
雪片、ロマネスコキャベツ、ヒトデ、稲妻、木に共通するものは何ですか? すぐにそう言うわけではありませんが、数学的な観点から見ると、これらすべてのオブジェクトには共通の特徴であるフラクタル性があります。 数学の観点では、私たちの世界のすべてが「科学の女王」の法則に従っています。 あらゆる現象、プロセス、またはオブジェクトは、数学的な形式で表現できるため、いわば新しい角度から分析することができます。 科学者は長年にわたり、遺伝子、それらの関係、およびそれらが関与するプロセスの完璧な数学的表現を作成しようとしてきました。 今日は、フラクタルが癌の観点から人間の遺伝子のまったく新しい数学モデルの基礎を築くのにどのように役立ったかについてお話します。 フラクタルとは何ですか、なぜ遺伝学者や数学者にとってそれがそんなに重要なのですか?また、新しい数学モデルは現代医学にどのように役立つのでしょうか? 研究グループの報告書で答えを探します。 行こう
理論的後退
はじめに、フラクタルとは何か、何と一緒に食べられるかを簡単に理解する価値があります。
フラクタルは、自己相似特性を持つセットです。 簡単に言えば、何かがそれ自体のいくつかのミニコピーで構成されている場合です。

フラクタルは、拡散から乱流までのさまざまな物理現象に見られます。 これは、フラクタルの自然な発現と呼ぶことができます。 人々は、コンピューターグラフィックス、ラジオエンジニアリング、ネットワークテクノロジーなど、フラクタルのアプリケーションも見つけました。
エルダーが主人公に平行次元のツアーを送る映画「Doctor Strange」(2016)では、フラクタルは非常にカラフルです。

少し不快な光景ですが、フラクタル性を明確に示しています。
スーパーマーケットの棚でも、ロマネスコのキャベツやカリフラワーの例など、フラクタル性の兆候を見つけることができます。
