
それでは、次世代のマルチセルラープロセッサであるMultiClet S1についてお話します。 初めて聞いた場合は、これらの記事で建築の歴史とイデオロギーを確認してください。
現在、新しいプロセッサは開発中ですが、最初の結果がすでに表示されているので、それが何を可能にするかを評価できます。
最大の変更から始めましょう:基本機能。
特徴。
以下の指標を達成する予定です。
- セルの数:64
- 技術プロセス:28 nm
- クロック周波数:1.6 GHz
- チップ上のメモリのサイズ:8 MB
- クリスタル面積:40mm 2
- 消費電力:6 W
実数は、2019年に製造されたサンプルのテスト結果に基づいて発表されます。 プロセッサは、チップ自体の特性に加えて、最大16 GBのDDR4 3200MHz標準RAM、PCI Expressバス、およびPLLをサポートします。
28 nm製造プロセスは、使用に特別な許可を必要としない最も低い世帯の範囲であるため、選択されたのは彼であることに注意する必要があります。 セルの数によって、128と256の異なるオプションが考慮されましたが、結晶の面積が増加すると、不良品の割合が増加します。 64個のセル、したがって、比較的小さな面積に収まりました。これにより、プレート上に適切な結晶がより多く生成されます。 ICS(この場合はシステム)のフレームワーク内でさらなる開発が可能であり、1つのケースで複数の64セル結晶を組み合わせることができます。
プロセッサの目的とアプリケーションは根本的に変化していると言わなければなりません。 S1は、P1やR1のような埋め込み用に設計されたマイクロプロセッサではなく、計算のアクセラレータです。 GPGPUと同様に、S1ベースのボードは通常のPCのPCI Expressマザーボードに挿入し、データ処理に使用できます。
建築
S1では、「マルチセル」は最小の計算単位です。特定のコマンドシーケンスを実行する4つのセルのセットです。 最初は、コマンドの共同実行のために、マルチセルをクラスターと呼ばれるグループに結合することが計画されていました。1つのクラスターには4つのマルチセルが含まれていなければなりません。 ただし、各セルはクラスター内の他のすべてのセルと完全に接続されており、結合グループが増えると多すぎて、マイクロ回路のトポロジ設計が非常に複雑になり、その特性が低下します。 そのため、合併症は結果を正当化しないため、クラスター分割を放棄することにしました。 さらに、最大のパフォーマンスを得るには、各マルチセルでコードを並行して実行することが最も有益です。 合計で、プロセッサには16個の個別のマルチセルが含まれています。
マルチセルは4つのセルで構成されていますが、4つのセルR1とは異なり、各セルには独自のメモリ、独自の命令ブロック、ALUがあります。 S1の配置は少し異なります。 ALUには、浮動小数点演算ブロックと整数演算ブロックの2つの部分があります。 各セルには個別の整数ブロックがありますが、マルチセルには浮動小数点を持つブロックが2つしかないため、2つのセルのペアがそれらを分割します。 これは主に水晶の面積を減らすために行われました。整数演算とは対照的に、64ビット浮動小数点演算は多くのスペースを占有します。 各セルにこのようなALUがあることは冗長であることが判明しました。コマンドをフェッチしてもALUのロードは提供されず、アイドル状態になります。 ALUブロックの数を減らし、サンプルコマンドとデータのペースを維持しながら、実践が示しているように、問題を解決するための合計時間は実際には変化しないか、わずかに変化し、ALUブロックは完全にロードされます。 さらに、浮動小数点演算は、整数ほど頻繁には使用されません。
プロセッサR1およびS1のブロックの概略図を以下の図に示します。 ここに:
- CU(コントロールユニット)-命令選択ブロック
- ALU FX-整数演算の算術論理ユニット
- ALU FP-浮動小数点演算の算術論理ユニット
- DMS(データメモリスケジューラ)-データメモリ制御ユニット
- DM-データメモリ
- PMS(プログラムメモリスケジューラ)-プログラムメモリ制御ユニット
- PM-プログラムメモリ
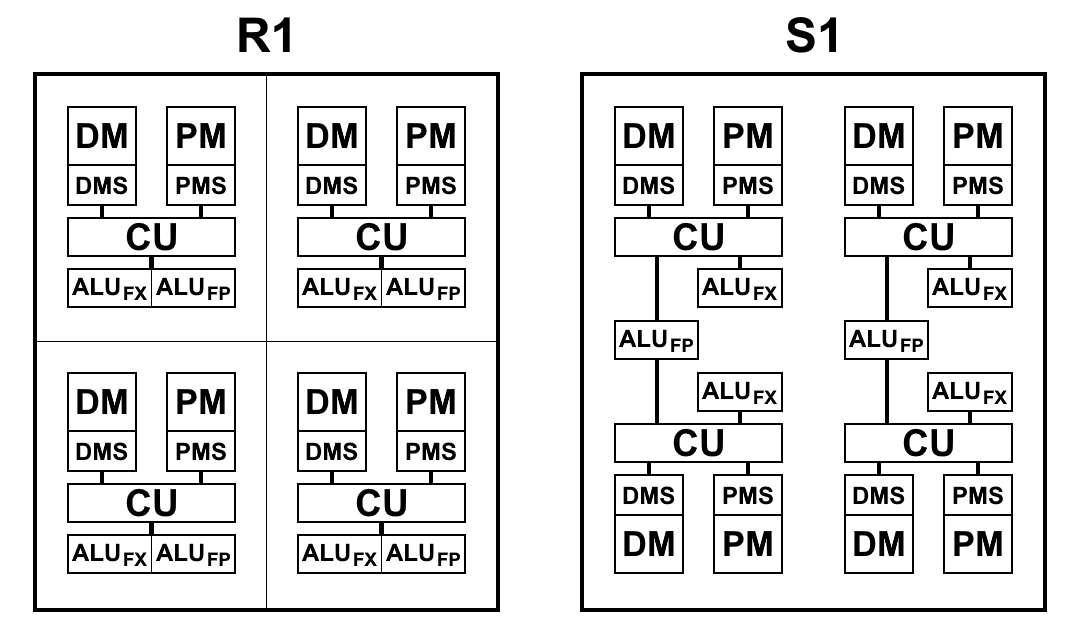
アーキテクチャの違いS1:
- チームは、前の段落のチーム結果にアクセスできるようになりました。 これは非常に重要な変更であり、コードを分岐する際の移行を大幅に高速化できます。 プロセッサP1とR1には、メモリに目的の結果を書き込み、すぐに新しい段落の最初のコマンドでそれらを読み返す以外に選択肢がありませんでした。 チップ上のメモリを使用する場合でも、書き込みおよび読み取り操作はそれぞれ2〜5サイクルかかり、前の段落のコマンドの結果を参照するだけで節約できます。
