挑戦する
購入を保存および分析するためのアプリケーションの大きなタスクの1つは、領収書から取得した製品のさまざまでわかりにくい名前を含むデータベース内の同一または非常に近い製品を検索することです。 入力要求には2つのタイプがあります。
- 地元のスーパーマーケットのレジ係または熱心なバイヤーのみが理解できる略語付きの特定の名前。
- ユーザーが検索文字列に入力する自然言語クエリ。
原則として、ユーザーがより安価な製品を見つける必要がある場合、第1種の要求はチェック自体の製品から送信されます。 私たちの仕事は、近くの他の店のチェックから最も類似した製品アナログを選択することです。 最も適切なブランドの製品と、可能であればボリュームを選択することが重要です。
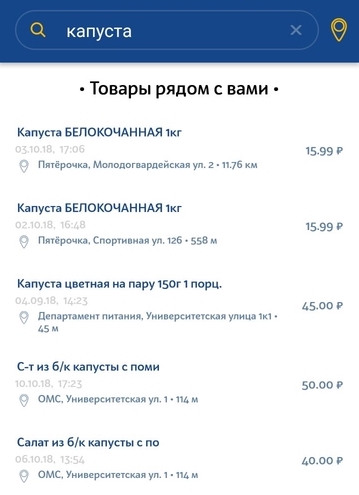
2番目のタイプのリクエストは、最も近い店舗で特定の製品を検索する単純なユーザーリクエストです。 要求は、製品の非常に一般的で一意ではない説明にすることができます。 要求からわずかな逸脱がある場合があります。 たとえば、ユーザーが牛乳3.2%を検索し、データベースでは牛乳2.5%のみを検索する場合、少なくともこの結果を表示する必要があります。
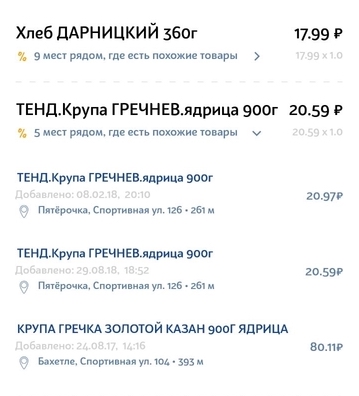
フィーチャデータセット-解決すべき問題
製品の領収書の情報は理想とはほど遠いものです。 略語、文法上の誤り、タイプミス、さまざまな翻訳、キリル文字の途中にあるラテン文字、および特定の店舗の内部組織にのみ意味のある文字セットが常に明確とは限りません。
たとえば、カッテージチーズ入りのリンゴとバナナのベビーピューレは、次のように簡単に書くことができます。

技術について
Elasticsearchは、検索を実装するためのかなり人気のある手頃な技術です。 これは、Luceneを使用し、Javaで記述されたJSON REST APIを備えた検索エンジンです。 Elasticの主な利点は、速度、スケーラビリティ、耐障害性です。 このようなエンジンは、ドキュメントのデータベースの複雑な検索で使用されます。 たとえば、言語の形態を考慮した検索や、地理座標による検索。
実験と改善の方向
検索を改善する方法を理解するには、検索システムを構成するカスタムコンポーネントに解析する必要があります。 この場合、システムの構造は次のようになります。
- 検索の入力文字列はアナライザーを通過し、特定の方法で文字列をトークンに分割します-トークンにも格納されているデータを検索する検索ユニット。
- 次に、既存のデータベースの各ドキュメントでこれらのトークンを直接検索します。 特定のドキュメント(トークンセットとしてデータベースに提示されている)でトークンを見つけた後、その関連性は、選択された類似性モデルに従って計算されます(これを関連性モデルと呼びます)。 これは、単純なTF / IDF (用語頻度-逆文書頻度)にすることも、他のより複雑なまたは特定のモデルにすることもできます。
