文字列ではないという事実が原因で発生しました。
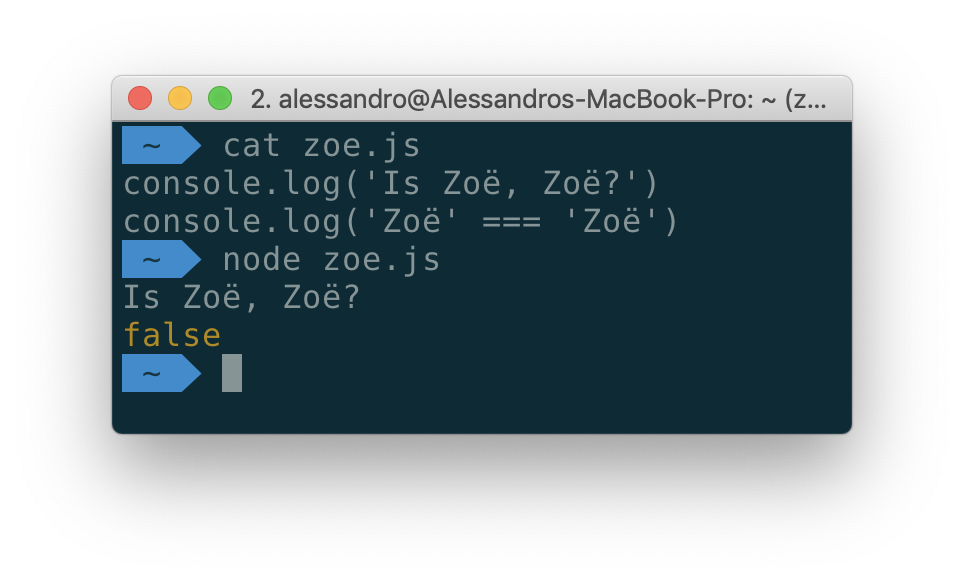
上記の例では、2つの行はシステムでの表示方法とまったく同じに見えますが、ディスクに保存されるバイトは異なります。 最初の名前
"Zoë"
、ë(ウムラウト付きe)文字は1つのUnicodeコードポイントを表します。 2番目のケースでは、いくつかの文字を使用して文字を表現するアプローチで、分解を扱っています。 アプリケーションでUnicode文字列を使用する場合、同じ文字を異なる方法で表現できるという事実を考慮する必要があります。
絵文字の由来:文字エンコーディングについての簡単な説明
コンピューターは、単なる数字であるバイトで動作します。 コンピューターでテキストを処理できるようにするために、人々は文字と数字の対応に同意し、文字の視覚的表現がどのように見えるべきかについて合意に達しました。
最初のそのような合意は、ASCII(情報交換のためのアメリカの標準コード)エンコーディングによって表されました。 このエンコードは7ビットを使用し、ラテンアルファベット(大文字と小文字)、数字、基本的な句読点を含む128文字を表すことができます。 ASCIIには、改行、タブ、キャリッジリターンなど、多くの「印刷できない」文字も含まれていました。 たとえば、ASCIIでは、ラテン文字M(大文字のm)は数字77(16進表記の4D)としてエンコードされます。
ASCIIの問題は、英語のテキストを使用する人々が通常使用するすべての文字を表すのに128文字で十分かもしれませんが、この文字数では他の言語のテキストや絵文字などのさまざまな特殊文字を表すには不十分であることです。
この問題の解決策は、絵文字などの文字を含むすべての現代および古代のテキストで使用される各文字を表す可能性を目的としたUnicode標準の採用でした。 たとえば、最新のUnicode 12.0標準では、137,000以上の文字があります。
Unicode標準は、さまざまな文字エンコード方式を使用して実装できます。 最も一般的なのはUTF-8およびUTF-16です。 Webスペースで最も一般的なのは、テキストUTF-8のコーディングの標準であることに注意してください。
UTF-8標準では、1〜4バイトを使用して文字を表します。 UTF-8はASCIIのスーパーセットであるため、最初の128文字はASCIIコードテーブルで表される文字と一致します。 一方、UTF-16標準では、2〜4バイトを使用して1文字を表します。
なぜ両方の規格があるのですか? 実際には、西洋言語のテキストは通常、UTF-8標準を使用して最も効率的にエンコードされます(そのようなテキストのほとんどの文字は1バイトサイズのコードとして表現できるため)。 オリエンタル言語について話をすると、これらの言語で書かれたテキストを保存するファイルは、UTF-16を使用する場合、通常は少なくなります。
Unicodeコードポイントと文字エンコード
Unicode標準の各文字には、コードポイントと呼ばれる識別番号が割り当てられます。 たとえば、コードポイント絵文字
 はU + 1F436です。
はU + 1F436です。
このアイコンをエンコードする場合、さまざまなバイトシーケンスとして表すことができます。
- UTF-8:4バイト、
0xF0 0x9F 0x90 0xB6
- UTF-16:4バイト、
0xD83D 0xDC36
以下のJavaScriptコードでは、3つのコマンドすべてがブラウザーコンソールに同じ文字を出力します。
//
console.log(' ') // =>
// Unicode (ES2015+)
console.log('\u{1F436}') // =>
// UTF-16
// ( 2 )
console.log('\uD83D\uDC36') // =>
ほとんどのJavaScriptインタープリターの内部メカニズム(Node.jsおよび最新のブラウザーを含む)はUTF-16を使用します。 これは、考慮している犬のアイコンが2つのUTF-16コード単位(各16ビット)を使用して保存されることを意味します。 したがって、次のコードの出力が理解できないと思わないでください。