- メモリとレジスタへの書き込みは、段落の終わりではなく、すぐに行われるようになりました。これにより、段落の終わりよりも前にコマンドの書き込みを開始できます。 その結果、段落間の潜在的なダウンタイムが短縮されます。
- コマンドシステムは最適化されています。
- 64ビット整数演算を追加:32ビット数の加算、減算、乗算。64ビットの結果を返します。
- メモリからの読み取り方法が変更されました。現在、 どのコマンドでも、読み取りコマンドと書き込みコマンドの実行順序を維持しながら、データを読み取るアドレスを引数として指定できます。
また、別のメモリ読み取りコマンドが廃止されました。 代わりに、引数としてメモリ内のアドレスを指定して、load switch(以前はget )に対してload valueコマンドを使用します。
.data foo: .long 0x1234 .text habr: load_l foo ; foo load_l [foo] ; 0x1234 add_l [foo], 0xABCD ; ; complete
- 2つの定数引数を使用できるコマンド形式が追加されました。
以前は、2番目の引数としてのみ定数を指定できました。最初の引数は常にスイッチの結果へのリンクである必要があります。 この変更は、2つの引数を持つすべてのチームに適用されます。 定数フィールドは常に32ビットなので、この形式では、たとえば、1つのコマンドで64ビットの定数を生成できます。
それは:
load_l 0x12345678 patch_q @1, 0xDEADBEEF
次のようになりました:
patch_q 0x12345678, 0xDEADBEEF
- 変更および補足されたベクターデータタイプ。
「パック」データ型と呼ばれていたものは、今では安全にベクトルと呼ぶことができます。 P1およびR1では、パックされた数値の演算は、2番目の引数として定数のみを取りました。つまり、たとえば、ベクトルの各要素が同じ数値で追加された場合、これはインテリジェントに適用できませんでした。 現在、同様の操作を2つの完全なベクトルに適用できます。 さらに、このベクターの操作方法は、LLVMのベクターのメカニズムと完全に一致しており、コンパイラーがベクター型を使用してコードを生成できるようになりました。
patch_q 0x00010002, 0x00030004 patch_q 0x00020003, 0x00040005 mul_ps @1, @2 ; - 00020006000C0014
- プロセッサフラグが削除されました。
その結果、フラグの値のみに基づいた約40チームが削除されました。 これにより、チームの数が大幅に削減され、それに応じてクリスタルの面積が削減されました。 そして、必要な情報はすべてスイッチセルに直接保存されます。
- ゼロフラグの代わりにゼロと比較する場合、スイッチの値のみが使用されるようになりました
- 符号フラグの代わりに、コマンドのタイプに対応するビットが使用されるようになりました。バイトに7番目、ショートに15番目、ロングに31番目、クアッドに63番目です。 タイプに関係なく、63ビットまで符号が乗算されるという事実により、異なるタイプの数値を比較できます。
.data long: .long -0x1000 byte: .byte -0x10 .text habr: a := load_b [byte] ; 0xFFFFFFFFFFFFFFF0, ; byte 7 63. b := loadu_b [byte] ; 0x00000000000000F0, ; .. loadu_b c := load_l [long] ; 0xFFFFFFFFFFFFF000. ge_l @a, @c ; " " 1: ; 31 , . lt_s @a, @b ; 1, .. b complete
- 64ビット演算があるため、キャリーフラグは不要になりました。
- 段落から段落への移行時間は1メジャーに短縮されました(R1の2-3の代わりに)
LLVMベースのコンパイラ
S1のC言語コンパイラはR1に似ており、アーキテクチャが根本的に変更されていないため、残念ながら前の記事で説明した問題は消えていません。
ただし、新しいコマンドシステムの実装プロセスでは、単にコマンドシステムの更新が原因で、出力コードの量が自動的に減少しました。 さらに、コード内の命令数を削減するマイナーな最適化がさらに多くあり、その一部は既に実行されています(たとえば、単一の命令で64ビット定数を生成する)。 しかし、さらに深刻な最適化を行う必要があり、効率と実装の複雑さの両方の昇順で構築できます。
