作成した辞書の要素数、各要素に費やされるメモリ量、現在(CPython 3.6以降)辞書が2つの配列に実装され、挿入順序の維持にどのように関係するのかわからない場合、またはレイモンドヘッティンガーのプレゼンテーションを見ていない辞書多数の素晴らしいアイデアの合流点。」 それからようこそ。
ただし、講義に精通している人は、詳細と最新情報を見つけることもできます。また、バケットとクローズドハッシュに精通していない初心者にとっても、この記事は興味深いものです。
CPythonの辞書はどこにでもあり、クラス、グローバル変数、kwargsパラメーターはそれらに基づいており、スクリプトに中括弧を追加していなくても、 インタープリターは何千もの辞書を作成します。 しかし、多くの適用された問題を解決するために、辞書も使用されます。それらの実装が改善され続け、ますますさまざまなトリックに成長することは驚くことではありません。
辞書の基本的な実装(Hashmap経由)
標準のハッシュマップとプライベートハッシュの作業に精通している場合は、次の章に進むことができます。
辞書の基礎となる概念は単純です。同じサイズのオブジェクトが格納されている配列がある場合、インデックスを知っているため、目的のオブジェクトに簡単にアクセスできます。
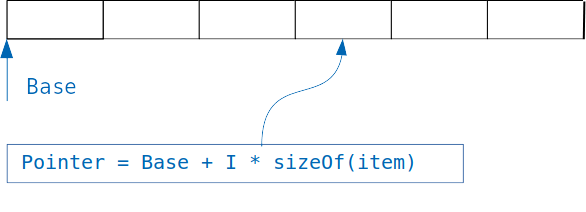
オブジェクトのサイズを乗算したインデックスを配列のオフセットに追加するだけで、目的のオブジェクトのアドレスを取得できます。
しかし、整数インデックスではなく、たとえばメールアドレスでユーザーを見つけるために別のタイプの変数で検索を整理する場合はどうでしょうか。
単純な配列の場合、配列内のすべてのユーザーのメールを調べて、それらを検索と比較する必要があります。このアプローチは線形検索と呼ばれ、明らかに、インデックスによってオブジェクトにアクセスするよりもはるかに遅いです。
検索する領域のサイズを制限すると、線形検索を大幅に高速化できます。 これは通常、 ハッシュの残りを取ることによって達成されます。 検索されるフィールドはキーです。
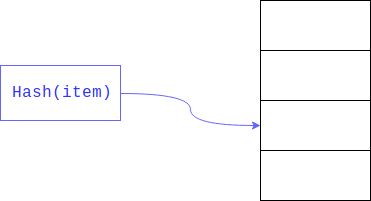
その結果、線形検索は大きな配列全体ではなく、その部分に沿って実行されます。
しかし、既に要素が存在する場合はどうでしょうか? これは非常によく起こります。なぜなら、ハッシュを分割することによる残基が一意であることを誰も保証しなかったからです(ハッシュ自体のように)。 この場合、オブジェクトは次のインデックスに配置されます。オブジェクトがビジーの場合、別のインデックスだけ移動し、空きインデックスが見つかるまで移動します。 アイテムを取得すると、同じハッシュを持つすべてのキーが表示されます。
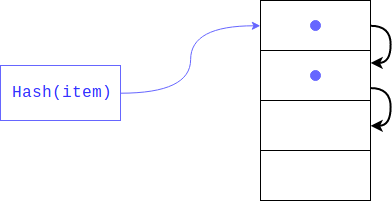
このタイプのハッシュはプライベートと呼ばれます。 辞書に空きセルがほとんどない場合、このような検索は線形に縮退する恐れがあるため、辞書が作成されたすべての賞金を失うため、インタープリターは配列を1/2-2/3に埋めます。 十分な空きセルがない場合、新しい配列は前の配列の2倍の大きさで作成され、古い配列の要素は一度に新しい配列に転送されます。
アイテムが削除された場合の対処方法 この場合、空のセルが配列に形成され、キーによる検索アルゴリズムは区別できません。そのようなハッシュを持つ要素が辞書にないか、削除されたため、このセルは空です。 削除中のデータの損失を防ぐため、セルには特別なフラグ(DKIX_DUMMY)が付けられています。 要素の検索中にこのフラグが検出された場合、検索は続行され、セルはビジーと見なされます。挿入された場合、セルは上書きされます。
Pythonの実装機能
辞書の各要素には、ターゲットオブジェクトとキーへのリンクが含まれている必要があります。 キーは、明らかな理由でオブジェクトである衝突を処理するために保存する必要があります。 キーとオブジェクトはいずれのタイプおよびサイズでも構いませんので、構造に直接保存することはできず、動的メモリにあり、それらへのリンクはリストアイテムの構造に保存されます。 つまり、1つの要素のサイズは、2つのポインターの最小サイズ(64ビットシステムでは16バイト)と等しくなければなりません。 ただし、インタプリタはハッシュも保存します。これは、辞書のサイズが大きくなるたびにハッシュを再計算しないようにするためです。 インタプリタは、新しい方法で各キーからハッシュを計算し、バケット数による除算の残りを取得する代わりに、すでに保存されている値を読み取ります。 しかし、キーオブジェクトが変更された場合はどうなりますか? この場合、ハッシュを再計算する必要があり、保存された値は間違っていますか? 可変型は辞書キーにできないため、このような状況は不可能です。
辞書要素の構造は次のように定義されます。
typedef struct { Py_hash_t me_hash; // PyObject *me_key; // PyObject *me_value; // } PyDictKeyEntry;
ディクショナリの最小サイズは8のPyDict_MINSIZE定数で宣言されます。開発者は、空の値を格納するための不要なメモリの浪費と配列の動的拡張の時間を避けるためにこれが最適なサイズであると判断しました。 したがって、ディクショナリを作成する場合(バージョン3.6まで)、ディクショナリに最低8つの要素が必要でした*構造体に24バイト= 192バイト(これは、残りのフィールドを考慮しません:ディクショナリ変数自体のコスト、要素数のカウンターなど)
