
私はOdnoklassnikiプラットフォームのチームで働いており、今日は音楽配信サービスのアーキテクチャ、設計、実装の詳細についてお話します。
この記事は、 Joker 2018でのレポートの転写です。
いくつかの統計
まず、OKについて少し説明します。 これは、7000万人以上のユーザーが使用している巨大なサービスです。 4つのデータセンターにある7千台の車がサービスを提供しています。 最近、多くのCDNサイトを考慮せずに2 Tb / sでトラフィックマークを突破しました。 ハードウェアを最大限に活用します。最も負荷の高いサービスは、クアッドコアノードからの1秒あたり最大100,000のリクエストを処理します。 さらに、ほとんどすべてのサービスはJavaで記述されています。
OKには多くのセクションがあり、最も人気のあるセクションの1つは「音楽」です。 その中で、ユーザーはトラックをアップロードし、異なる品質の音楽を購入およびダウンロードできます。 このセクションには、素晴らしいカタログ、推奨システム、ラジオなどがあります。 しかし、サービスの主な目的はもちろん音楽を演奏することです。
音楽配信会社は、ユーザープレーヤーやモバイルアプリケーションにデータを転送する責任があります。 musicd.mycdn.meドメインへのリクエストを見ると、Webインスペクターでキャッチできます。 ディストリビューターAPIは非常に単純です。
GET
HTTP要求に応答し、要求されたトラック範囲を発行します。
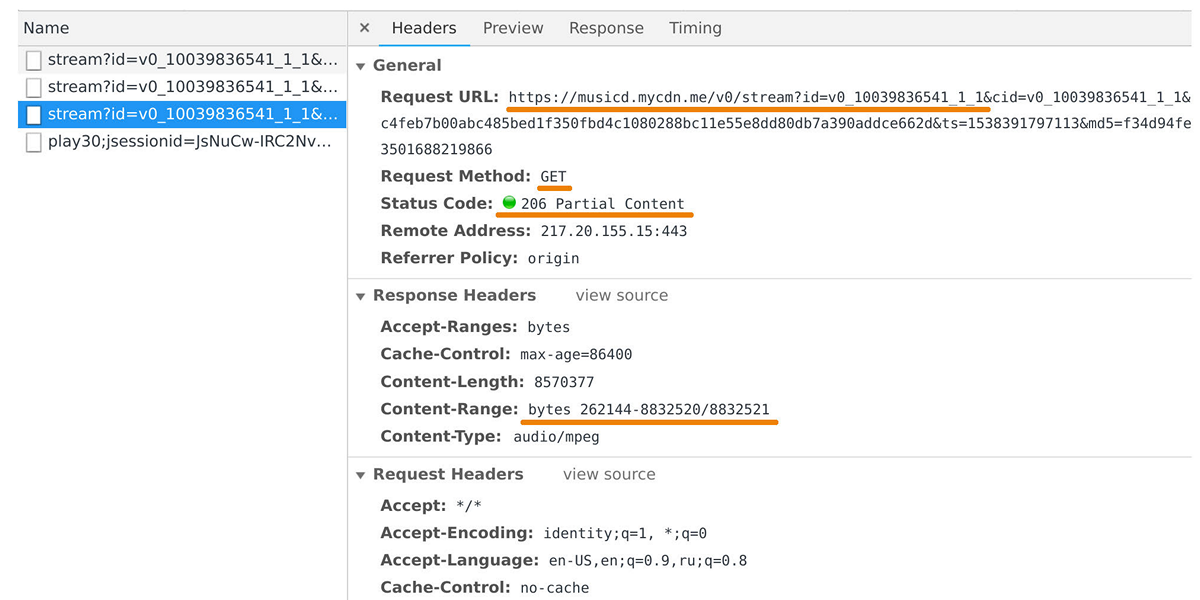
ピーク時には、50万の接続で負荷が100 Gb / sに達します。 実際、音楽ディストリビューターは内部トラックリポジトリの前にあるキャッシュフロントエンドであり、 One Blob StorageとOne Cold Storageに基づいており、ペタバイトのデータが含まれています。
キャッシングについて説明したので、再生統計を見てみましょう。 発音されたTOPが表示されます。
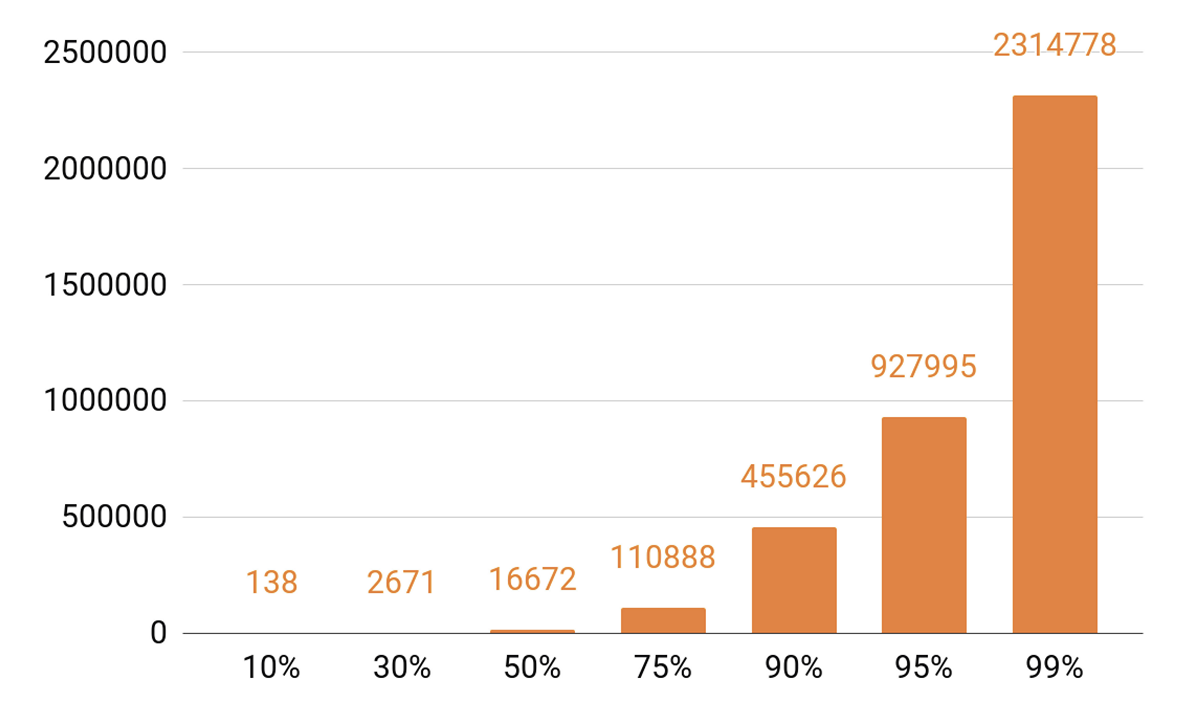
約140トラックが1日のすべての再生の10%をカバーしています。 キャッシングサーバーに少なくとも90%のキャッシュヒットを持たせたい場合は、50万トラックを入れる必要があります。 95%-ほぼ100万トラック。
ディストリビューターの要件
ディストリビューターの次のバージョンを開発するとき、どのような目標を設定しましたか?