console.log(' '.length) // => 2
キャラクターの組み合わせ
では、始めたところに戻りましょう。つまり、人にとって同じように見えるシンボルが異なる内部表現を持っている理由について話しましょう。
一部のUnicode文字は、他の文字を変更するように設計されています。 それらは結合文字と呼ばれます。 基本文字に適用されます。例:
-
n + ˜ = ñ
-
u + ¨ = ü
-
e + ´ = é
前の例からわかるように、組み合わせ可能な文字を使用すると、発音区別符号を基本文字に追加できます。 ただし、Unicodeの文字変換機能はこれに限定されません。 たとえば、一部の文字シーケンスは合字として表すことができます(したがって、aeはæになります)。
問題は、特殊文字をさまざまな方法で表現できることです。
たとえば、文字éは2つの方法で表すことができます。
- 単一のコードポイントU + 00E9を使用します。
- 文字eと鋭角記号の組み合わせを使用して、つまり、2つのコードポイントU + 0065およびU + 0301を使用します。
文字éを表すこれらの方法のいずれかを使用した結果の文字は同じように見えますが、比較すると、文字が異なっていることがわかります。 それらを含む行の長さは異なります。 これを確認するには、ブラウザコンソールで次のコードを実行します。
console.log('\u00e9') // => é console.log('\u0065\u0301') // => é console.log('\u00e9' == '\u0065\u0301') // => false console.log('\u00e9'.length) // => 1 console.log('\u0065\u0301'.length) // => 2
これにより、予期しないエラーが発生する場合があります。 たとえば、プログラムは、未知の理由により、データベース内の一部のエントリを見つけることができず、正しいパスワードを入力したユーザーがシステムにログインできないという事実で表現できます。
行の正規化
上記の問題には単純な解決策があります。これは、文字列を正規化し、「標準的な表現」にすることです。
正規化には4つの標準形式(アルゴリズム)があります。
- NFC:正規化フォームの正規構成。
- NFD:正規化形式の正規分解。
- NFKC:正規化フォームの互換性構成。
- NFKD:正規化フォームの互換性分解。
最も一般的に使用される正規化の形式はNFCです。 このアルゴリズムを使用して、すべての文字が最初に分解され、その後、すべての結合シーケンスが標準で定義された順序で再構成されます。 実用的には、任意の形式を選択できます。 主なことは、一貫して適用することです。 その結果、プログラム入力で同じデータを受信すると、常に同じ結果になります。
JavaScriptでは、ES2015(ES6)標準以降、文字列を正規化するための組み込みメソッドString.prototype.normalize([form])があります。 Node.js環境およびほとんどすべての最新ブラウザーで使用できます。 このメソッドの
form
引数は、正規化フォームの文字列識別子です。 デフォルトはNFCフォームです。
以前に検討した例に戻り、今回は正規化を適用します。
const str = '\u0065\u0301' console.log(str == '\u00e9') // => false const normalized = str.normalize('NFC') console.log(normalized == '\u00e9') // => true console.log(normalized.length) // => 1
まとめ
Webアプリケーションを開発し、ユーザーが入力した内容を使用する場合は、受信したテキストデータを常に正規化します。 JavaScriptでは、標準の文字列メソッドnormalize()を使用して正規化を実行できます。
親愛なる読者! 正規化で解決できる文字列の問題に遭遇しましたか?