- 次の段階で、個々のトークンによって得点されたポイントの数が特定の方法で集計されます。 集計パラメーターはクエリセマンティクスによって設定されます。 そのような集約の例としては、特定のトークンの追加の重み(付加価値)、トークンの必須存在の条件などがあります。 この段階の結果はスコアです。これは、データベースからの特定のドキュメントの初期リクエストに対する関連性の最終評価です。

個別に設定可能な3つのコンポーネントを検索デバイスと区別することができ、それぞれのコンポーネントで独自の改善方法と改善方法を強調できます。
- アナライザー
- 類似モデル
- クエリ時間の改善
次に、各コンポーネントを個別に検討し、製品名の場合の検索の改善に役立つ特定のパラメーター設定を分析します。
クエリ時間の改善
リクエストで改善できることを理解するために、最初のリクエストの例を示します。
{ "query": { "multi_match": { "query": " 105", "type": "most_fields", "fields": ["name"], "minimum_should_match": "70%" } }, “size”: 100, “min_score”: 15 }
「製品名」フィールドには複数のアナライザーの組み合わせが必要になると予想されるため、most_fieldsクエリタイプを使用します。 このタイプのクエリを使用すると、さまざまな方法で分析された同じテキストを含むオブジェクトのさまざまな属性の検索結果を組み合わせることができます。 このアプローチの代替方法は、best_fieldsまたはcross_fieldsクエリを使用することですが、検索はオブジェクトのさまざまな属性間で計算されるため(例:名前と説明)、これらのケースには適していません。 製品の名前という1つの属性のさまざまな側面を考慮に入れるという課題に直面しています。
設定できるもの:
- 異なるアナライザーの重み付き組み合わせ。
最初は、すべての検索要素の重みは同じであるため、重要度も同じです。 これは、数値をとるパラメーター「boost」を追加することで変更できます。 パラメーターが1より大きい場合、検索要素はそれぞれ結果に大きな影響を与えます(1未満-未満)。 - アナライザーを「should」と「must」に分離します。
つまり、特定のアナライザーは一致しなければならず、一部はオプションであり、つまり不十分です。 私たちの場合、番号分析はそのような分離の利点の例です。 リクエスト内の製品名とデータベース内の製品名で番号のみが一致する場合、これはそれらが同等であるための十分な条件ではありません。 結果としてそのような製品を見たくありません。 同時に、要求が「クリーム10%」である場合、10%の脂肪を含むすべてのクリームが20%の脂肪を含むクリームよりも大きな利点を持つようにします。 - minimum_should_matchパラメーター。 リクエストとデータベースのドキュメントで必ず一致する必要があるトークンの数は? このパラメーターは、リクエストのタイプ(most_fields)と連動して、各フィールド(この場合は各アナライザー)に一致するトークンの最小数をチェックします。