フラクタル特性を備えた非常に多くのタイプのセットがあると考える場合、私たちの周りのほとんどすべてが何らかの形でフラクタルに関連していると主張することができます。 そして、人体、特にその遺伝子も例外ではありません。 フラクタルはコンポーネントをソートすることで数学的に説明できるため、人間の遺伝子でこのようなモデルを使用すると、さまざまな病気、病状、その他の不快なものを含む、体内で発生するさまざまなプロセスを理解するのに非常に役立ちます。
私たちの体で最も重要なプロセスの1つは、遺伝子の遺伝情報が機能的な製品に変換されるときの遺伝子発現です(画像1a )。 言い換えれば、私たちの細胞は遺伝子発現を通じて遺伝子の構造と機能を制御しています。 私たちの遺伝子は、身体のすべての細胞が情報を引き出し、その後必要な機能を実行するデータベースです。 したがって、私たちの口は毛を生やさず、免疫系は感染症と戦い、赤血球は酸素を輸送します。 これらのプロセスはすべて、特定のタスクを実行するための細胞のプログラミングにより正確に発生し、特定の遺伝子の活性化からのタンパク質合成によって順番に可能になります。
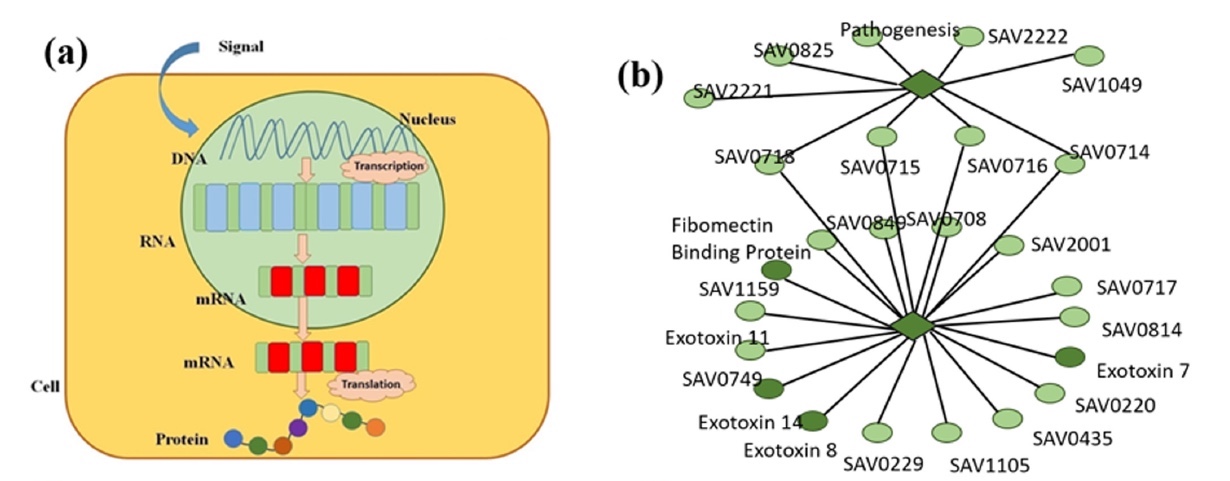
イメージNo. 1
遺伝子発現の調節は、特定のタンパク質をいつ、どれだけ、どれだけの期間生産する必要があるかを示します。 したがって、このプロセスの研究は、生物の制御の特定のメカニズムがどのように機能するかを完全に理解するために非常に重要です。
この複雑なプロセスは科学者にとって重要です。それを制御する機会があるため、明確な機能を備えた特定の合成細胞を作成できます。特に、より効果的な治療のためにがんの薬を病気の「心臓」に届けることができます。