1つのノードで10万の接続を保持できるようにしたかったのです。 そして、これらは遅いクライアント接続です:さまざまな速度のネットワーク上のブラウザとモバイルアプリケーションの束。 同時に、サービスは、すべてのシステムと同様に、スケーラブルでフォールトトレラントでなければなりません。
まず、サービスの人気の高まりに対応し、より多くのトラフィックを提供できるようにするために、クラスターの帯域幅を拡大する必要があります。 また、キャッシュヒットとトラックのストレージに分類されるリクエストの割合が直接依存するため、クラスターキャッシュの合計容量をスケーリングできる必要もあります。
今日では、分散システムを水平に拡張できる、つまりマシンとデータセンターを追加できることが必要です。 しかし、垂直スケーリングも実装したいと考えました。 典型的な最新のサーバーには、56個のコア、0.5〜1 TBのRAM、10または40 Gbのネットワークインターフェイス、1ダースのSSDディスクが含まれています。
水平方向のスケーラビリティについて言えば、興味深い効果が生じます。数千のサーバーと数万のディスクがある場合、何かが絶えず壊れます。 ディスク障害は日常的なものであり、週に20〜30個ずつ変更します。 また、サーバーの故障は誰も驚かず、1日2〜3台の車が交換されます。 また、データセンターの障害にも対処する必要がありました。たとえば、2018年には3つの障害がありましたが、これはおそらく最後ではありません。
なぜ私はこれすべてですか? システムを設計するとき、遅かれ早かれ壊れてしまうことを知っています。 したがって、すべてのシステムコンポーネントの障害シナリオを常に慎重に調査します。 障害に対処する主な方法は、データ複製を使用したバックアップです。データの複数のコピーが異なるノードに保存されます。
ネットワーク帯域幅も予約しています。 これは、システムのコンポーネントに障害が発生した場合、他のコンポーネントの負荷が崩壊することを許可できないため、重要です。
バランス調整
まず、データセンター間でユーザークエリのバランスを取る方法を学習し、それを自動的に行う必要があります。 これは、ネットワーク作業を行う必要がある場合、またはデータセンターに障害が発生した場合に使用します。 しかし、データセンター内でもバランスが必要です。 また、ノード間でランダムにリクエストを分散するのではなく、重みを付けたいと考えています。 たとえば、サービスの新しいバージョンをアップロードし、新しいノードをローテーションにスムーズに入力したい場合。 ストレスは、ストレステスト中にも非常に役立ちます。ノードの機能の制限を理解するために、ノードに重みを増やし、より大きな負荷をかけます。 また、ノードに負荷がかかったときに障害が発生すると、バランスメカニズムを使用して、ウェイトをすばやくゼロにし、回転から削除します。
ユーザーからノードへのリクエストパスはどのように見えますか?これにより、バランスを考慮したデータが返されますか?

ユーザーはWebサイトまたはモバイルアプリケーションを介してログインし、トラックURLを受け取ります。
musicd.mycdn.me/v0/stream?id=...
URLのホスト名からIPアドレスを取得するために、クライアントは、すべてのデータセンターとCDNサイトを知っているGSLB DNSに接続します。 GSLB DNSは、データセンターの1つのバランサーのIPアドレスをクライアントに提供し、クライアントはそれとの接続を確立します。 バランサーは、データセンター内のすべてのノードとその重量を把握しています。 ユーザーに代わって、ノードの1つとの接続を確立します。 NFWareに基づいたL4バランサーを使用します 。 Nodaは、バランサーをバイパスして、ユーザーデータを直接提供します。 ディストリビューターのようなサービスでは、発信トラフィックは着信トラフィックよりも大幅に高くなります。
データセンターがクラッシュした場合、GSLB DNSはこれを検出し、ローテーションからすぐに削除します。このデータセンターのバランサーのIPアドレスをユーザーに提供することを停止します。 データセンター内のノードに障害が発生すると、その重みがリセットされ、データセンター内のバランサーはリクエストの送信を停止します。
次に、データセンター内のノードごとにトラックのバランスを取ることを検討してください。 データセンターは独立した自律的なユニットと見なされ、他のすべてが死んだとしても、それぞれが生きて機能します。 トラックは、負荷に歪みが生じないように、マシン全体で均等にバランスを取る必要があり、異なるノードに複製する必要があります。 1つのノードに障害が発生した場合、残りのノード間で負荷を均等に分散する必要があります。
この問題はさまざまな方法で解決できます 。 私たちは一貫したハッシュに落ち着きました。 トラック識別子のハッシュの可能な範囲全体をリングでラップすると、各トラックがこのリング上のポイントに表示されます。 その後、クラスター内のノード間でリング範囲をほぼ均等に分散します。 トラックを保存するノードは、トラックをリング上のポイントにハッシュし、時計回りに移動することにより選択されます。
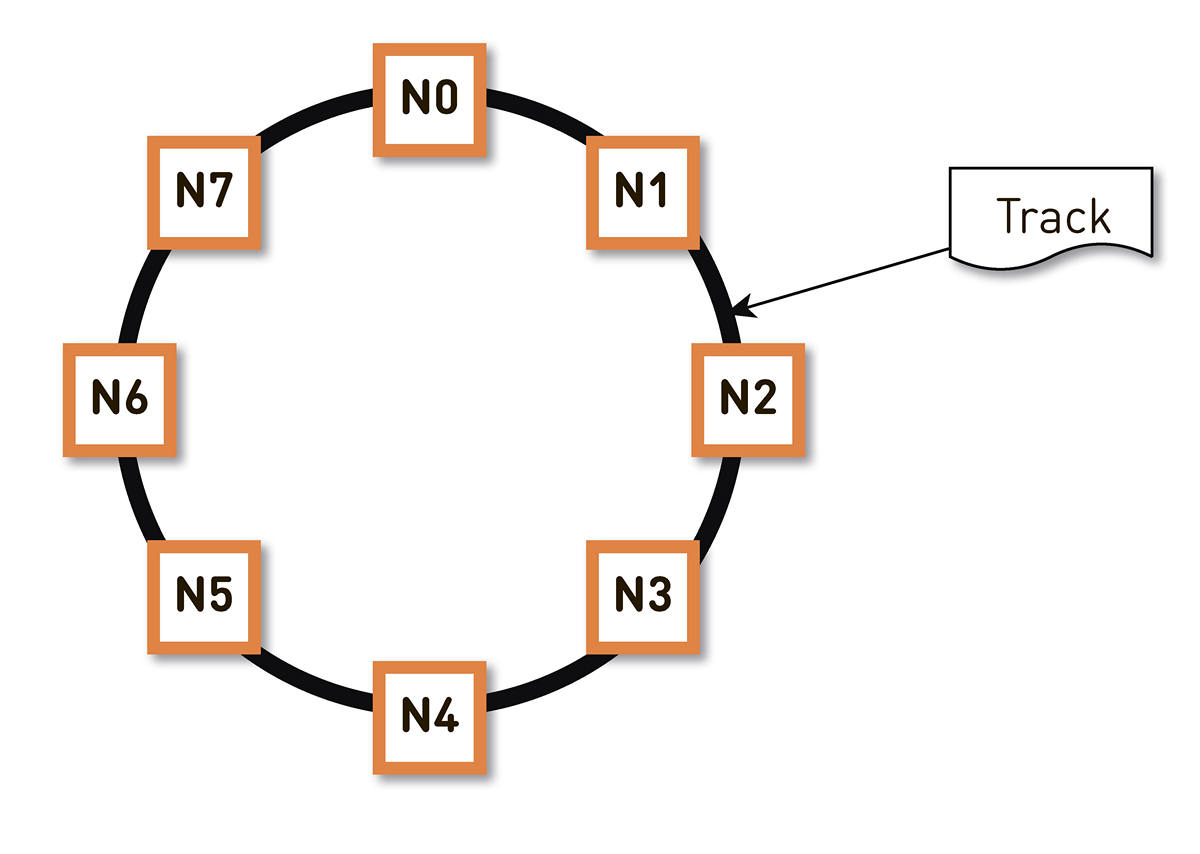
しかし、このようなスキームには欠点があります。たとえば、ノードN2に障害が発生した場合、その負荷全体がリング内の次のレプリカN3に落ちます。 そして、生産性に2倍のマージンがない場合(そしてこれが経済的に正当化されない場合)、おそらく、2番目のノードにも悪い時間があります。 高い確率でN3が発生し、負荷がN4に到達する、というように、リング全体にカスケード障害が発生します。
この問題は、レプリカの数を増やすと解決できますが、リング内のクラスターの合計有効容量は減少します。 したがって、そうしません。 同じ数のノードで、リングは、リングの周りにランダムに散らばっている非常に多くの範囲に分割されます。 トラックのレプリカは、上記のアルゴリズムに従って選択されます。

上記の例では、各ノードが2つの範囲を担当しています。 ノードの1つに障害が発生した場合、その負荷全体がリング内の次のノードにかかることはありませんが、クラスターの他の2つのノードに分散されます。
リングはアルゴリズムの小さなセットに基づいて計算され、各ノードで決定されます。 つまり、なんらかの設定には保存しません。 実稼働環境には数十万を超えるこれらの範囲があり、いずれかのノードで障害が発生した場合、負荷は他のすべての生きているノード間で完全に均等に分散されます。
一貫したハッシュを使用するこのようなシステムで、ユーザーへのリターントラックはどのように見えますか?