- min_scoreパラメーター。 不十分なポイントを持つしきい値スクリーニングドキュメント。 問題は、既知の最大速度がないことです。 結果のスコアは、特定の要求と特定のドキュメントデータベースに依存します。 150になることもあれば2になることもありますが、これらの値は両方とも、データベースのオブジェクトがリクエストに関連していることを意味します。 異なるクエリの結果のスコアを比較することはできません。
- 定数
さまざまなクエリの速度の最終値を十分に監視した後、おおよその境界を特定できます。その後、ほとんどのクエリでは結果が不適切になります。 これは最も簡単ですが、最も愚かな決定でもあり、品質の低い検索につながります。 - min_scoreが最小またはゼロの検索を実行した後、特定のリクエストに対して取得されたスコアを分析してみてください。
アイデアは、ある瞬間の後、速度が低下する方向への急激なジャンプを観察できるということです。 時間内に停止するために、このジャンプを決定するだけです。 このようなアプローチは、同様のクエリでうまく機能します。
ジャンプは統計的な方法で見つけることができます。 しかし、残念なことに、すべてのリクエストとはほど遠いこのジャンプは存在し、簡単に識別できます。 - 理想的な速度を計算し、min_scoreを理想の特定の割合として設定します。これは2つの方法で実行できます。
- Explain:trueパラメーターを設定するときにElastic自身が提供する計算の詳細な説明から。 これは難しいタスクであり、Elasticで使用される計算のクエリアーキテクチャとアルゴリズムを完全に理解する必要があります。
- ちょっとしたトリックで。 リクエストを受け取り、同じ名前でデータベースに新しい製品を追加し、検索を実行して最大速度を取得します。 名前が100%一致するため、結果の値は理想的です。 時間に関するこの操作の高コストに関する懸念は確認されていないため、このアプローチをシステムで使用しています。
- 定数
- 最終的な関連性の値の原因となるスコアリングアルゴリズムを変更します。 これは、店舗までの距離(より近い製品にさらにポイントを与える)、製品価格(最も確率の高い製品にさらにポイントを与える)などを考慮に入れることができます。
アナライザー
アナライザーは、入力文字列を3段階で分析し、出力でトークンを出力します-検索単位:

まず、文字列の文字レベルで変更が発生します。 これは、文字列を置換、削除、または文字列に追加することができます。 次に、文字列をトークンに分割するように設計されたトークナイザーが登場します。 標準のトークナイザーは、句読点に従って文字列をトークンに分割します。 最後のステップでは、受信したトークンがフィルタリングされて処理されます。