そのような病気の治療方法を改善するためには、遺伝的側面をより詳細に学ぶ必要があります。 これを行うために、科学者は、プログラムの形で人体を表現することを提案します。プログラムは、プログラムが誤動作した場合に変更できるコード行として機能します。 これを実現するには、まず遺伝子の数学モデルを作成する必要があります。 現時点では、そのようなモデルはすでに存在しますが、遺伝子ネットワークのダイナミクスを研究することを目的としているため、代表的なものにはなりません。 フラクタルの概念を適用したこの研究では、科学者は特定の遺伝子の発現プロセスに焦点を合わせ、遺伝子-FT *ペア間の相互相関を適用することを決定しました( 1b )。
転写因子(FT)*は、特定のDNAサイトにリンクすることにより、DNAマトリックス上のタンパク質の一次構造に関する情報を含むmRNA合成制御タンパク質です。簡単に言えば、科学者は「壁」全体ではなく個々の「レンガ」を調べて、もう少し深く掘り下げることにしました。
調査結果
この研究の対象は、真菌Saccharomyces cerevisiae(パン酵母)および細菌Escherichia coli(Escherichia coli)でした。
実験対象の遺伝的発現の統計データを分析することにより、ハースト係数*が計算されました。
ハースト係数*は、時系列分析の尺度です。
時系列* -インジケーターについて異なる時間間隔で収集された統計データのセット。
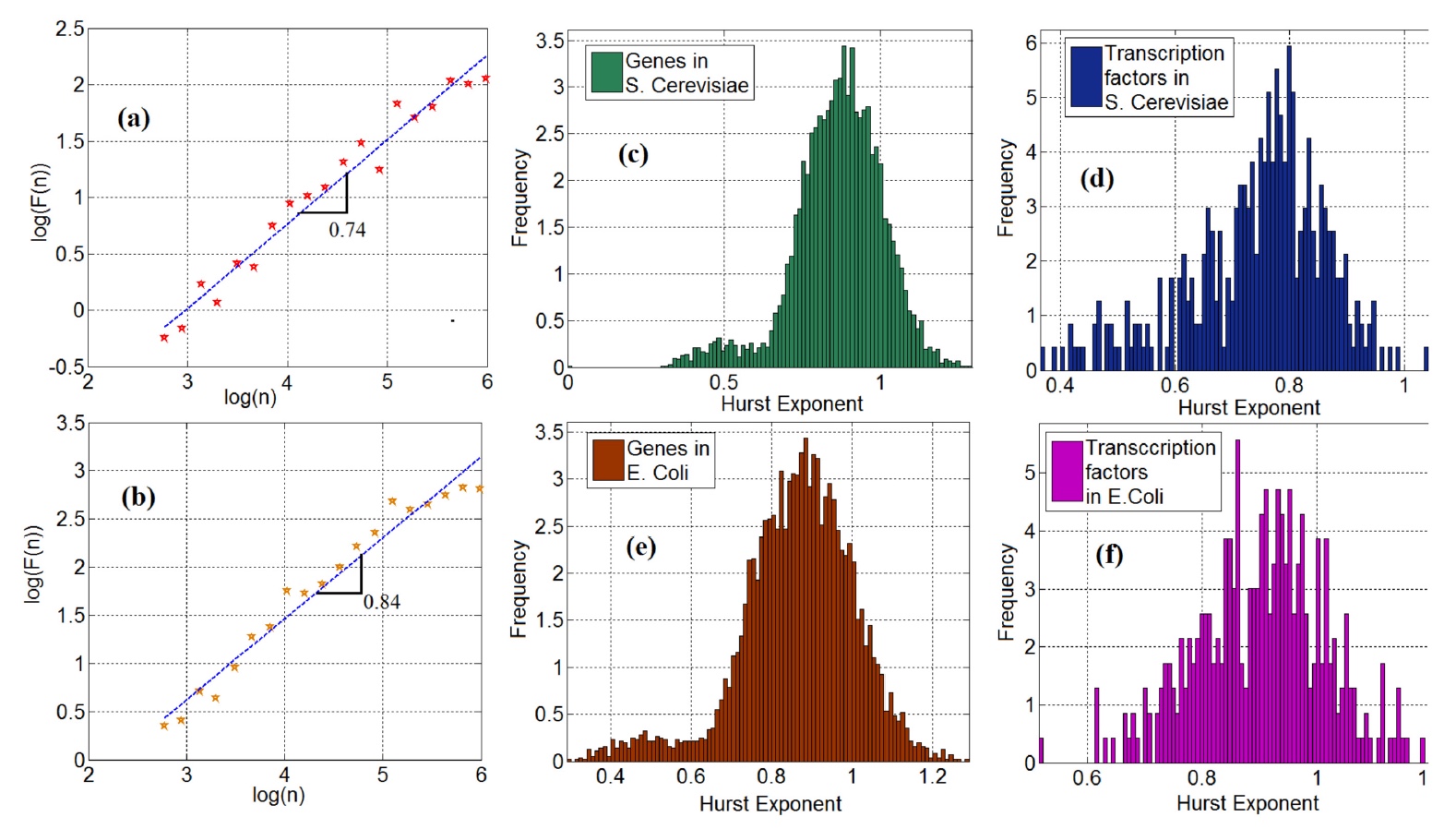
イメージNo. 2
図 2a (酵母)および2b (大腸菌)は、FT時系列のスケールの関数としての変動の対数グラフ*を示しています 。
対数グラフ* -両方の軸(垂直および水平)に対数目盛を使用した2次元データグラフ。これらのグラフの曲線の傾きは、ハースト係数に対応しています。 遺伝子の時系列の95%(酵母)と98%(菌)が長期依存性*を示したことは注目に値します。
