ステップ0。ここで何が起こっていますか?
そもそも、「クローバー」の仕組みを思い出してください。
全員のゲームは、モスクワ時間の13:00と20:00に同時に開始されます。 プレイするには、この時点でアプリケーションにアクセスし、ライブブロードキャストに接続する必要があります。 ゲームは15分間続き、その間に電話で参加者に質問が送信されます。 答えは10秒です。 その後、正しい答えが発表されます。 推測したすべての人はさらに先へ進みます。 全部で12の質問があり、すべてに答えると、賞金がもらえます。
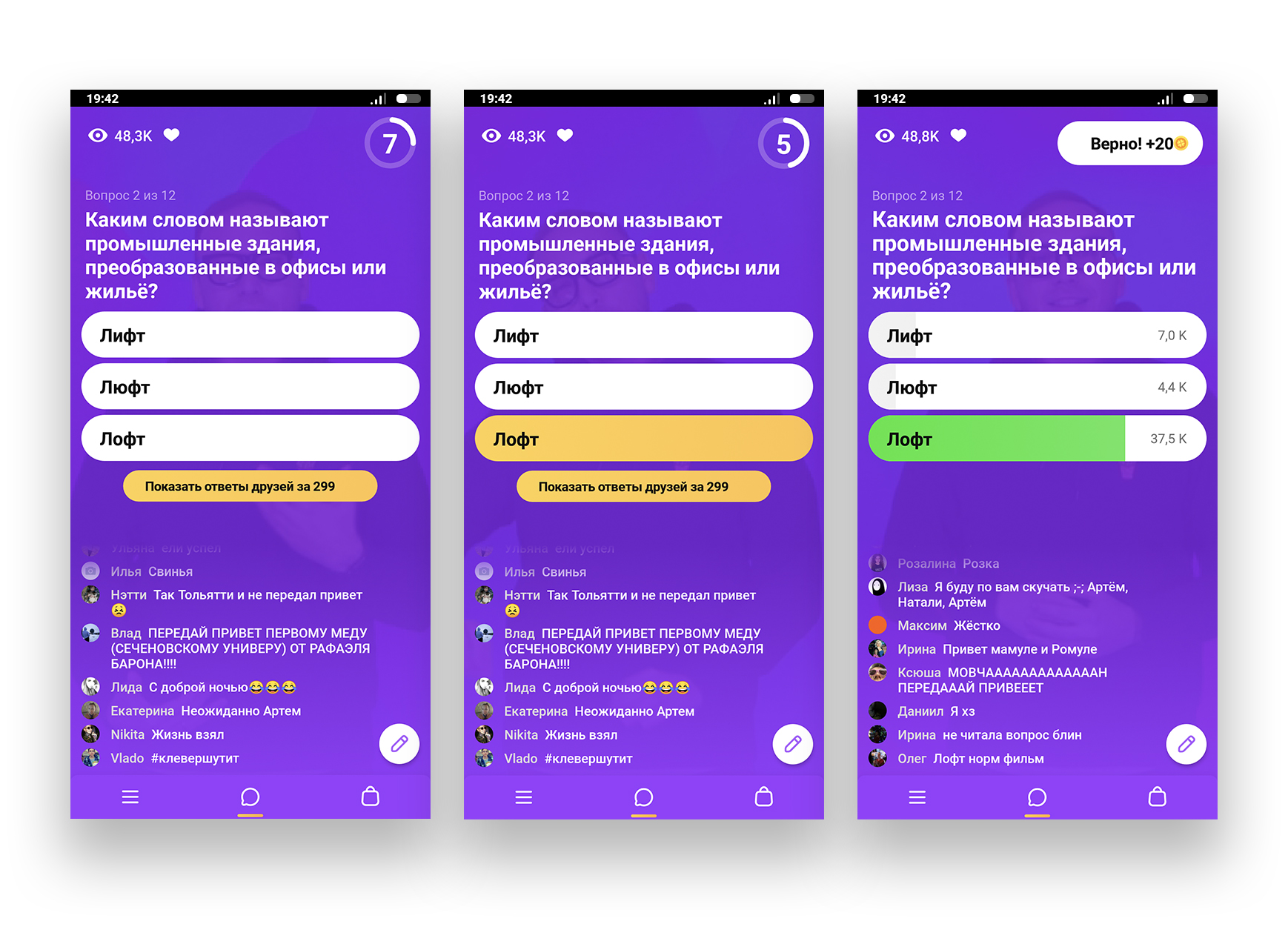
私たちのタスクは、Cloverサーバーから新しい質問を即座にキャッチし、検索エンジンで処理し、検索結果に基づいて正しい答えを決定することです。 ゲーム中に電話から通知がポップアップするように、テレグラムボットで回答を出力することにしました。 応答時間は非常に限られているため、これらすべては数秒で完了します。 かなりシンプルですが、動作するコード(そして、このコードを見ると初心者には便利です)が見たければ、Cloverを打ち負かすのに役立ちました-カットへようこそ。
ステップ1.サーバーから質問を取得する
最初は最も難しい段階に見えました。 私はすでに深呼吸をしていて、コンピュータービジョン、トラフィックのインターセプト、アプリケーションの逆コンパイルなどの荒野に登る準備ができていました...突然の驚きが私を待っていました-CloverにはオープンAPIがあります それはどこにも文書化されていませんが、ゲーム中にすべてのプレイヤーが質問された直後にapi.vk.comでリクエストを行うと、それに応じてJSONで質問と回答のオプションを取得します:
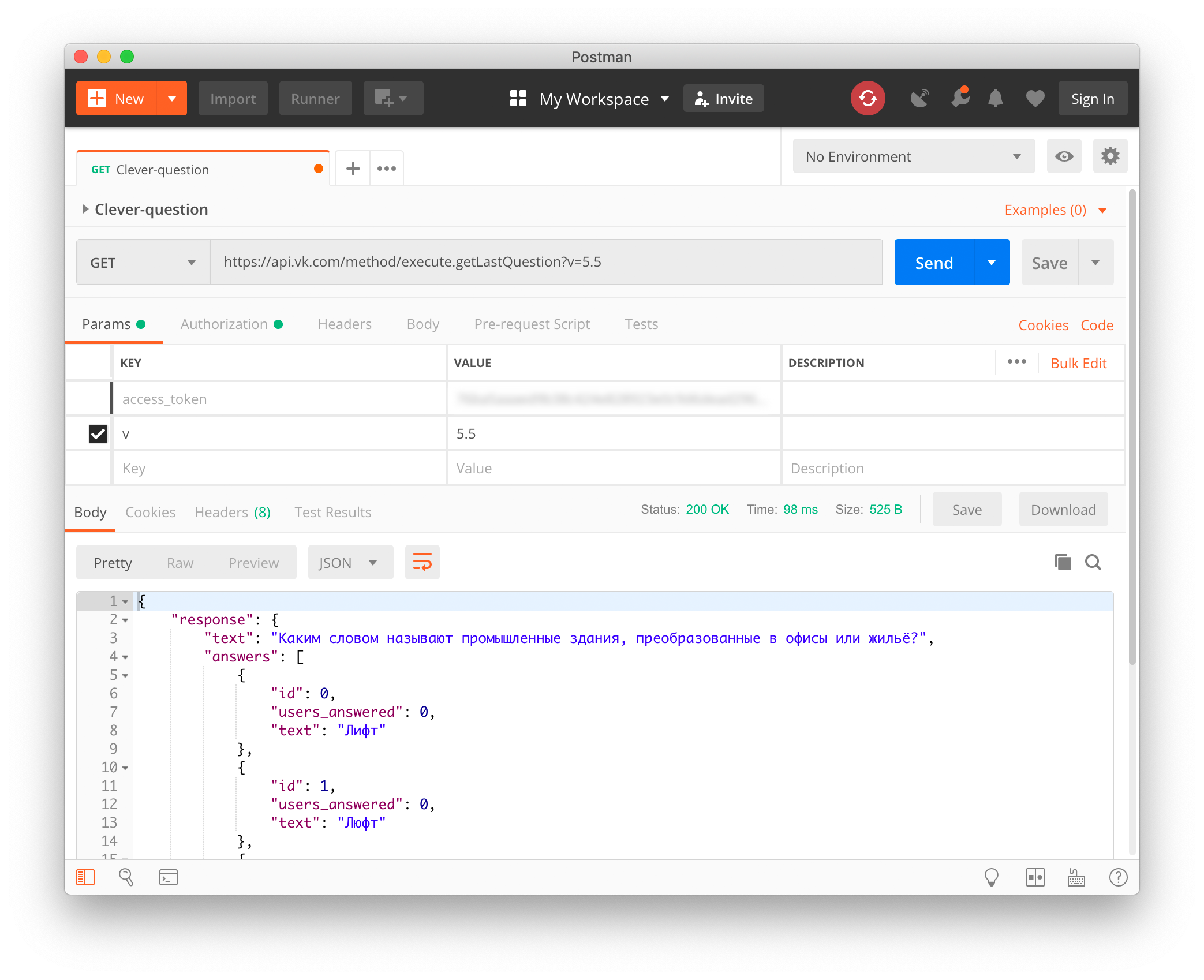
https://api.vk.com/method/execute.getLastQuestion?v=5.5&access_token=VK_USER_TOKEN
access_tokenとして、VKontakteユーザーのAPIトークンを転送する必要がありますが、元々Clover専用に発行されたことが重要です。 彼のapp_idは6334949です。
ステップ2.検索エンジンを通じて問題を処理します
2つのオプションがありました。公式の検索エンジンAPIを使用するか、検索引数をアドレスバーに直接追加するか、結果を解析します。 最初は2番目の方法を試しましたが、時々キャプチャをキャッチしただけでなく、ページが平均2秒でロードされるため、多くの時間を失いました。 そして、私はこれらの非常に2秒に会うことを勧めます。 最も重要なことは、 スニペットと呼ばれる必要な資料のほんの一部が検索ページにハングアップしているため、必要なトピックに関する検索エンジンから大きな構造化されたテキストを取得しなかったことです。

そこで、APIを探し始めました。 Googleは適合しませんでした-彼らのソリューションは非常に限られており、ほとんどデータを返しませんでした。 Yandex.XMLは最も寛大であることが判明しました。1日に10,000リクエストを送信でき、1秒間に5回以下であり、非常に迅速にデータを返します。 オプションとして、ページ数(最大100)とパッセージ数(スニペットの形成に使用される特別な値)が要求されます。 XMLでデータを取得します。 ただし、これらはすべて同じスニペットです。