この場合、どのステップのバリエーションが有用になったかを検討してください。
チャーフィルター
- ロシア語の仕様によれば、thやeなどの文字を処理し、それぞれandとeに置き換えると便利です。
- 文字変換-ある文字の文字を別の文字の文字に変換します。 私たちの場合、これはラテン語で書かれた名前または両方のアルファベットが混在した名前の処理です。 音訳は、プラグイン( ICU Analysis Plugin )をトークンのフィルターとして使用して実装できます(つまり、元の文字列ではなく、最終的なトークンを処理します)。 プラグインのアルゴリズムに満足できなかったため、音訳を書くことにしました。 アイデアは、最初に4文字セットの出現(たとえば、「SHCH => u」)、次に3文字出現などを置き換えることです。結果は順序に依存するため、シンボルフィルターの使用順序は重要です。
- キリル文字に囲まれたラテン語cをロシア語pに置き換えます。 この必要性は、データベース内の名前を分析した後に特定されました。キリル文字の非常に多くの名前には、ラテン文字cが含まれています。これは、キリル文字cを意味します。 名前が完全にラテン語であるかのように、ラテン語Cはキリル文字のkまたはcを意味します。 したがって、音訳を実行する前に、記号cを置き換える必要があります。
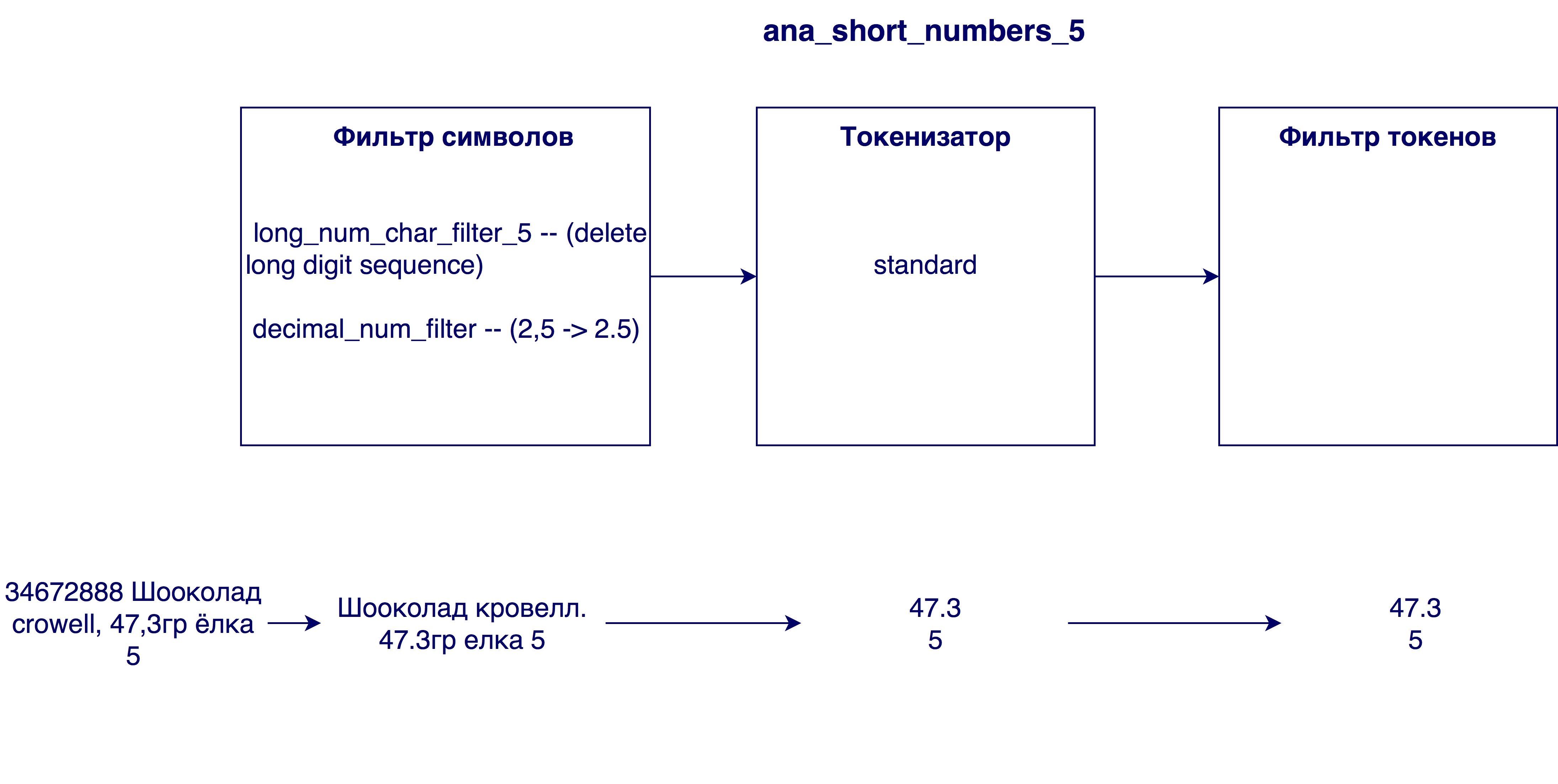
- タイトルから大きすぎる数字を削除します。 製品名に内部識別番号(例:3387522 K.Ts. Maslo sunflower.raf。0.9l)が含まれている場合がありますが、これは一般的な場合には意味を持ちません。
- コンマをピリオドに置き換えます。 なぜこれが必要なのですか? 数字、たとえば乳脂肪3.2と3.2は同等です
トークナイザー
- 標準トークナイザー-スペースと句読点に従って行を区切ります(例:「twix extra 2」->「twix」、「extra」、「2」)
- EdgeNGramトークナイザー-各単語を、最初の文字で始まる特定の長さ(通常は数値の範囲)のトークンに分割します(たとえば、N = [3、6]の場合: "twix extra 2"-> "twee"、 "tweak"、 「Twix」、「ex」、「ext」、「ext」、「extra」)
- 数字のトークナイザー-正規表現を検索して、文字列から数字のみを選択します(例:「twix extra 2 4.5」->「2」、「4.5」)
トークンフィルター
- 小文字フィルター
- スタミングフィルター-トークンごとにスタミングアルゴリズムを実行します。 ステミングとは、単語の初期形式を決定することです(例:「rice」->「rice」)