ユーザーは、L4バランサーを介してランダムノードに到達します。 バランサーはトポロジーについて何も知らないため、ノードの選択はランダムです。 ただし、クラスター内のすべてのレプリカはそれを認識しています。 要求を受信したノードは、要求されたトラックのレプリカであるかどうかを判別します。 そうでない場合は、レプリカの1つを使用してプロキシモードに切り替え、レプリカとの接続を確立し、ローカルストレージ内のデータを検索します。 トラックが存在しない場合、レプリカはトラックストアからトラックを取得し、ローカルストアに保存し、プロキシを提供します。プロキシはデータをユーザーにリダイレクトします。
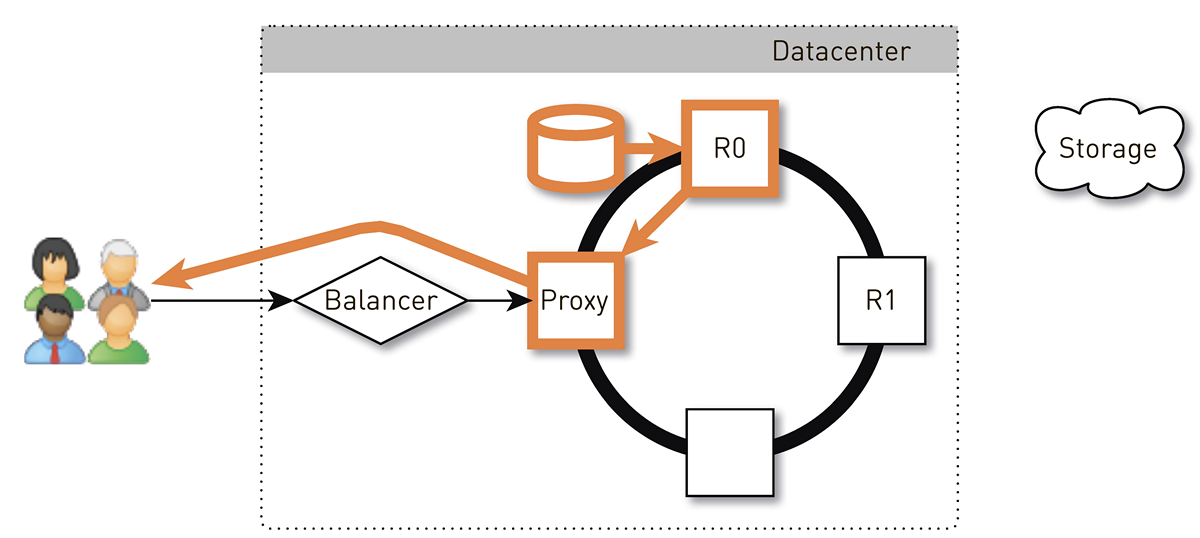
レプリカ内のディスクに障害が発生した場合、ストレージからのデータはユーザーに直接転送されます。 レプリカに障害が発生した場合、プロキシはこのトラックの他のすべてのレプリカを認識し、別のライブレプリカとの接続を確立して、そこからデータを受信します。 したがって、ユーザーがトラックを要求し、少なくとも1つのレプリカが生きている場合、応答を受け取ることを保証します。
ノードはどのように機能しますか?
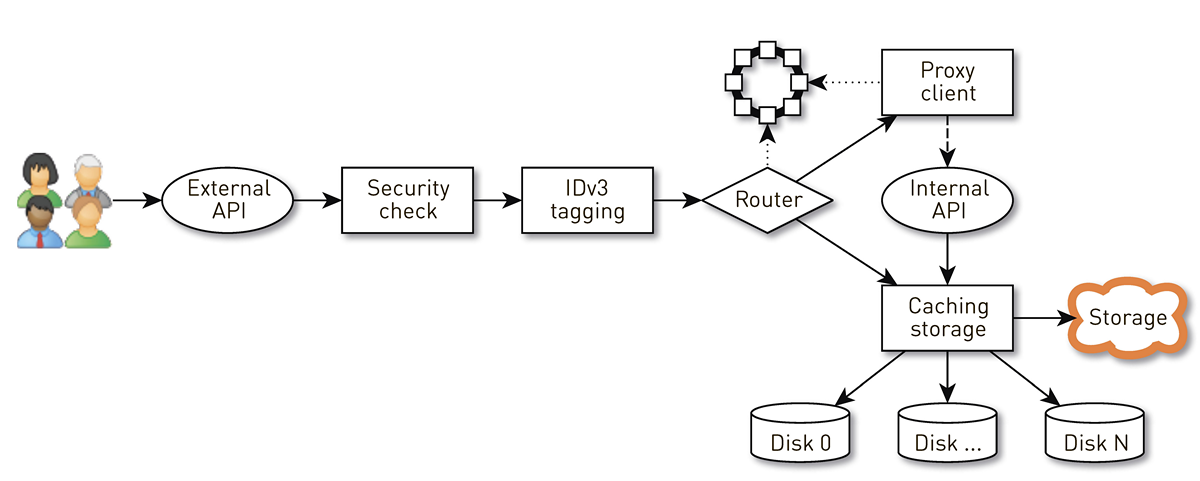
ノードは、ユーザーのリクエストが通過する一連のステージからのパイプラインです。 まず、リクエストは外部APIに送られます(すべてをHTTPS経由で送信します)。 次に、リクエストが検証されます-署名が検証されます。 次に、トラックの購入時など、必要に応じてIDv3タグが構築されます。 要求はルーティングステージに進み、クラスタートポロジに基づいて、データがどのように返されるかが決定されます。現在のノードはこのトラックのレプリカであるか、別のノードからプロキシになります。 2番目の場合、プロキシクライアントを介したノードは、署名を検証せずに、内部HTTP APIを介してレプリカへの接続を確立します。 レプリカは、ローカルストレージ内のデータを検索し、トラックを見つけると、ディスクからそれを提供します。 そうでない場合は、ストレージからトラックを引き出し、キャッシュして提供します。
ノード負荷
この構成で1つのノードが保持すべき負荷を推定しましょう。 それぞれ4つのノードを持つ3つのデータセンターを考えてみましょう。

サービス全体で120ギガビット/秒、つまりデータセンターあたり40ギガビット/秒を処理する必要があります。 ネットワーク作成者が操作を行った、または事故が発生し、DC1とDC3の2つのデータセンターがあったとします。 今、それらのそれぞれは60 Gbit / sを与える必要があります。 しかし、ここでいくつかの更新を展開するのは開発者次第でした。各データセンターには3つのライブノードが残っており、それぞれが20ギガビット/秒を提供する必要があります。
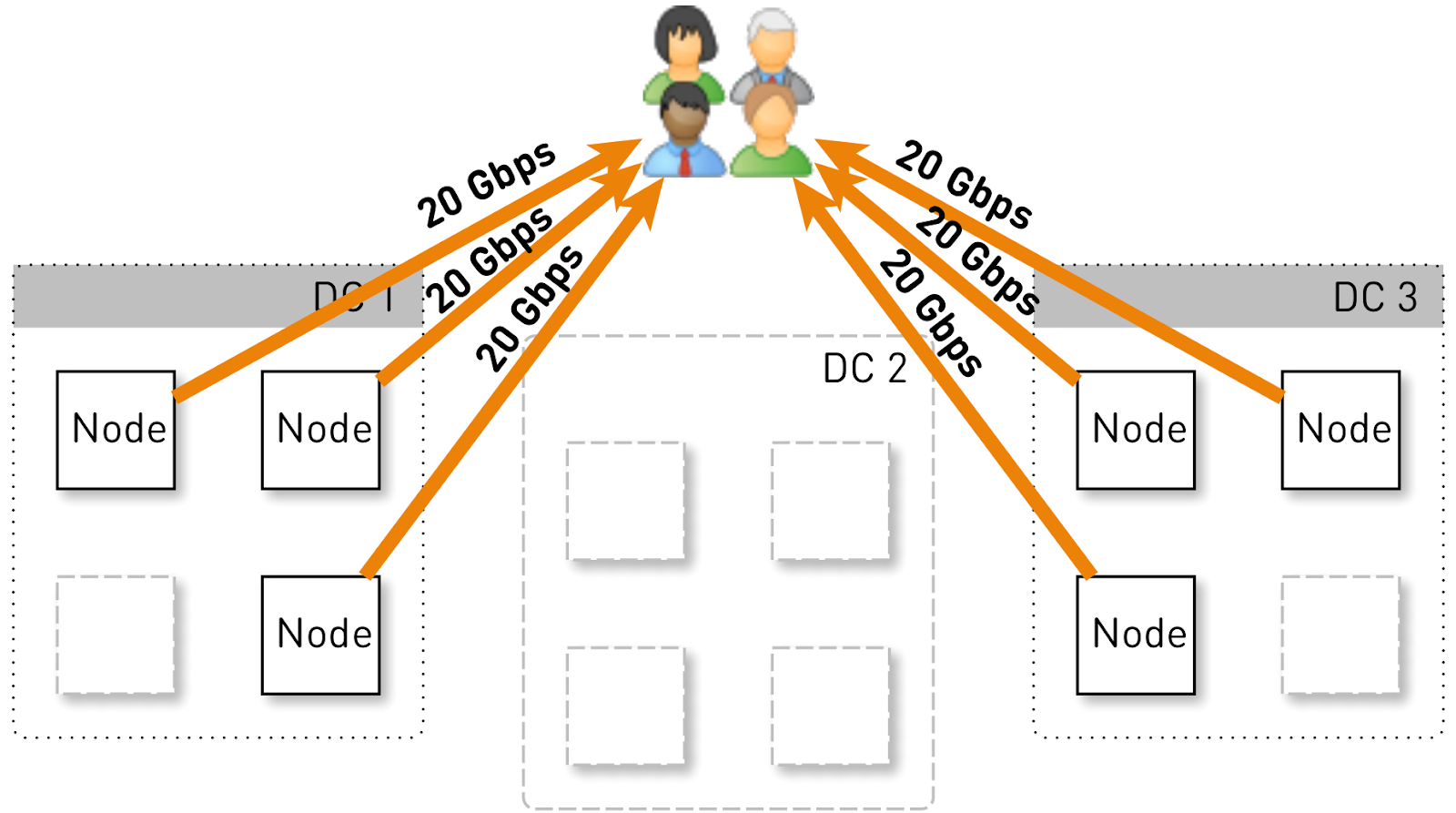