長期依存性* -時系列の分析におけるインジケーター。2つのポイント間の統計的依存性の減衰が遅いことを示します。 これは、ハースト係数インジケーター(0〜1)によって決定されます。インジケーターが0.5を超える場合、0.5を下回る強い関係があり、これは逆の効果です。この特定のケースでの長期依存のハースト係数は0.5であり、理論的にはその不在を示しています。 ただし、データをさらに分析すると、このインジケーターが値0.5を超えることがわかりました。これは、遺伝子発現における時系列の長期依存性の存在を示しています( 2cおよび2e )。 これは、遺伝子FTの時系列はランダムなものと見なすことができないことを示唆しているため、一連のイベントが存在する場合、マルコフ連鎖に基づいてモデル化する必要があり、各イベントのランダム性は前のイベントのみに依存します。
遺伝子と同様に、転写因子も長期的な関係を示しました。酵母とバチルスでは97%です(グラフ2dおよび2f )。
ここで、一般的なボウルにひとつまみのフラクタル分析を追加します。 まず、科学者はハースト係数の分布の双峰性に注意を向けます。 これは、グラフ2cおよび2eで最もよく見られます。 科学者はこの観察結果を、いくつかの拡散ポテンシャルを持つ遺伝子発現の拡散プロセスがあるという事実によって説明しています。 したがって、二峰性は、異なるポテンシャルを持つ非平衡ブラウン運動によって説明できます。 しかし、この声明には追加の証拠が必要であり、科学者はこれを次の研究で検索します。
そして今、マルチフラクタル性に戻ります。 科学者は、トレンド変動のマルチフラクタル分析を適用して、遺伝子発現の時系列におけるマルチフラクタル特性の有無を判断しています。 この分析は、遺伝子とFTの両方の存在を示しました。
科学者はまた、 ブートストラップ*方法論を適用して、実験時系列の長さが限られている場合、長期的な関係の存在を正確に判断(より正確に確認)しました。