- 2つの定数を持つすべての2引数コマンドを生成する機能。
patch_qを介した64ビット定数の生成は特別な場合ですが、一般的なものが必要です。 実際、この最適化のポイントは、チームが最初の引数だけを定数として置き換えることです。2番目の引数は常に定数であり、これは長い間実装されてきたためです。 これはあまり頻繁なケースではありませんが、たとえば、関数を呼び出してそのアドレスからスタックの先頭に戻りアドレスを書き込む必要がある場合、次のことができます。
load_l func wr_l @1, #SP
最適化する
wr_l func, #SP
- 任意のコマンドの引数を介してメモリアクセスを置換する機能。
たとえば、メモリから2つの数値を追加する必要がある場合、次のことができます。
load_l [foo] load_l [bar] add_l @1, @2
最適化する
add_l [foo], [bar]
この最適化は以前の最適化の拡張ですが、ここではすでに分析が必要です。このような置換は、ロードされた値がこの追加コマンドで一度だけ使用され、他では使用されない場合にのみ実行できます。 読み取り結果が2つのコマンドのみで使用される場合、メモリから1つの個別のコマンドとして読み取り、他の2つではスイッチを介してそれを参照する方が有利です。
- ベースユニット間の仮想レジスタの転送の最適化。
R1では、すべての仮想レジスタの転送はメモリを介して行われたため、メモリへの読み取りと書き込みが非常に多く発生しましたが、段落間でデータを転送する他の方法はありませんでした。 S1では、前の段落のコマンドの結果にアクセスできます。したがって、理論的には、多くのメモリ操作を削除できます。これにより、すべての最適化の中で最大の効果が得られます。 ただし、このアプローチはまだスイッチによって制限されています。63個までの以前の結果は、これまでのところ、仮想レジスタのすべての転送をこのように実装できます。 これを行う方法は簡単な作業ではなく、それを解決する可能性の分析はまだ行われていません。 コンパイラのソースはパブリックドメインに表示される場合があるため、だれかがアイデアを持っていて、開発に参加したい場合は、それを行うことができます。
ベンチマーク
プロセッサはまだチップ上でリリースされていないため、実際のパフォーマンスを評価することは困難です。 ただし、RTLカーネルコードは既に用意されているため、シミュレーションまたはFPGAを使用して評価を行うことができます。 次のベンチマークを実行するために、ModelSimプログラムを使用したシミュレーションを使用して、正確な実行時間(測定値)を計算しました。 クリスタル全体をシミュレートするのは難しく、時間がかかるため、各マルチセルは完全に独立して動作できるため、1つのマルチセルをシミュレートし、結果に16を掛けました(タスクがマルチスレッド用に設計されている場合)。
同時に、Xilinx Virtex-6でマルチセルモデリングが実行され、実際のハードウェアでプロセッサコードのパフォーマンスがテストされました。
コアマーク
CoreMark-マイクロコントローラーと中央処理装置、およびそれらのCコンパイラーのパフォーマンスを包括的に評価するための一連のテスト。 ご覧のとおり、S1プロセッサはどちらでもありません。 ただし、完全に調停コードを実行することを意図しています。 中央処理装置で実行できるすべての人。 したがって、CoreMarkはS1のパフォーマンスを悪く評価するのに適しています。
CoreMarkには、リンクリスト、マトリックス、ステートマシン、 CRC合計計算の機能が含まれています。 一般に、ほとんどのコードは厳密にシーケンシャルであり(マルチセルハードウェアの並列性の強度をテストします )、多くの分岐があるため、コンパイラーの機能は最終的なパフォーマンスで重要な役割を果たします。 コンパイルされたコードには短いパラグラフがかなり含まれており、それらの間の遷移速度が向上したという事実にもかかわらず、分岐にはメモリの操作が含まれます。
CoreMark比較チャート:
| Multiclet R1(llvmコンパイラー) | Multiclet S1(llvmコンパイラー) | Elbrus-4C(R500 / E) | テキサス工科大学 AM5728 ARM Cortex-A15 | バイカル-t1 | Intel Core i7 7700K | |
|---|---|---|---|---|---|---|
| 製造年 | 2015 | 2019年 | 2014 | 2018年 | 2016年 | 2017年 |