Yandexが返すものに慣れて遊ぶことができるように、「ビデオシリーズ「ゼルダの伝説」の主な敵対者の名前は何ですか?」: Yandexというクエリに対する回答の例を次に示します。 ドライブ 。
幸運なことに、pypiには、このために別のyandex-searchモジュールがすでに存在することがわかりました。 そこで、サーバーから質問を取得し、Yandexでそれを見つけ、スニペットから1つの大きなテキストを作成し、それを文章に分割しようとしました。
import requests as req import yandex_search import json apiurl = "https://api.vk.com/method/execute.getLastQuestion?access_token=VK_USER_TOKEN&v=5.5" clever_response = (json.loads(req.get(apiurl).content))["response"] # {'text': ' « »?', 'answers': [{'id': 0, 'users_answered': 0, 'text': '« »'}, {'id': 1, 'users_answered': 0, 'text': '« »'}, {'id': 2, 'users_answered': 0, 'text': '«»'}], 'stop_time': 0, 'is_first': 0, 'is_last': 1, 'number': 12, 'id': 22, 'sent_time': 1533921436} question = str(clever_response["text"]) ans1, ans2, ans3 = str(clever_response["answers"][0]["text"]).lower(), str(clever_response["answers"][1]["text"]).lower(), str(clever_response["answers"][2]["text"]).lower() def yandexfind(question): finded = yandex.search(question).items snips = "" for i in finded: snips += (i.get("snippet")) + "\n" return snips items = yandexfind(question) itemslist = list(items.split(". "))
ステップ3.回答を検索する
最初は、スニペットに従って答えを正確に認識するタスクは、私には非現実的でした(コードを書いている時点では、私は絶対的な初心者だったことを思い出します)。 そのため、最初に手動検索で実行するタスクを単純化することにしました。
質問を検索エンジンに送り込んだとき、友人と私は何をしましたか? 彼らは結果の答えをすぐに目を通して見始めました。 このアプローチの問題点は何ですか?
hint = [] # , for sentence in itemslist: # if (ans1 in sentence) or (ans2 in sentence) or (ans3 in sentence): hint.append(sentence) if len(hint) > 4: break