ただし、最初は各データセンターに4つのノードがありました。 そして、データセンターに2つのレプリカを格納すると、50%の確率で、リクエストを受信したノードはリクエストされたトラックのレプリカではなく、データをプロキシします。 つまり、データセンター内のトラフィックの半分がプロキシされます。
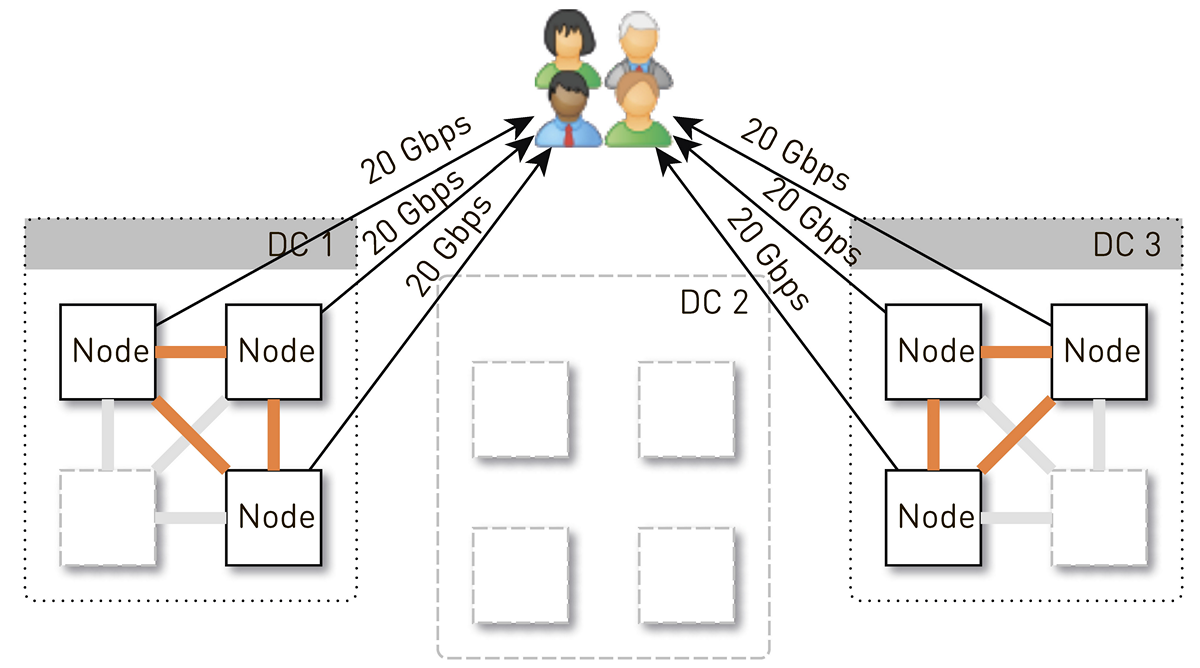
そのため、1つのノードでユーザーに20 Gb / sを与える必要があります。 これらのうち、10 Gb / sはデータセンター内の近隣から取得します。 ただし、このスキームは対称的です。ノードは同じ10 Gb / sをデータセンター内の近隣に提供します。 30 Gbit / sがノードから出ており、要求されたデータのレプリカであるため、そのうち20 Gbit / sが単独で処理されることがわかります。 さらに、データはディスクまたはRAMから送信されます。RAMには約5万個の「ホット」トラックがあります。 再生統計に基づいて、これによりディスクの負荷の60〜70%を削除でき、約8 Gb / sが残ります。 このスレッドは、1ダースのSSDを提供できます。
ノード上のデータストレージ
各トラックを別々のファイルに入れると、これらのファイルを管理するオーバーヘッドが膨大になります。 ノードを再起動し、ディスク上のデータをスキャンする場合でも、数十分ではないにしても数分かかります。
このスキームにはそれほど明白な制限はありません。 たとえば、最初からのみトラックをロードできます。 ユーザーが中央からの再生をリクエストし、キャッシュが失われた場合、トラックリポジトリから目的の場所にデータをロードするまで1バイトを送信することはできません。 さらに、たとえ3分で聴くのをやめた巨大なオーディオブックであっても、トラック全体を保存することしかできません。 それはまだディスク上の自重であり、高価なスペースを無駄にし、このノードのキャッシュヒットを減らします。
したがって、完全に異なる方法でそれを行います。これは、トラックを256 KBブロックに分割します。これはSSDのブロックサイズと相関関係があり、すでにこれらのブロックで動作しているためです。 1 TBのディスクには400万ブロックが含まれています。 ノード内の各ディスクは独立したストレージであり、各トラックのすべてのブロックはすべてのディスクに分散されます。
私たちはすぐにそのようなスキームに到達しませんでした。最初は、1つのトラックのすべてのブロックが1つのディスクに置かれました。 しかし、人気のあるトラックがディスクの1つにヒットすると、そのデータに対するすべての要求が1つのディスクに送られるため、ディスク間の負荷に深刻な歪みが生じました。 これを防ぐため、各トラックのブロックをすべてのディスクに分散し、負荷を分散しました。
さらに、RAMがたくさんあることを忘れませんが、Linuxにはすばらしいページキャッシュがあるため、セマンティックキャッシュを行わないことにしました。
ブロックをディスクに保存する方法は?