| クロック周波数、MHz | 100 | 1600 | 700 | 1500 | 1200 | 4500 |
| CoreMark総合スコア | 59 | 18356 | 1214 | 15789 | 13142 | 182128 |
| コアマーク/ MHz | 0.59 | 11.47 | 5.05 | 10.53 | 10.95 | 40.47 |
1つのマルチセルの結果は1147、つまり0.72 / MHzで、R1の結果よりも高くなっています。 これは、新しいプロセッサでのマルチセルラーアーキテクチャの開発の利点について語っています。
ホイートストン
砥石-浮動小数点数を処理する際のプロセッサのパフォーマンスを測定するための一連のテスト。 ここでは、状況ははるかに良好です。コードもシーケンシャルですが、多数のブランチがなく、内部同時実行性が良好です。
Whetstoneは多くのモジュールで構成されているため、全体的な結果だけでなく、特定の各モジュールのパフォーマンスも測定できます。
- 配列要素
- パラメータとしての配列
- 条件付きジャンプ
- 整数演算
- 三角関数(tan、sin、cos)
- 手続き呼び出し
- 配列参照
- 標準関数(sqrt、exp、log)
これらはカテゴリに分類されます。モジュール1、2、および6は、浮動小数点演算のパフォーマンスを測定します(行MFLOPS1〜3)。 モジュール5および8-数学関数(COS MOPS、EXP MOPS)。 モジュール4および7-整数演算(FIXPT MOPS、EQUAL MOPS)。 モジュール3-条件付きジャンプ(IF MOPS)。 次の表では、MWIPSの2行目が一般的な指標です。
CoreMarkとは異なり、Whetstoneは1つのコアで比較されますが、この場合は1つのマルチセルで比較されます。 コアの数はプロセッサごとに非常に異なるため、実験の純度のために、メガヘルツあたりの指標を考慮します。
砥石スコアカード:
| CPU | MultiClet R1 | MultiClet S1 | Core i7 4820K | ARM v8-A53 |
|---|---|---|---|---|
| 周波数、MHz | 100 | 1600 | 3900 | 1300 |
| MWIPS / MHz | 0.311 | 0.343 | 0.887 | 0.642 |
| MFLOPS1 / MHz | 0.157 | 0.156 | 0.341 | 0.268 |
| MFLOPS2 / MHz | 0.153 | 0.111 | 0.308 | 0.241 |
| MFLOPS3 / MHz | 0.029 | 0.124 | 0.167 | 0.239 |
| COS MOPS / MHz | 0.018 | 0.008 | 0.023 | 0.028 |
| EXP MOPS / MHz | 0.008 | 0.005 | 0.014 | 0.004 |
| FIXPT MOPS / MHz | 0.714 | 0.116 | 0.998 | 1.197 |
| IF MOPS / MHz | 0.081 | 0.196 | 1.504 | 1.436 |
| EQUAL MOPS / MHz | 0.143 | 0.149 | 0.251 | 0.439 |
WhetstoneにはCoreMarkよりもはるかに直接的な計算操作が含まれているため(以下のコードを見ると非常に顕著です)、ここで覚えておくことが重要です:浮動小数点ALUの数は半分になります。 ただし、R1と比較して、計算速度はほとんど影響を受けませんでした。
一部のモジュールは、マルチセルラーアーキテクチャに非常に適しています。 たとえば、モジュール2はサイクルで多くの値をカウントし、プロセッサーとコンパイラーの両方による倍精度浮動小数点数の完全なサポートのおかげで、コンパイル後、マルチセルラーアーキテクチャの計算能力を本当に明らかにする大きく美しい段落を取得します。
120チーム用の大きくて美しい段落