適切なオファーを取得し、それらを読んで、正しく答えるようです。 しかし、1つの文が見つからなかった場合はどうなりますか? この場合、別のケースにある場合に見逃さないように単語をトリミングすることにしました。 また、ソースから形成されたものをキャプチャします。 要するに、私はちょうどそれらの終わりを2つの文字にトリミングしました:
if len(hint) == 0: def cut(string): if len(string) > 2: return string[0:-2] else: return string short_ans1, short_ans2, short_ans3 = cut(ans1), cut(ans2), cut(ans3) for pred in itemslist: # if (short_ans1 in pred) or (short_ans2 in pred) or (short_ans3 in pred) hint.append(pred)
しかし、そのようなセーフティネットの後でも、結果が常に答えに触れなかったという理由だけで、ヒントが空のままである場合がまだありました。 「これらの作家のうち、グループBi 2の歌に似た名前の物語はどれですか」という質問に対して、正確な答えはありません 。 この場合、私は反対のアプローチに頼りました-私は答えについて尋ね、質問からの単語が結果で言及されている頻度に基づいてオプションを推測しました。
if len(hint) == 0: questionlist = question.split(" ") blacklist = ["", "", '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', ''] for w in questionlist: if w in blacklist: questionlist.remove(w) yandex_ans1 = yandexfind(ans1) yandex_ans2 = yandexfind(ans2) yandex_ans3 = yandexfind(ans3) # , count_ans1, count_ans2, count_ans3 = 0, 0, 0 for w in questionlist: count_ans1 += yandex_ans1.count(w) count_ans2 += yandex_ans2.count(w) count_ans3 += yandex_ans3.count(w) if (count_ans1 + count_ans2 + count_ans3) > 5: if count_ans1 > (count_ans2 + count_ans3): print(ans1) elif count_ans2 > (count_ans1 + count_ans3): print(ans2) elif count_ans3 > (count_ans2 + count_ans1): print(ans3)
この時点で、スクリプトは基本的な機能を獲得しました。 そして今、クローバーのリリースからわずか1週間半で、私たちは座って、すでにそのような自作の「チート」で遊んでいます。 私たちが最初にゲームに勝ったとき、魔法のようにコマンドラインの提案を読んで、友人と顔を見たはずです!