- 音声分析。 入力ミスや検索結果に同じ単語を書くさまざまな方法の影響を最小限に抑えるために必要です。 この表は、音声分析に使用可能なさまざまなアルゴリズムと、問題のある場合の作業の結果を示しています。 最初のケース(シャンプー/シャンパン/シャンピニオン/シャンピニオン)で成功するかどうかは、異なるエンコードの生成によって決まります。残りは同じです。

類似モデル
1つのトークンの一致が、リクエストに関するデータベースからのオブジェクトの関連性にどの程度影響するかを判断するには、関連性モデルが必要です。 リクエストのトークンとデータベースの製品が一致する場合、これは確かに悪いことではありませんが、リクエストに対する製品の適合性についてはほとんど語っていません。 したがって、異なるトークンの一致は異なる値を持ちます。 これを考慮するには、関連性モデルが必要です。 Elasticは多くの異なるモデルを提供します。 それらを本当に理解していれば、特定のケースに非常に具体的で適切なモデルを選択できます。 選択は、頻繁に使用される単語の数(同じトークンなど)、長いトークンの重要性の評価(長い方が良い?悪い?関係ない?)、最後にどのような結果を表示するかなどに基づいて決定できます。 Elasticで提案されているモデルの例には、TF-IDF(最も単純で最も理解しやすいモデル)、 Okapi BM25 (拡張TF-IDF、デフォルトモデル)、ランダム性からの発散、独立性からの発散などがあります。 各モデルにはカスタマイズ可能なオプションもあります。 モデルでのいくつかの実験の後、Okapi BM25デフォルトモデルは最良の結果を示しましたが、パラメーターは事前定義されたものとは異なりました。
カテゴリーを使用する
検索を使用する過程で、製品に関する非常に重要な追加情報-そのカテゴリ-が利用可能になりました。 記事でカテゴリ化の実装方法について詳しく読むことができますが、 私が理解しているように、お菓子をたくさん食べたり、アプリケーションでチェックして商品を分類したりしています 。 それまでは、製品名の比較のみに基づいて検索を行っていましたが、今ではデータベース内のリクエストと製品のカテゴリを比較することが可能になりました。
この情報を使用するための可能なオプションは、カテゴリフィールドでの必須の一致(結果のフィルターとして書式設定)、一致するカテゴリー(数字の場合など)を持つ商品のポイントの形式での追加の利点、およびカテゴリによる結果の並べ替え(最初の一致、次に他のすべて)です。 私たちの場合、最後のオプションが最も効果的でした。 これは、分類アルゴリズムが2番目の方法を使用するにはあまりにも優れており、1番目の方法を使用するには不十分であるためです。 アルゴリズムには十分に自信があり、カテゴリマッチングが大きな利点になることを望んでいます。 速度に追加のポイントを追加する場合(2番目の方法)、同じカテゴリの商品はリストの上位に表示されますが、名前でより一致する商品には引き続き失われます。 ただし、カテゴリ化のエラーは依然として発生する可能性があるため、最初の方法はどちらにも適していません。 リクエストにカテゴリを正しく判断するのに不十分な情報が含まれている場合や、ユーザーの直近の半径にあるこのカテゴリの製品が少なすぎる場合があります。 この場合、結果を別のカテゴリで表示したいのですが、製品名で引き続き関連します。