pa: SR4 := loadu_q [#SP + 16] SR5 := loadu_q [#SP + 8] SR6 := loadu_l [#SP + 4] SR7 := loadu_l [#SP] setjf_l @0, @SR7 SR8 := add_l @SR6, 0x8 SR9 := add_l @SR6, 0x10 SR10 := add_l @SR6, 0x18 SR11 := loadu_q [@SR6] SR12 := loadu_q [@SR8] SR13 := loadu_q [@SR9] SR14 := loadu_q [@SR10] SR15 := add_d @SR11, @SR12 SR11 := add_d @SR15, @SR13 SR15 := sub_d @SR11, @SR14 SR11 := mul_d @SR15, @SR5 SR15 := add_d @SR12, @SR11 SR12 := sub_d @SR15, @SR13 SR15 := add_d @SR14, @SR12 SR12 := mul_d @SR15, @SR5 SR15 := sub_d @SR11, @SR12 SR16 := sub_d @SR12, @SR11 SR17 := add_d @SR11, @SR12 SR11 := add_d @SR13, @SR15 SR13 := add_d @SR14, @SR11 SR11 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR11 SR15 := add_d @SR17, @SR11 SR16 := add_d @SR14, @SR13 SR13 := div_d @SR16, @SR4 SR14 := sub_d @SR15, @SR13 SR15 := mul_d @SR14, @SR5 SR14 := add_d @SR12, @SR15 SR12 := sub_d @SR14, @SR11 SR14 := add_d @SR13, @SR12 SR12 := mul_d @SR14, @SR5 SR14 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR11, @SR14 SR11 := add_d @SR13, @SR15 SR14 := mul_d @SR11, @SR5 SR11 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR13, @SR11 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR15 := mul_d @SR13, @SR5 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR15 SR14 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR11, @SR13 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR4 := loadu_q @SR4 SR5 := loadu_q @SR5 SR6 := loadu_q @SR6 SR7 := loadu_q @SR7 SR15 := mul_d @SR13, @SR5 SR8 := loadu_q @SR8 SR9 := loadu_q @SR9 SR10 := loadu_q @SR10 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR15 SR14 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR11, @SR13 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR15 := mul_d @SR13, @SR5 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR15 SR14 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR11, @SR13 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR15 := mul_d @SR13, @SR5 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR17 SR14 := mul_d @SR13, @SR5 SR5 := add_d @SR16, @SR14 SR13 := add_d @SR11, @SR5 SR5 := div_d @SR13, @SR4 wr_q @SR15, @SR6 wr_q @SR12, @SR8 wr_q @SR14, @SR9 wr_q @SR5, @SR10 complete
ポップ
(コンパイラに関係なく)アーキテクチャ自体の特性を反映するために、アーキテクチャのすべての機能を考慮してアセンブラーで記述されたものを測定します。 たとえば、512ビット数(popcnt)の単位ビットをカウントします。 わかりやすくするために、1つのマルチセルの結果を使用して、R1と比較できるようにします。