ブートストラップ* -確率分布の統計を分析する手法。遺伝子発現の各時系列について、10個のランダムなサブインターバルが準備され、それぞれが初期時系列の順序付けられたフラグメントの90%を含んでいた。 さらに、すべてのオプションについて、ハースト係数が計算されました。 したがって、実験時系列のインジケーターとランダムバージョンの違いが得られました。 大腸菌の場合、差はわずか0.006%でしたが、パン酵母の場合はさらに小さい-0.0001%でした。 したがって、両方のサンプルに長期依存の存在が確認されました。
関心のある遺伝子とFTの特性を別々に検討した後、科学者は遺伝子とFTのペアを単一のオブジェクトとして分析することに着手しました。 相互相関指数の計算により、98%の遺伝子とFTのペア(両方のサンプル)が長期依存の特性を持っていることが示されました( 3a )。
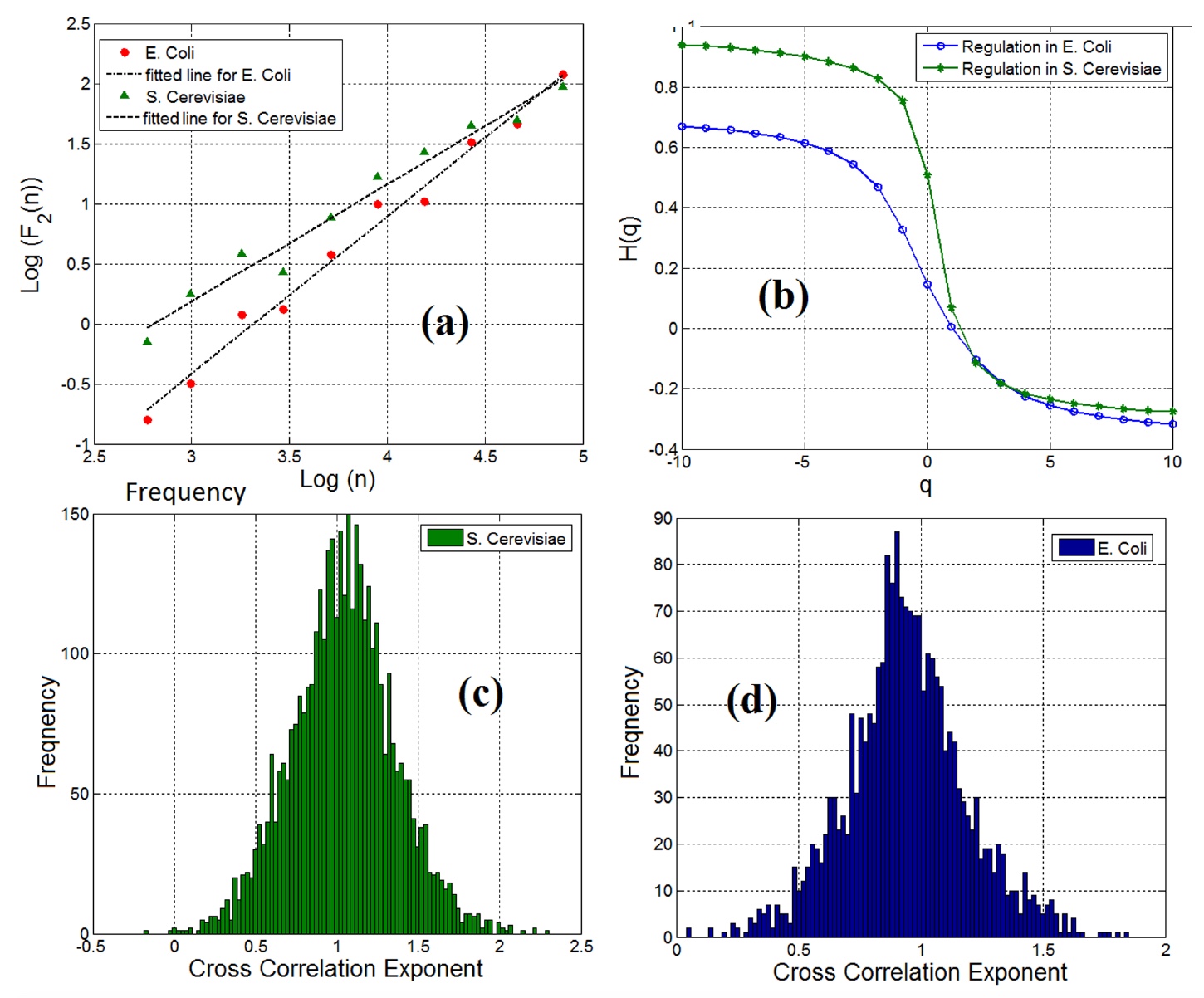
イメージNo. 3
トレンドの変動のマルチフラクタル分析により、遺伝子とFTのペアにマルチフラクタルの特徴が存在することが確認されました(グラフ3b )。
フラクタルと長期の相互相関が遺伝子と遺伝子調節ネットワークの転写因子のペアで観察されたという事実に関係なく、相互相関はすべてのペアで同じではなかったことは注目に値します。 グラフ3c (酵母)および3d (大腸菌)は、遺伝子とFTのペアの相互相関の指標を示しています。
科学者はこれらのグラフを使用して情報エントロピーを測定し、その結果、遺伝子調節ネットワークの定量分析と仕様化のために、さまざまな細胞タイプの遺伝子調節ネットワークの情報量を測定しました。 これは、パン酵母の遺伝子発現ネットワークがはるかに大きく、大腸菌の遺伝子発現ネットワークよりも複雑なダイナミクスを示していることを示唆しています。
そして今、最も興味深いのは数学モデルの作成です。 科学者は、2つのバージョンのモデルを選択しました。マンデルブロ集合と、ウェーブレット2進木の形式の集合です。