最初に、1つの巨大なXFSファイルをディスクサイズにして、すべてのブロックをその中に入れることにしました。 次に、ブロックデバイスを直接使用するというアイデアが浮上しました。 両方のオプションを実装して比較したところ、ブロックデバイスを直接操作する場合、記録が1.5倍速くなり、応答時間が2〜3倍短くなり、合計システム負荷が2倍低くなりました。
索引
ただし、ブロックを保存するだけでは不十分です。音楽トラックのブロックからディスク上のブロックへのインデックスを維持する必要があります。

非常にコンパクトであることが判明し、1つのインデックスエントリに必要なのは29バイトのみです。 10 TBのストレージの場合、インデックスは1 GBを少し上回ります。
ここには興味深い点があります。 このような各レコードには、トラック全体の合計サイズを保存する必要があります。 これは非正規化の典型的な例です。 その理由は、HTTP範囲応答の仕様に従って、リソースの合計サイズを返すとともに、Content-lengthヘッダーを形成する必要があるためです。 そうでなければ、すべてがさらにコンパクトになります。
インデックスには多くの要件を策定しました:迅速に(できればRAMに保存して)動作し、コンパクトでページキャッシュのスペースを占有しないようにします。 別のインデックスは永続的でなければなりません。 紛失すると、ディスク上のどの場所にどのトラックが保存されているかに関する情報が失われます。これはディスクのクリーニングに相当します。 そして、一般的には、長い間アクセスされていない古いブロックを何らかの形で置き換えて、より人気のあるトラックのためのスペースを作りたいです。 LRUクラウディングアウトポリシーを選択しました。ブロックは1分に1回クラウディングされ、ブロックの1%は無料になります。 もちろん、ノードごとに10万の接続があるため、インデックス構造はスレッドセーフでなければなりません。 これらすべての条件は、 one-nioオープンソースライブラリの
SharedMemoryFixedMap
によって理想的に満たされます。
tmpfs
にインデックスを配置しますが、すぐに動作しますが、微妙な違いがあります。 マシンが再起動すると、インデックスを含む
tmpfs
にあったすべてのものが失われます。 さらに、
sun.misc.Unsafe
プロセスがクラッシュした場合、インデックスがどの状態で残っているかは不明です。 したがって、私たちはそれを1時間に1回印象づけます。 しかし、これは十分ではありません。ブロック押し出しを使用するため、押し出しブロックに関する情報を書き込むWALをサポートする必要があります。 キャストとWALのブロックに関するエントリは、リカバリ中に何らかの方法でソートする必要があります。 このために、生成ブロックを使用します。 グローバルトランザクションカウンターの役割を果たし、インデックスが変更されるたびにインクリメントされます。 これがどのように機能するかの例を見てみましょう。
トラック番号1の2ブロックとトラック番号2の1ブロックの3つのエントリを持つインデックスを作成します。
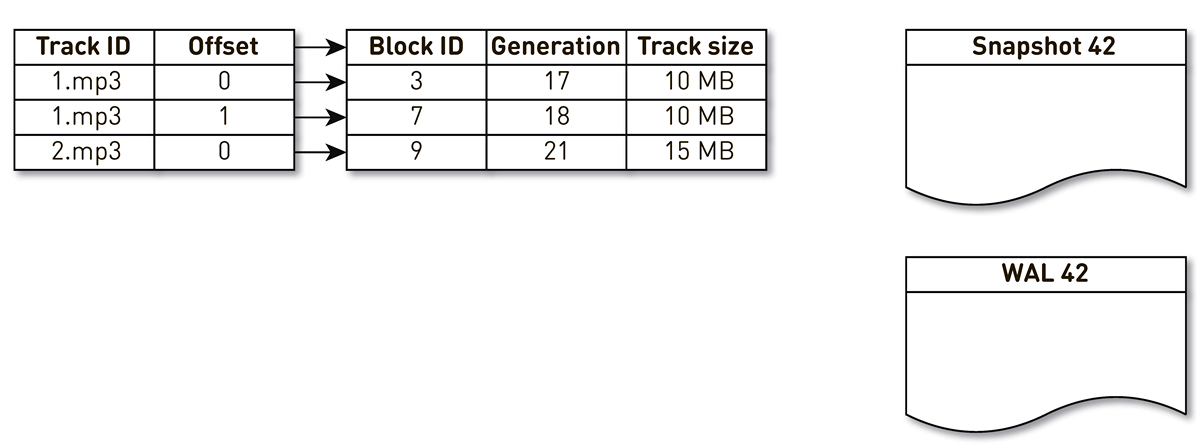
キャストを作成するストリームは、このインデックスによって目覚め、繰り返されます。最初と2番目のタプルはキャストに分類されます。 その後、クラウディングフローはインデックスにアクセスし、7番目のブロックが長時間アクセスされていないことを認識し、それを他の何かに使用することを決定します。 プロセスはブロックを強制的に削除し、WALにレコードを書き込みます。 彼はブロック9に到達し、長い間連絡を受けていないことを確認し、混雑しているとマークします。 ここでユーザーがシステムにアクセスすると、キャッシュミスが発生します-トラックが要求されますが、これはありません。 このトラックのブロックをリポジトリに保存し、ブロック9を上書きします。 この場合、世代がインクリメントされ、22に等しくなります。次に、作業を完了していない金型を作成するプロセスがアクティブになり、最後のレコードに到達して金型に書き込みます。 その結果、インデックスにはキャストとWALという2つのライブレコードがあります。
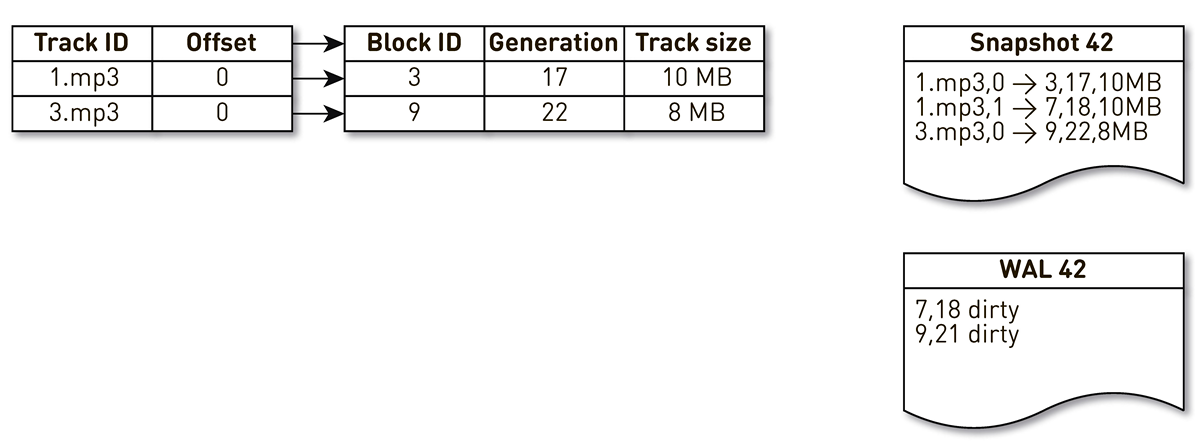
現在のノードが落ちると、次のようにインデックスの初期状態を復元します。 まず、WALをスキャンし、ダーティブロックマップを作成します。 カードは、このブロックが置き換えられたときのブロック番号から世代へのマッピングを保存します。

その後、マップをフィルターとして使用してキャストの繰り返しを開始します。 キャストの最初のレコードを見ると、ブロック番号3に関連しています。 彼は汚い人の間では言及されていません。つまり、彼は生きており、インデックスに入っています。 18世代でブロック番号7に到達しますが、ダーティブロックマップは、18世代でブロックが混み合っていることを示しています。 したがって、インデックスには含まれません。 22世代のブロック9の内容を記述する最後のレコードに到達します。 このブロックはダーティブロックマップで言及されていますが、以前に置き換えられました。 そのため、新しいデータに再利用され、インデックスに入ります。 目標が達成されました。