比較表、32ビット計算サイクルあたりのクロックサイクル数:
| アルゴリズム | マルチクレットr1 | マルチクレットS1(1つのマルチセル) |
|---|---|---|
| Bithacks | 5.0 | 2.625 |
ここでは新しい更新されたベクトル命令が使用されたため、R1アセンブラーで実装された同じアルゴリズムと比較して、命令の数を半分にできました。 作業速度はそれぞれ、ほぼ2倍に増加しました。
ポップ
bithacks: b0 := patch_q 0x1, 0x1 v0 := loadu_q [v] v1 := loadu_q [v+8] v2 := loadu_q [v+16] v3 := loadu_q [v+24] v4 := loadu_q [v+32] v5 := loadu_q [v+40] v6 := loadu_q [v+48] v7 := loadu_q [v+56] b1 := patch_q 0x55555555, 0x55555555 i00 := slr_pl @v0, @b0 i01 := slr_pl @v1, @b0 i02 := slr_pl @v2, @b0 i03 := slr_pl @v3, @b0 i04 := slr_pl @v4, @b0 i05 := slr_pl @v5, @b0 i06 := slr_pl @v6, @b0 i07 := slr_pl @v7, @b0 b2 := patch_q 0x33333333, 0x33333333 i10 := and_q @i00, @b1 i11 := and_q @i01, @b1 i12 := and_q @i02, @b1 i13 := and_q @i03, @b1 i14 := and_q @i04, @b1 i15 := and_q @i05, @b1 i16 := and_q @i06, @b1 i17 := and_q @i07, @b1 b3 := patch_q 0x2, 0x2 i20 := sub_pl @v0, @i10 i21 := sub_pl @v1, @i11 i22 := sub_pl @v2, @i12 i23 := sub_pl @v3, @i13 i24 := sub_pl @v4, @i14 i25 := sub_pl @v5, @i15 i26 := sub_pl @v6, @i16 i27 := sub_pl @v7, @i17 i30 := and_q @i20, @b2 i31 := and_q @i21, @b2 i32 := and_q @i22, @b2 i33 := and_q @i23, @b2 i34 := and_q @i24, @b2 i35 := and_q @i25, @b2 i36 := and_q @i26, @b2 i37 := and_q @i27, @b2 i40 := slr_pl @i20, @b3 i41 := slr_pl @i21, @b3 i42 := slr_pl @i22, @b3 i43 := slr_pl @i23, @b3 i44 := slr_pl @i24, @b3 i45 := slr_pl @i25, @b3 i46 := slr_pl @i26, @b3 i47 := slr_pl @i27, @b3 b4 := patch_q 0x4, 0x4 i50 := and_q @i40, @b2 i51 := and_q @i41, @b2 i52 := and_q @i42, @b2 i53 := and_q @i43, @b2 i54 := and_q @i44, @b2 i55 := and_q @i45, @b2 i56 := and_q @i46, @b2 i57 := and_q @i47, @b2 i60 := add_pl @i50, @i30 i61 := add_pl @i51, @i31 i62 := add_pl @i52, @i32 i63 := add_pl @i53, @i33 i64 := add_pl @i54, @i34 i65 := add_pl @i55, @i35 i66 := add_pl @i56, @i36 i67 := add_pl @i57, @i37 b5 := patch_q 0xf0f0f0f, 0xf0f0f0f i70 := slr_pl @i60, @b4 i71 := slr_pl @i61, @b4 i72 := slr_pl @i62, @b4 i73 := slr_pl @i63, @b4 i74 := slr_pl @i64, @b4 i75 := slr_pl @i65, @b4 i76 := slr_pl @i66, @b4 i77 := slr_pl @i67, @b4 b6 := patch_q 0x1010101, 0x1010101 i80 := add_pl @i70, @i60 i81 := add_pl @i71, @i61 i82 := add_pl @i72, @i62 i83 := add_pl @i73, @i63 i84 := add_pl @i74, @i64 i85 := add_pl @i75, @i65 i86 := add_pl @i76, @i66 i87 := add_pl @i77, @i67 b7 := patch_q 0x18, 0x18 i90 := and_q @i80, @b5 i91 := and_q @i81, @b5 i92 := and_q @i82, @b5 i93 := and_q @i83, @b5 i94 := and_q @i84, @b5 i95 := and_q @i85, @b5 i96 := and_q @i86, @b5 i97 := and_q @i87, @b5 iA0 := mul_pl @i90, @b6 iA1 := mul_pl @i91, @b6 iA2 := mul_pl @i92, @b6 iA3 := mul_pl @i93, @b6 iA4 := mul_pl @i94, @b6 iA5 := mul_pl @i95, @b6 iA6 := mul_pl @i96, @b6 iA7 := mul_pl @i97, @b6 iB0 := slr_pl @iA0, @b7 iB1 := slr_pl @iA1, @b7 iB2 := slr_pl @iA2, @b7 iB3 := slr_pl @iA3, @b7 iB4 := slr_pl @iA4, @b7 iB5 := slr_pl @iA5, @b7 iB6 := slr_pl @iA6, @b7 iB7 := slr_pl @iA7, @b7 wr_q @iB0, c wr_q @iB1, c+8 wr_q @iB2, c+16 wr_q @iB3, c+24 wr_q @iB4, c+32 wr_q @iB5, c+40 wr_q @iB6, c+48 wr_q @iB7, c+56 complete
イーサリアム
もちろん、ベンチマークは優れていますが、特定のタスクがあります。計算のアクセラレータを作成することです。実際のタスクをどのように処理するかを知ることは素晴らしいことです。 マイニングアルゴリズムはさまざまなデバイスで実行されるため、比較のベンチマークとして機能するため、最新の暗号通貨はこのような検証に最適です。 イーサリアムと、マイニングデバイスで直接実行されるEthashアルゴリズムから始めました。
イーサリアムの選択は、次の考慮事項によるものでした。 ご存知のように、ビットコインなどのアルゴリズムは専用のASICチップによって非常に効率的に実装されているため、ビットコインとそのクローンをマイニングするためのプロセッサまたはビデオカードの使用は、低パフォーマンスと高電力消費のために経済的に不利になります。 鉱夫のコミュニティは、この状況から逃れようとして、他のアルゴリズム原理に基づいて暗号通貨を開発し、マイニングに汎用プロセッサーまたはビデオカードを使用するアルゴリズムの開発に焦点を当てています。 この傾向は今後も続く可能性があります。 イーサリアムは、このアプローチに基づいた最も有名な暗号通貨です。 イーサリアムをマイニングするための主なツールはビデオカードです。これは、効率(ハッシュレート/ TDP)の点で、汎用プロセッサよりも(数回)先行しています。
Ethashは、いわゆるメモリバウンドアルゴリズムです。 その計算時間は、計算自体の速度ではなく、主にメモリの量と速度によって制限されます。 イーサリアムマイニングでは、ビデオカードが最適ですが、多くの操作を同時に実行する能力はあまり役に立ちません。また、 この記事で明らかに示されているRAMの速度に依存しています 。 そこから、アルゴリズムの動作を示す写真を撮って、これが起こる理由を説明できます。
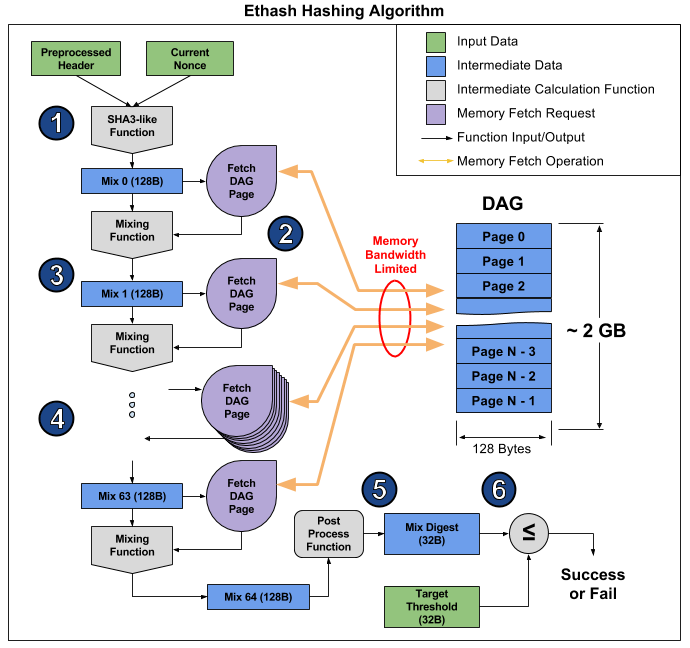
この記事ではアルゴリズムを6つのポイントに分けていますが、さらに明確にするために3つの段階を区別できます。
- 開始:元の128バイトのMix 0(ポイント1)を計算するSHA-3(512)
- 次の128バイトを読み取り、ミキシング機能を介して前のバイトと混合し、合計8キロバイトになるように、Mix配列を64倍再計算します(段落2〜4)
- 結果の確定と検証