ステップ4.明確な回答を表示する
しかし、すぐにこのフォーマットは疲れます。 まず、ゲームごとにラップトップを使用する必要がありました。 次に、友人がスクリプトを要求しました。VKontakteトークンの挿入方法、Yandex.XMLの構成方法(IPに関連付けられています。つまり、スクリプトの各ユーザーのアカウントを作成する必要がありました)およびpythonをコンピューターにインストールする方法を説明するのはうんざりです。
ゲーム中に電話のプッシュ通知に回答がポップアップ表示されると、はるかに良いでしょう! 画面の上部を見て、プッシュ通知に書かれているとおりに答えてください! また、スクリプト用に独自の電報チャネルを作成すれば、すべての人のためにこれを整理できます! 素晴らしい!
しかし、同じ文を電報で単に表示することは選択肢ではありません。 あなたの電話からそれらを読むことは非常に不便です。 したがって、どの答えが正しいかを理解するには、自分でスクリプトを学習する必要がありました。
テレボットをインポートし、すべてのprint()関数をsend_tg()およびnotsure()に変更します 。これは最後の方法で使用します。
def send_tg(ans): bot.send_message("@autoclever", str(ans).capitalize()) print(str(ans)) return def notsure(ans): send_tg(ans.capitalize() + ". !") hint.append("WE TRIED!")
この時点で、スニペットは長いテキストよりもはるかに優れていることに気付きました! なぜなら、検索エンジンは、単語の一致を見つけるだけでなく、実際に私たちの要求に答えようとするからです。 そして彼は成功しました-スニペットはしばしば間違ったものよりも正しい答えを含んでいました。つまり、テキストを分析する必要はありませんでした。 はい、実際、私はその方法を知りませんでした。
したがって、結果に含まれる単語の言及を数えるのは簡単です。
anscounts = { ans1: 0, ans2: 0, ans3: 0 } for s in hint: for a in [ans1, ans2, ans3]: anscounts[a] += s.count(a) right = (max(anscounts, key=anscounts.get)) send_tg(right) #!
結果として何が起こったのか:

さらなる運命
公平に言えば、私はデスマシーンで成功しなかったと言わなければなりません。 平均して、ボットは12の質問のうち9〜10のみを正しく回答しました。 Yandex検索の解析に負けなかったトリッキーな人がいたので、それは理解できます。 私と私の友人は、いくつかの質問を常に飛び回り、ゲームが成功するのを待つのにうんざりしました。ボットは最終的にすべてを正しく答えます。 奇跡は起こらず、台本の完成はもはや望まれていませんでした。そして、簡単な勝利への希望を失い、ゲームを放棄しました。
時間が経つにつれて、私のアイデアは他の若い開発者の頭に忍び込み始めました。 2018年の日没までに、少なくとも10個のボットとサイトがあり、Cloverの問題に関する推測を表示していました。 タスクはそれほど難しくありません。 しかし、驚くべきことに、ゲームごとに9から10の質問の限界を超えたことはなく、私のボットのように、すべてが7から8に落ちました。 どうやら、質問の編集者は、検索エンジンの仕事が関係ないように質問を構成する方法を見つけました。
残念ながら、12月31日にクローバーが最後のブロードキャストを費やし、私には質問がなかったため、ボットはもうファイナライズできません。 しかし、初心者のプログラマーにとっては素晴らしい経験でした。 確かに上級者にとっては大きな課題があります-word2vecとtext2vecのデュオ、Yandex、Google、Wikipediaへの非同期リクエスト、高度な質問の分類子、失敗した場合に質問を再構成するアルゴリズムを想像してください... おそらく、そのような機会のために、私はゲームプレイ自体よりもこのゲームを愛していました。