最適化
しかし、それだけではありません。深く掘り下げます。
ページキャッシュから始めましょう。 最初はそれを頼りにしていましたが、最初のバージョンの負荷テストの実行を開始したとき、ページキャッシュのヒット率が20%に達していないことがわかりました。 彼らは、問題を先読みすることを提案しました:ファイルを保存するのではなく、ブロックしますが、多くの接続を提供し、この構成では、ディスクの操作はランダムです。 順番に何も読むことはほとんどありません。 幸いなことに、Linuxには
posix_fadvise
呼び出しがあり、ファイル記述子をどのように使用するかをカーネルに伝えることができます。特に、
POSIX_FADV_RANDOM
フラグを渡すことで先読みする必要がないと言えます。 このシステムコールはone-nioを介して利用可能です。 動作中、キャッシュヒットは70〜80%です。ディスクからの物理的な読み取りの数は2倍以上減少し、HTTP応答の遅延は20%減少しました。
さらに進みましょう。サービスのヒープサイズはかなり大きくなります。プロセッサのTLBキャッシュの寿命を延ばすために、JavaプロセスにHuge Pagesを含めることにしました。その結果、ガベージコレクション時間で顕著な利益を得ました(GC時間/セーフポイント合計時間は20〜30%短縮されました)。カーネルの読み込みはより均一になりましたが、HTTPレイテンシグラフへの影響はありませんでした。
事件
サービスの開始後すぐに、唯一の(これまでの)インシデントが発生しました。
営業日の終わりのある夕方、音楽の演奏に関する苦情が支持を集めました。ユーザーはお気に入りのトラックを含めると書きましたが、数秒ごとに他の人や他の人から奇妙な音楽を聞いたので、プレイヤーはお気に入りのトラックを再生したと言いました。かなり迅速に検索サークルを1台の車に絞り込みました。ログから、最近再起動されたことがわかりました。簡単にするために、ブロックの内容を記述する2つのディスクとインデックスがありました。ある指標では、Daft Punkトラックの4番目のブロックはsdcディスクのブロック番号2にあり、Stas Mikhailovトラックのゼロブロックはsddディスクのゼロブロックにあります。
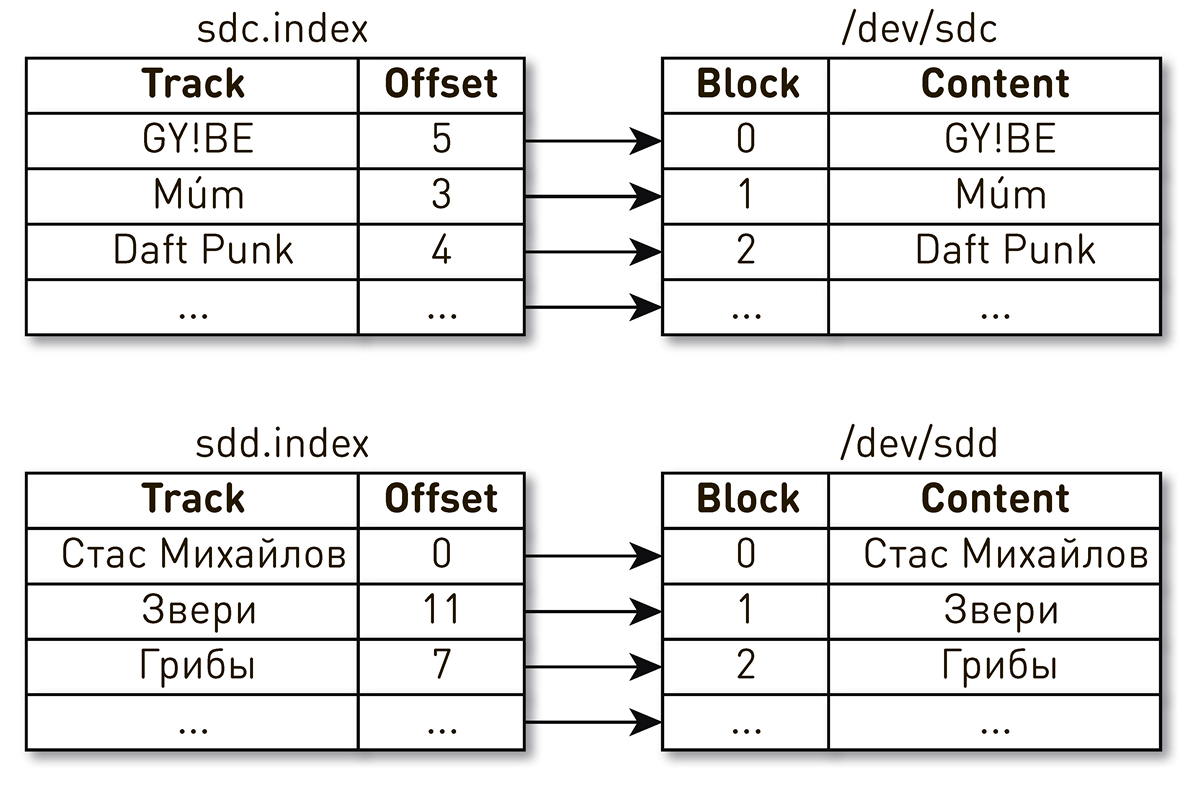
マシンを再起動すると、ドライブ名が場所を変更し、その後の結果がすべて変わることがわかりました。この問題はLinuxでよく知られています。サーバーに複数のディスクコントローラーがある場合、ディスクの命名順序は保証されません。

修正は簡単であることが判明しました。ディスクには、いくつかの異なるタイプの永続IDがあります。ディスクのシリアル番号に基づいてWWNを使用し、それらを使用してインデックス、スナップショット、およびWALを識別します。これはディスク自体のシャッフルを除外するものではありませんが、シャッフル方法に関係なく、ディスク上のインデックスマッピングに違反することはなく、常に正しいデータを提供します。
インシデント分析
ユーザー要求は多くの段階を経てノードの境界を越えるため、このような分散システムの問題の分析は困難です。 CDNの場合、アップストリームがホームデータセンターであるため、すべてがさらに複雑になります。そのような希望は非常に多くあります。さらに、システムは数十万のユーザー接続に対応しています。特定のユーザーからのリクエストの処理に問題がある段階を理解することは非常に困難です。
私たちは生活を楽にします。ログイン時に、Open TracingおよびZipkinに似たタグですべてのリクエストをマークします。タグには、ユーザーの識別子、リクエスト、リクエストされたトラックが含まれます。このタグは、現在の接続に関連するすべてのデータと要求とともにパイプライン内で送信され、ノード間ではHTTPヘッダーとして送信され、受信側によって復元されます。問題に対処する必要がある場合は、デバッグを有効にし、タグをログに記録し、特定のユーザーまたはトラックに関連するすべてのレコードを見つけ、集約し、クラスター全体でリクエストが処理された方法を見つけます。
データを送信する
ディスクからソケットにデータを送信するための一般的なスキームを検討してください。複雑なことはないようです。バッファを選択し、ディスクからバッファに読み込み、バッファをソケットに送信します。
ByteBuffer buffer = ByteBuffer.allocate(size); int count = fileChannel.read(buffer, position); if (count <= 0) { // ... } buffer.flip(); socketChannel.write(buffer);
このアプローチの問題の1つは、2つの隠されたデータコピーがここに隠されていることです。
-
FileChannel.read()
kernel space user space; -
SocketChannel.write()
, user space kernel space.