RAMからランダムな128バイトを読み取るには、予想よりはるかに時間がかかります。 2048台のコンピューティングデバイスと最大メモリ帯域幅211.2 GB / sのMSI RX 470グラフィックカードを使用する場合、各デバイスに装備するには1 /(211.2 GB /(128 b * 2048))= 1241 ns、または約1496が必要です所定の周波数でサイクルします。 ミキシング関数のサイズを考えると、受信した情報を再計算するよりもビデオカードのメモリを読み取るのに数倍時間がかかると想定できます。 その結果、アルゴリズムのステージ2には多くの時間がかかり、ステージ1および3よりも多くの時間がかかります(主にSHA-3で)。 このビデオカードのハッシュレートを見ることができます:理論上の26.375メガシャシー(メモリ帯域幅によってのみ制限)対実際の24メガシャシー/秒、つまり、ステージ1と3は10%の時間しかかかりません。
S1では、16個のマルチセルすべてが並行して異なるコードで動作できます。 さらに、8つのマルチセル用の1つのチャネルに沿って、デュアルチャネルRAMがインストールされます。 Ethashアルゴリズムのステージ2での計画は次のとおりです。1つのマルチセルがメモリから128バイトを読み取り、それらの再カウントを開始し、次に次のマルチセルがメモリを読み取り、再カウントします。 1つのマルチセルは、128バイトのメモリを読み取った後、配列を再計算するために7 * [128バイトの読み取り時間]を持っています。 このような読み取りには16サイクル、つまり 再集計のために112の測定が行われます。 ミキシング関数の計算にはほぼ同じクロックサイクルがかかるため、S1はメモリ帯域幅とプロセッサパフォーマンスの理想的な比率に近くなります。 2番目の段階では時間が無駄にならないため、アルゴリズムの残りの部分は、パフォーマンスに実際に影響するため、可能な限り最適化する必要があります。
SHA-3(Keccak)の計算速度を評価するために、C言語プログラムが開発およびテストされ、それに基づいてアセンブラーでの最適なバージョンが現在作成されています。評価プログラミングは、1つのマルチセルが1550クロックサイクルでSHA-3(ケッカ)計算を実行することを示しています。したがって、1つのマルチセルで1つのハッシュを計算するための合計時間は、1550 + 64 *(16 + 112)= 9742サイクルになります。1.6 GHzの周波数と16個の並列マルチセルで、プロセッサのハッシュレートは2.6 MHash / sになります。
| 加速器 | MultiClet S1 | NVIDIA GeForce GTX 980 Ti | Radeon RX 470 | Radeon RX Vega 64 | NVIDIA GeForce GTX 1060 | NVIDIA GeForce GTX 1080 Ti |
|---|---|---|---|---|---|---|
| 価格 | 650ドル | 180ドル | 500ドル | 300ドル | 700ドル | |
| ハッシュレート | 2.6 MHash / s | 21.6 MHash / s | 25.8 MHash / s | 43.5 MHash / s | 25 MHash / s | 55 MHash / s |
| TDP | 6 W | 250 W | 120 W | 295 W | 120 W | 250 W |
| ハッシュレート/ TDP | 0.43 | 0.09 | 0.22 | 0.15 | 0.22 | 0.21 |
| プロセス技術 | 28 nm | 28 nm | 14 nm | 14 nm | 16 nm | 16 nm |
MultiClet S1をマイニングツールとして使用する場合、20個以上のプロセッサを実際にボードにインストールできます。この場合、このようなボードのハッシュレートは既存のビデオカードのハッシュレートと同じかそれよりも高くなりますが、S1を搭載したボードの消費電力は、16および14 nmの地形標準を備えたビデオカードの消費電力よりも半分になります。
結論として、現在の主なタスクは、マルチセルラー暗号通貨マイナーおよびスーパーコンピューターマイナー向けのマルチプロセッサーボードの製造であると言わなければなりません。消費電力とアーキテクチャが小さいため、任意のコンピューティングに適した競争力が実現する予定です。
プロセッサはまだ開発中ですが、アセンブリ言語でプログラミングを開始したり、コンパイラの現在のバージョンを評価したりできます。アセンブラー、リンカー、コンパイラー、および機能モデルを含む最小限のSDKがすでにあり、それらを使用してプログラムを開始およびテストできます。