辞書は、カスタムクラスフィールドの実装にも使用されます。 Pythonでは、属性の数を動的に変更できます。属性の追加/削除は、辞書の対応する操作と本質的に同等であるため、このダイナミクスに追加コストは必要ありません。 ただし、少数のプログラムがこの機能を使用しており、ほとんどは__init__で宣言されたフィールドに制限されています。 ただし、各オブジェクトは、他のオブジェクトと一致するという事実にもかかわらず、キーとハッシュを含む独自の辞書を保存する必要があります。 ここでの論理的な改善点は、共有キーを1か所だけに保存することです。これは、まさにPEP 412-Key-Sharing Dictionaryで実装されたものです。 辞書を動的に変更する機能は消えませんでした。キーの順序または数が変更されると、辞書は分割キーから通常のキーに変換されます。
衝突を避けるため、辞書の最大「ロード」は配列の現在のサイズの2/3です。
#define USABLE_FRACTION(n) (((n) << 1)/3)
したがって、6番目の要素が追加されると、最初の拡張子が発生します。
アレイはプログラム動作中に完全に放電され、セルの半分から3分の1が空のままであることが判明し、メモリ消費が増加します。 この制限を回避し、可能であれば必要なデータのみを保存するために、新しい
スパース配列を保存する代わりに、たとえば:
d = {'timmy': 'red', 'barry': 'green', 'guido': 'blue'} # -> entries = [['--', '--', '--'], [-8522787127447073495, 'barry', 'green'], ['--', '--', '--'], ['--', '--', '--'], ['--', '--', '--'], [-9092791511155847987, 'timmy', 'red'], ['--', '--', '--'], [-6480567542315338377, 'guido', 'blue']]
バージョン3.6以降、辞書は次のように編成されています。
indices = [None, 1, None, None, None, 0, None, 2] entries = [[-9092791511155847987, 'timmy', 'red'], [-8522787127447073495, 'barry', 'green'], [-6480567542315338377, 'guido', 'blue']]
つまり 本当に必要なレコードのみが保存され、別の配列でハッシュテーブルから取り出され、対応するレコードのインデックスのみがハッシュテーブルに保存されます。 最初に配列が192バイトを使用していた場合、現在は80(各レコードに3 * 24バイト+インデックスに8バイト)しかありません。 58%の圧縮率[2]
インデックス内の要素のサイズも動的に変化します。最初は1バイトです。つまり、インデックスが8ビットに収まり始めると、配列全体を1つのレジスタに配置できます。その後、要素は16、32ビットに拡張されます。 特別な定数DKIX_EMPTYとDKIX_DUMMYがあり、それぞれ空の要素と削除された要素に対して、辞書に127を超える要素がある場合に16バイトへのインデックスの拡張が発生します。
新しいオブジェクトがエントリに追加されます。つまり、ディクショナリを展開するときに、それらを移動する必要はありません。インデックスのサイズを増やして、インデックスでいっぱいにするだけです。
辞書を反復処理する場合、indexs配列は必要ありません。要素はエントリから順番に返されます。 エントリの最後に要素が追加されるたびに、辞書は要素の出現順序を自動的に保存します。 したがって、辞書を保存するために必要なメモリを削減することに加えて、キーの順序のより迅速な動的拡張と保存を受け取りました。 メモリを削減すること自体は優れていますが、同時に、より多くのエントリをプロセッサキャッシュに収めることができるため、パフォーマンスを向上させることができます。
CPython開発者はこの実装を非常に気に入ったため、仕様による挿入順序を維持するために辞書が必要になりました。 以前に辞書の順序が決定された場合、つまり ハッシュによって厳密に定義され、最初から最初まで変更されていません。その後、キーが毎回異なるように少しランダム性が追加され、辞書キーは順序を維持する必要があります。 これがどれだけ必要であったか、および辞書のさらに効果的な実装が表示された場合の対処方法は明らかではありませんが、挿入順序は保持されません。
ただし、 クラスおよびkwargsで属性の宣言を保持するメカニズムを実装する要求があり、この実装により、特別なメカニズムなしでこれらの問題を解決できます。
CPythonコードでは次のようになります 。