幸いなことに、Linuxには、
sendfile()
ユーザースペースへのコピーをバイパスして、ファイルから特定のオフセットからソケットにデータを直接送信するようカーネルに要求できる呼び出しがあります。そしてもちろん、この呼び出しはone-nioを通じて利用できます。負荷テストでは、1つのノードでユーザートラフィックを開始し、データのみを送信する隣接ノードからプロキシを強制
sendfile()
しました-10 Gb / sのプロセッサ負荷は使用時
sendfile()
に0 に近かった
が、ユーザースペースSSLソケットの場合は、できません活用
sendfile()
して、ファイルからデータをバッファ経由で送信する以外に選択肢はありません。そして、ここで別の驚きがあります。ソース
SocketChannel
とを掘り下げる場合
FileChannel
、または非同期プロファイラーを使用する場合そしてこのように、戻りデータの過程でpoprofilirovatシステムは、遅かれ早かれ、あなたがクラスに取得
sun.nio.ch.IOUtil
沸騰するすべてのコールダウンする
read()
と、
write()
これらのチャネル上。そのようなコードはそこに隠されています。
ByteBuffer bb = Util.getTemporaryDirectBuffer(dst.remaining()); try { int n = readIntoNativeBuffer(fd, bb, position, nd); bb.flip(); if (n > 0) dst.put(bb); return n; } finally { Util.offerFirstTemporaryDirectBuffer(bb); }
これはネイティブバッファのプールです。heapのファイルから読み取る場合
ByteBuffer
、標準ライブラリは最初にこのプールからバッファーを取得し、そこにデータを読み取り、それをヒープにコピーし
ByteBuffer
、ネイティブバッファーをプールに返します。ソケットに書き込むとき、同じことが起こります。
物議を醸すスキーム。ここでone-nioが再び助けになります。アロケーターを作成します
MallocMT
-実際、これはメモリープールです。SSLがあり、バッファを介してデータを送信する必要がある場合は、Javaヒープの外側のバッファを選択してラップし
ByteBuffer
、
FileChannel
このバッファから余分なコピーなしで読み取り、ソケットに書き込みます。そして、バッファをアロケータに返します。
final Allocator allocator = new MallocMT(size, concurrency); int write(Socket socket) { if (socket.getSslContext() != null) { long address = allocator.malloc(size); ByteBuffer buf = DirectMemory.wrap(address, size); int available = channel.read(buf, offset); socket.writeRaw(address, available, flags);
ノードあたり100,000接続
しかし、システムの成功は、低レベルでの合理的な実装によって保証されません。ここには別の問題があります。各ノードのコンベアは、最大10万の同時接続に対応します。そのようなシステムで計算を整理する方法は?
最初に頭に浮かぶのは、クライアントまたは接続ごとに実行スレッドを作成することです。その中で、パイプラインステージを次々に実行します。必要に応じてブロックし、次に進みます。しかし、このようなスキームでは、ディストリビューターについて話しているため、多くのフローがあるため、コンテキストの切り替えとフローのスタックのコストは過剰になります。したがって、私たちは他の方法で行った。
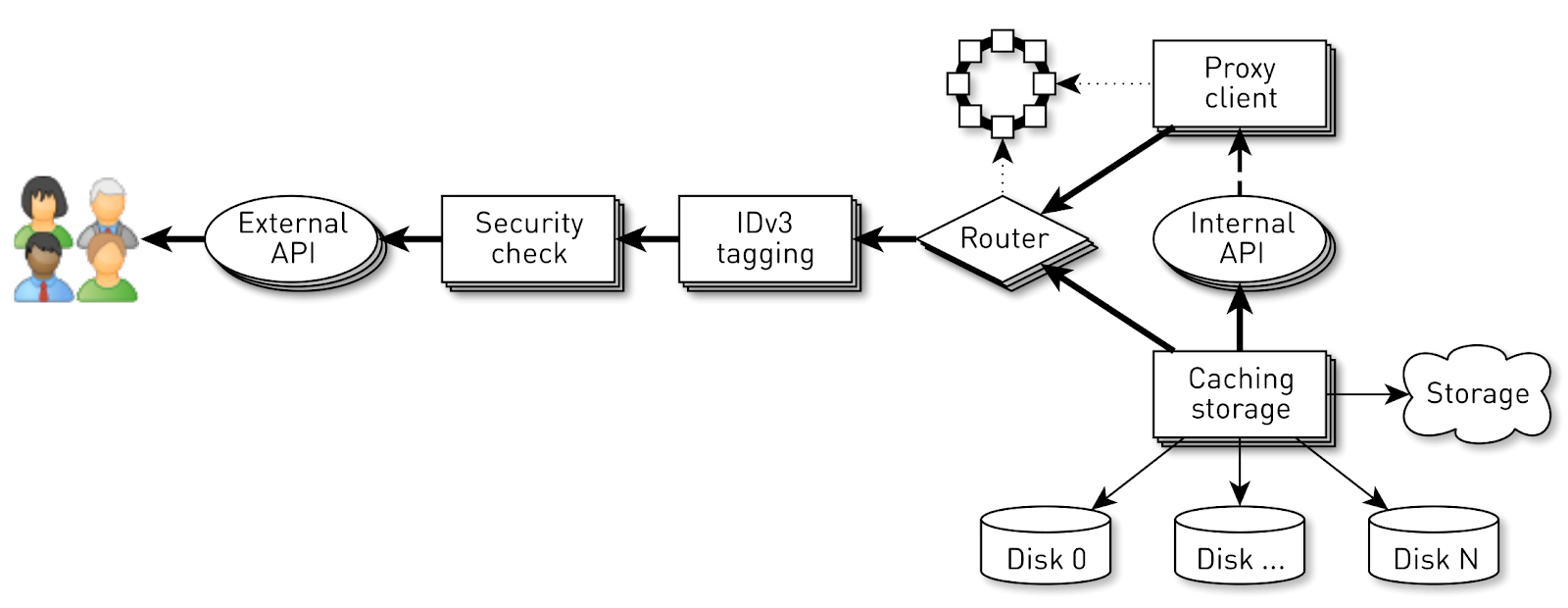
各接続に対して論理パイプラインが作成されます。これは、非同期的に相互作用するステージで構成されます。各ステージには、着信リクエストを保存する順番があります。ステージの実行には、小さな共通スレッドプールが使用されます。要求キューからのメッセージを処理する必要がある場合、プールからストリームを取得し、メッセージを処理して、ストリームをプールに返します。このスキームでは、データがストレージからクライアントにプッシュされます。
しかし、そのようなスキームには欠陥がないわけではありません。バックエンドはユーザー接続よりもはるかに高速です。データがパイプラインを通過するとき、最も遅い段階で蓄積されます。クライアント接続ソケットにブロックを書き込む段階で。遅かれ早かれ、これはシステムの崩壊につながります。これらの段階でキューを制限しようとすると、チェーン内のユーザーのソケットへのパイプラインがブロックされるため、すべてが即座に停止します。また、共有スレッドプールを使用しているため、その中のすべてのスレッドをブロックします。背圧が必要です。
これを行うために、ジェットストリームを使用しました。このアプローチの本質は、サブスクライバーがパブリッシャーからのデータレートをデマンドを使用して制御することです。需要とは、サブスクライバーが処理する準備ができているデータの量と、既に通知されている以前の需要を意味します。パブリッシャーにはデータを送信する権利がありますが、現時点で累積された総需要から送信済みのデータを差し引いたものを超えることはできません。
したがって、システムはプッシュモードとプルモードを動的に切り替えます。プッシュモードでは、サブスクライバーはパブリッシャーよりも高速です。つまり、パブリッシャーはサブスクライバーからの満足されない要求を常に持っていますが、データはありません。データが表示されるとすぐに、彼はすぐにそれらをサブスクライバーに送信します。プルモードは、パブリッシャーがサブスクライバーより速い場合に発生します。つまり、出版社はデータを送信しても問題ありません。需要のみがゼロです。サブスクライバーがもう少し処理する準備ができたと言ったらすぐに、パブリッシャーはすぐにデータの一部を要求の一部として送信します。
コンベアはジェットストリームに変わります。各ステージは、前のステージではパブリッシャーになり、次のステージではサブスクライバーになります。
ジェットストリームのインターフェイスは非常にシンプルに見えます。
Publisher
署名しましょう
Subscriber
、および彼は4つのハンドラーのみを実装する必要があります。
interface Publisher<T> { void subscribe(Subscriber<? super T> s); } interface Subscriber<T> { void onSubscribe(Subscription s); void onNext(T t); void onError(Throwable t); void onComplete(); } interface Subscription { void request(long n); void cancel(); }
Subscription
需要を通知し、購読を解除できます。どこも簡単です。
データの要素として、バイト配列は渡さず、チャンクなどの抽象化を渡します。可能であれば、データをヒープにドラッグしないためにこれを行います。チャンクは、データの読み取り
ByteBuffer
、ソケットへの書き込み、またはファイルへの書き込みのみを許可する、非常に限られたインターフェイスを持つデータリンクです。
interface Chunk { int read(ByteBuffer dst); int write(Socket socket); void write(FileChannel channel, long offset); }
チャンクには多くの実装があります。
- キャッシュヒットの場合やディスクからデータを転送するときに使用される最も一般的なものは、topの実装
RandomAccessFile
です。チャンクには、ファイルへのリンク、このファイルのオフセット、およびデータのサイズのみが含まれます。パイプライン全体を通り、ユーザー接続ソケットに到達し、そこでコールに変わりますsendfile()
。つまり、メモリはまったく消費されません。 - cache miss : . , — , , — .