科学者は、以前に取得したマルチフラクタルスペクトルのヘルダー係数の指標を使用して、パン屋の酵母遺伝子調節ネットワーク内の遺伝子FTのすべてのペアの0.04のみがマンデルブロ集合を使用してモデル化できることを発見しました。 また、大腸菌では、この方法を使用して単一のペアをモデル化することはできません。
シミュレートできたこれらのペアを検討すると、モデルと実験の観測値の間でデータに大きな矛盾がありました。 結論として、マンデルブロ集合によるモデリング方法は適切ではありません。
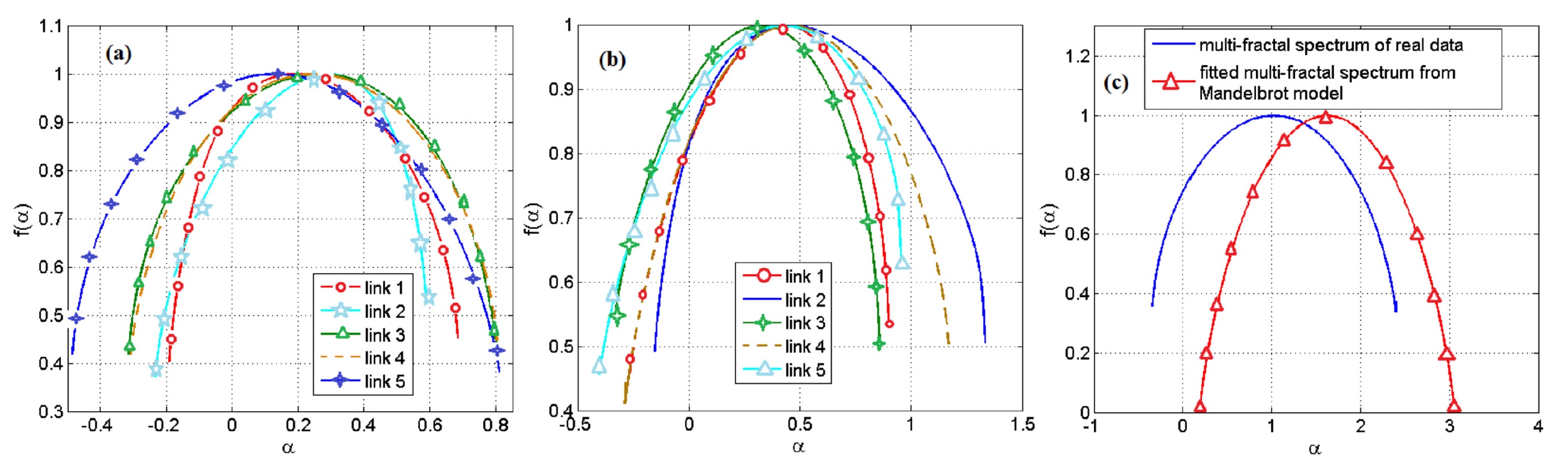
イメージNo.4
マンデルブロ集合に基づいたモデルを使用した結果は、上のグラフに示されています。 最も明るいのは4cで、データがどれだけ発散しているかを確認できます。
科学者はまた、観測された遺伝子調節ネットワークの相互依存性のマルチフラクタル性と、ウェーブレット2進木のランダムカスケードのマルチフラクタルモデルを比較しました。
研究者らは、Wカスケードの対数モデルが遺伝子調節ネットワークにおける遺伝子-FTペアの表現に適しているかどうかを確認することにしました。 経験的スペクトルと特異点のスペクトルに基づいて、このモデルのパラメーターを計算しました。 次に、計算された経験的マルチフラクタルスペクトルの交差領域の計算が行われ、その比率がこの数学的マルチフラクタルモデルを受け入れるか拒否するための主要な基準になりました。
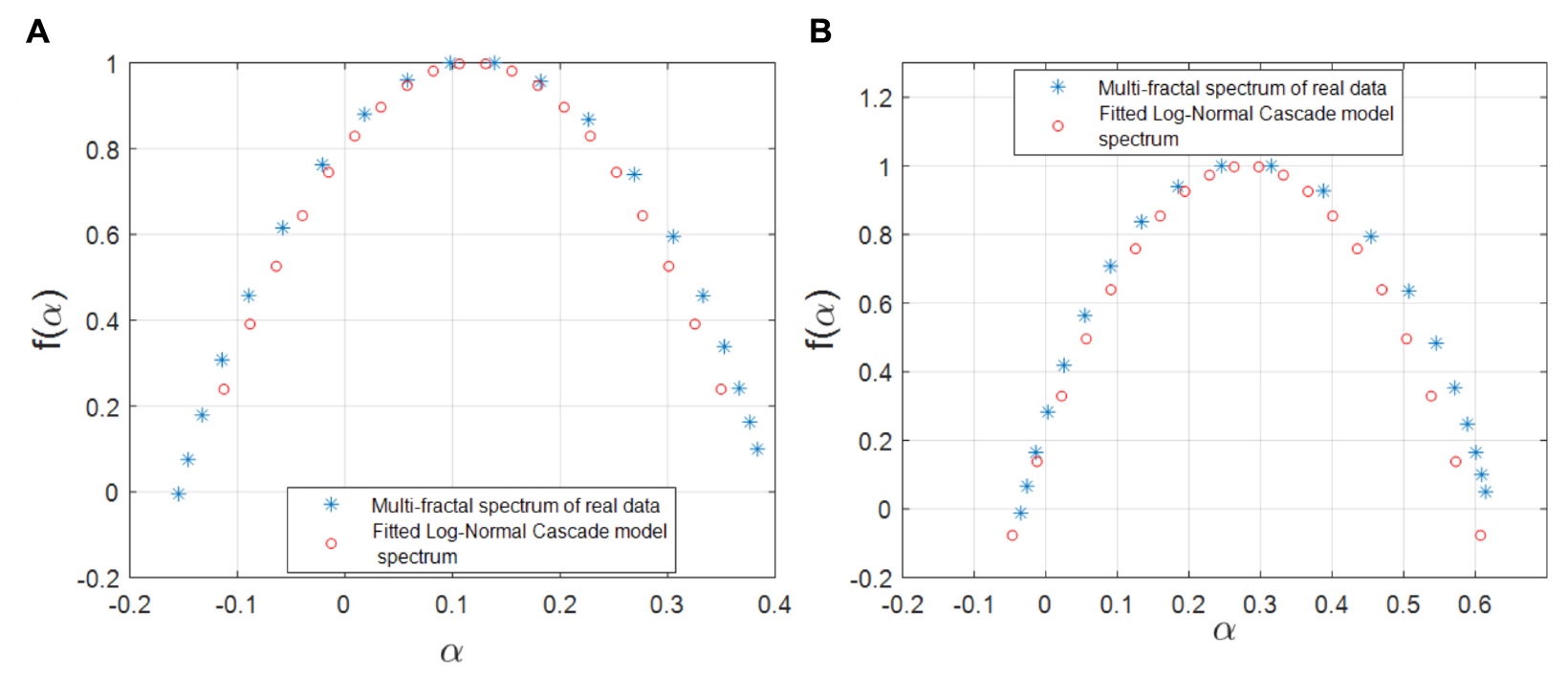
イメージNo. 5
シミュレーションおよび経験的マルチフラクタルスペクトルを示す上記のグラフからわかるように、このモデルは、以前に実行された観測および計算のデータとほぼ完全に相関しています。
この研究のニュアンスをさらに詳しく知りたい場合は、 このリンクの研究グループのレポートをご覧になることをお勧めします。
エピローグ