2番目の方法は、検索の結果として製品の速度を「損なう」ことはなく、計算された最小速度を障害なく使用し続けることができるため、優れています。
並べ替えの具体的な実装は、最終クエリで確認できます。
最終モデル
最終的な検索モデルの選択には、さまざまな検索エンジンの生成、それらの評価と比較が含まれていました。 ほとんどの場合、比較はパラメーターの1つに基づいていました。 1つの特定のケースで、edgeNgramトークナイザーの最適なサイズを計算する必要があると仮定します(つまり、Nの最も効果的な範囲を選択します)。 これを行うために、この範囲のサイズが1つだけ異なる同じ検索エンジンを生成しました。 その後、このパラメーターの最適値を決定することができました。
モデルは、ランキングの品質を評価するためのメトリックであるnDCG(正規化された割引累積ゲイン)メトリックを使用して評価されました。 事前定義されたクエリが各検索モデルに送信され、その後、受信した検索結果からnDCGメトリックが計算されました。
最終モデルに入ったアナライザー:



パラメーターb = 0.5のデフォルトモデル(Okapi-BM25)が関連性モデルとして選択されました。 デフォルト値は0.75です。 このパラメーターは、製品名の長さがtf(期間頻度)変数を正規化する程度を示します。 長い名前は単一の単語の重要性にほとんど影響しないため、この例では小さい数字の方がうまく機能します。 つまり、「25個入りのパッケージに砕いたヘーゼルナッツが入ったチョコレート」という名前の「チョコレート」という言葉は、名前が十分に長いという事実からその価値を失うことはありません。
最終的なクエリは次のようになります。
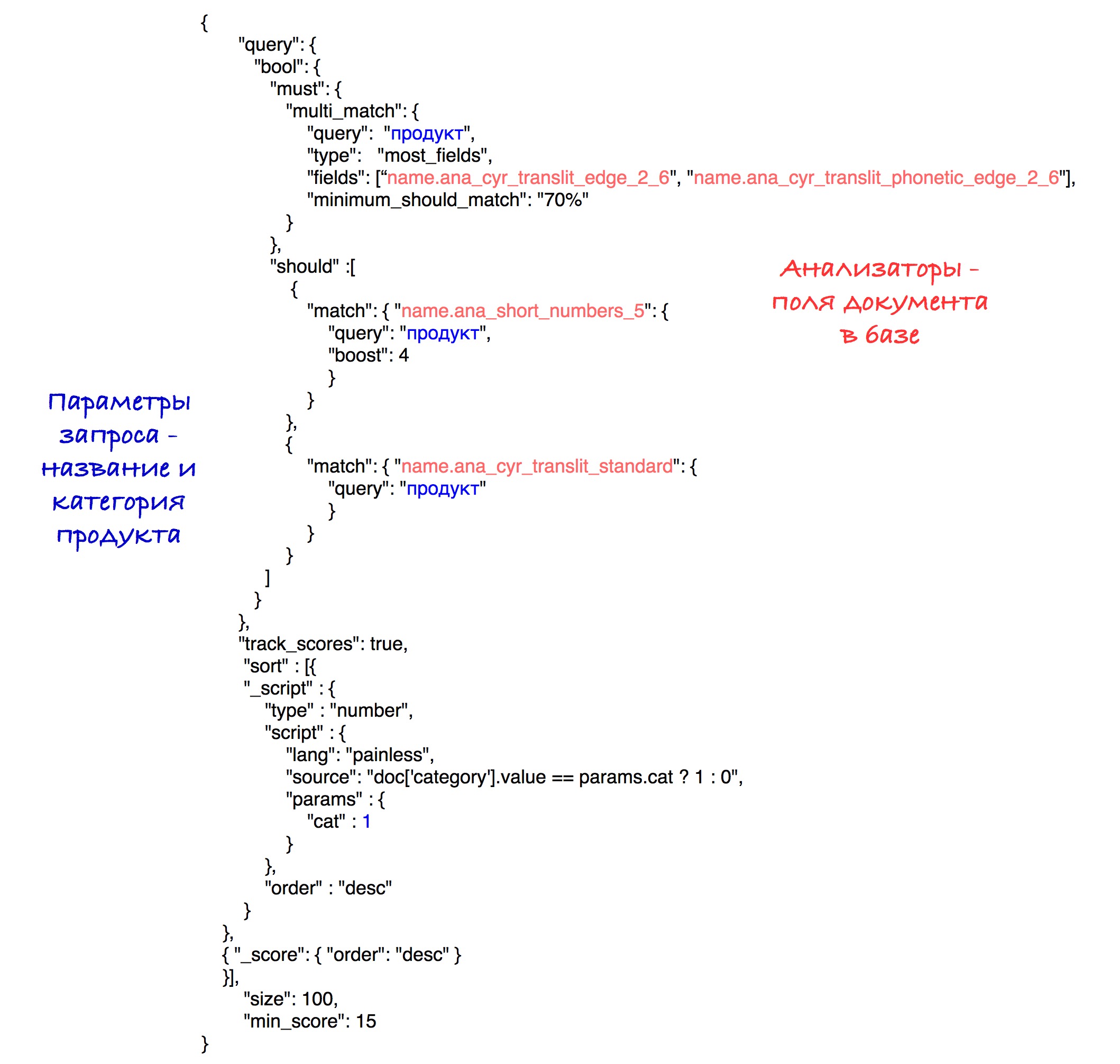
実験的に、アナライザーと重量の最適な組み合わせが明らかになりました。
並べ替えの結果、同じカテゴリの製品は結果の先頭に移動し、他のすべての製品に移動します。 ポイント数(速度)によるソートは、各サブセット内に保存されます。
簡単にするために、このクエリでは速度のしきい値を15に指定しましたが、システムでは前述の計算されたパラメーターを使用します。
将来的には
私たちのアルゴリズムで最も恥ずかしい問題の1つを解決することで検索を改善する考えがあります。それは、100万の存在と5文字の単語を短縮する別の方法です。 略語を明らかにするために、名前の最初の処理で解決できます。 これを解決する1つの方法は、データベースの短縮名と、データベースの「正しい」フルネームの名前の1つを比較することです。 この決定は明確な障害を満たしますが、有望な変化のようです。