- , - heap.
ByteBuffer
.
このAPIは単純であるにもかかわらず、仕様ではスレッドセーフであり、ほとんどのメソッドは非ブロッキングである必要があります。私たちは、触発され精神型付き俳優モデル、パスを選択した例から公式リポジトリ のジェットストリーム。メソッド呼び出しを非ブロッキングにするには、メソッドを呼び出すときに、すべてのパラメーターを取得し、メッセージにラップし、実行のためにキューに入れて、制御を返します。キューからのメッセージは厳密に順番に処理されます。
同期は行われません。コードはシンプルで簡単です。
状態は3つのフィールドでのみ説明されています。各パブリッシャーまたはサブスクライバーには、着信メッセージが収集されるメールボックスと、このタイプのすべてのステージ間で分割されるエグゼキューターがあります。
連続した目覚めの前に起こる。
呼び出しはメッセージに変わります:
方法
:
方法
:
方法
:
AtomicBoolean
連続した目覚めの前に起こる。
// Incoming messages final Queue<M> mailbox; // Message processing works here final Executor executor; // To ensure HB relationship between runs final AtomicBoolean on = new AtomicBoolean();
呼び出しはメッセージに変わります:
@Override void request(final long n) { enqueue(new Request(n)); } void enqueue(final M message) { mailbox.offer(message); tryScheduleToExecute(); }
方法
tryScheduleToExecute()
:
if (on.compareAndSet(false, true)) { try { executor.execute(this); } catch (Exception e) { ... } }
方法
run()
:
if (on.get()) try { dequeueAndProcess(); } finally { on.set(false); if (!messages.isEmpty()) { tryScheduleToExecute(); } } }
方法
dequeueAndProcess()
:
M message; while ((message = mailbox.poll()) != null) { // Pattern match if (message instanceof Request) { doRequest(((Request) message).n); } else { … } }
完全にノンブロッキングの実装ができました。コードシンプルかつ一貫性のある、なしに
volatile
、
Atomic*
競合など。システム全体では、100,000の接続を処理するために合計200のスレッドがあります。
最後に
実稼働では、12台のマシンがありますが、帯域幅には2倍以上のマージンがあります。通常モードの各マシンは、数十万の接続を通じて最大10ギガビット/秒を提供します。スケーラビリティと復元力を提供しました。すべてがJavaとone-nioで書かれています。
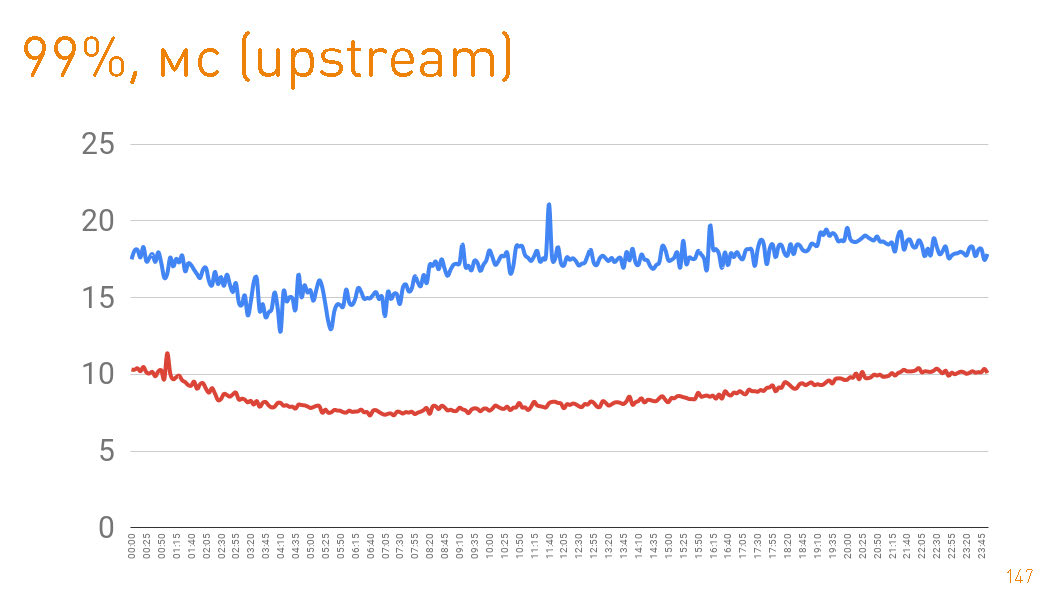
これは、サーバー側からユーザーに与えられる最初のバイトまでのグラフです。 20ミリ秒未満の99パーセンタイル。青いグラフは、ユーザーへのHTTPSデータの戻り値です。赤いグラフは、
sendfile()
HTTP を介したレプリカからプロキシへのデータの戻り値です。
実際、実稼働環境でのキャッシュヒットは97%であるため、グラフはトラックリポジトリのレイテンシを示しています。キャッシュミスの場合はそこからデータを取得しますが、これもペタバイトのデータを考慮すると悪くありません。
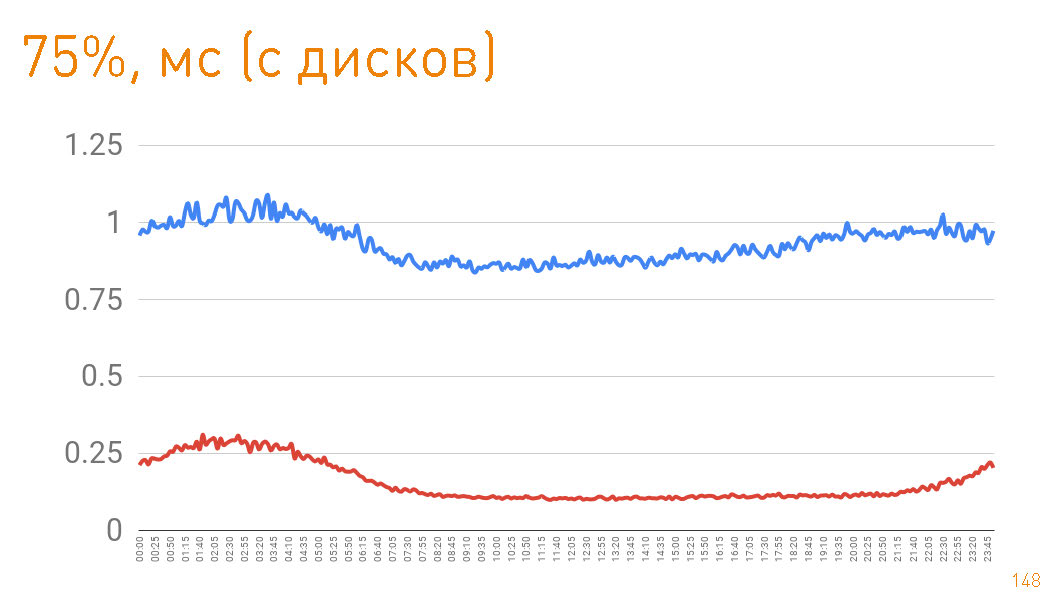
ディスクから戻るときに75パーセンタイルを見ると、1ミリ秒後に最初のバイトがユーザーに飛んでいます。クラスター内のレプリカはさらに高速で通信します-300μsの責任があります。つまり0.7ミリ秒はプロキシのコストです。
この記事では、高速性と優れたフォールトトレランスの両方を備えたスケーラブルで負荷の高いシステムを構築する方法を示しました。成功したことを願っています。