ほとんどの理論的であるこの研究は、遺伝子発現を調節するためのネットワークを数学的にモデル化するのに役立つため、実用化の大きな可能性を秘めています。 複雑なプロセスは、どんなに奇妙に聞こえても理解するのは困難です。 タスクを容易にするために、プロセスをコンポーネントに分割し、それらの「マップ」を作成し、目的のルートをたどり、すべての重要な機能と特性に注意する必要があります。 これには数学的モデリングが他に類を見ないほど素晴らしいです。 オブジェクトまたはプロセスの数学的モデルを研究した後、実際のオブジェクトまたはプロセスの研究に進む前に、私たちが何を扱っているかを理解できます。
この研究は、物理学と化学が世界を支配するだけでなく、数学が科学のオリンパスの最後の場所からはほど遠いことをもう一度確認しました。
ご静聴ありがとうございました
ご滞在いただきありがとうございます。 私たちの記事が好きですか? より興味深い資料を見たいですか? 注文するか、友人に推薦することで、私たちをサポートします。私たちがあなたのために発明したエントリーレベルのサーバーのユニークなアナログのHabrユーザーのために30%の割引: VPS(KVM)E5-2650 v4(6コア)についての真実20ドルまたはサーバーを分割する方法? (オプションはRAID1およびRAID10、最大24コア、最大40GB DDR4で利用可能です)。
VPS(KVM)E5-2650 v4(6コア)10GB DDR4 240GB SSD 1Gbpsまで1月1日まで無料で、6か月間支払われた場合は、 こちらから注文できます 。
Dell R730xdは2倍安いですか? オランダと米国で249ドルからIntel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TVを2台持っているだけです! インフラストラクチャビルの構築方法について読んでください。 クラスRは、1米ドルで9,000ユーロのDell R730xd E5-2650 v4サーバーを使用していますか?