struct _dictkeysobject { Py_ssize_t dk_refcnt; /* Size of the hash table (dk_indices). It must be a power of 2. */ Py_ssize_t dk_size; /* Function to lookup in the hash table (dk_indices): - lookdict(): general-purpose, and may return DKIX_ERROR if (and only if) a comparison raises an exception. - lookdict_unicode(): specialized to Unicode string keys, comparison of which can never raise an exception; that function can never return DKIX_ERROR. - lookdict_unicode_nodummy(): similar to lookdict_unicode() but further specialized for Unicode string keys that cannot be the <dummy> value. - lookdict_split(): Version of lookdict() for split tables. */ dict_lookup_func dk_lookup; /* Number of usable entries in dk_entries. */ Py_ssize_t dk_usable; /* Number of used entries in dk_entries. */ Py_ssize_t dk_nentries; /* Actual hash table of dk_size entries. It holds indices in dk_entries, or DKIX_EMPTY(-1) or DKIX_DUMMY(-2). Indices must be: 0 <= indice < USABLE_FRACTION(dk_size). The size in bytes of an indice depends on dk_size: - 1 byte if dk_size <= 0xff (char*) - 2 bytes if dk_size <= 0xffff (int16_t*) - 4 bytes if dk_size <= 0xffffffff (int32_t*) - 8 bytes otherwise (int64_t*) Dynamically sized, SIZEOF_VOID_P is minimum. */ char dk_indices[]; /* char is required to avoid strict aliasing. */ /* "PyDictKeyEntry dk_entries[dk_usable];" array follows: see the DK_ENTRIES() macro */ };
しかし、イテレーションは最初に考えるよりも複雑です。ディクショナリがイテレーション中に変更されなかったという追加の検証メカニズムがあります。それらの1つは、各ディクショナリを格納する64ビットバージョンのディクショナリです。
最後に、衝突を解決するメカニズムを検討します。 事は、Pythonでは、ハッシュ値は簡単に予測可能です:
>>>[hash(i) for i in range(4)] [0, 1, 2, 3]
そして、これらのハッシュからディクショナリを作成するとき、除算の残りが使用されるため、実際には、キーの最後の数ビット(整数の場合)だけがレコードの宛先となるバケットを決定します。 多くのオブジェクトが隣接するバケツに「入りたい」という状況を想像できます。その場合、検索の際に場違いなオブジェクトをたくさん見る必要があります。 衝突の数を減らし、レコードが行くバケットを決定するビットの数を増やすために、次のメカニズムが実装されました。
// i = i + 1 % n // : #define PERTURB_SHIFT 5 perturb >>= PERTURB_SHIFT; j = (5*j) + 1 + perturb; // j % n
perturbは、ハッシュによって初期化される整数変数です。 衝突の数が多い場合、ゼロにリセットされ、次のインデックスが式によって計算されることに注意してください。
j = (5 * j + 1) % n
辞書から要素を抽出すると、同じ検索が実行されます。要素が配置されるスロットのインデックスが計算されます;スロットが空の場合、例外「値が見つかりません」がスローされます。 このスロットに値がある場合、キーが探しているものと一致することを確認する必要があります。衝突が発生した場合、これは不可能な場合があります。 ただし、キーは、比較操作にかなりの時間を要するものを含め、ほとんどすべてのオブジェクトにできます。 長い比較操作を避けるために、Pythonではいくつかのトリックが使用されます。
# ( , C) def eq(key, entity): if id(key) == id(entity): return True if hash(key) != hash(entity): return False return key == entity
最初に、ポインタが比較されます。目的のオブジェクトのキーポインタが検索対象のオブジェクトのポインタと等しい場合、つまり、同じメモリ領域を指している場合、比較は直ちにtrueを返します。 しかし、それだけではありません。 ご存じのように、等しいオブジェクトには等しいハッシュが必要です。これは、異なるハッシュを持つオブジェクトが等しくないことを意味します。 ポインターをチェックした後、ハッシュがチェックされます;それらが等しくない場合、falseが返されます。 そして、ハッシュが等しい場合にのみ、正直な比較が呼び出されます。
そのような結果の可能性は何ですか? 約2 ^ -64はもちろん、ハッシュ値を簡単に予測できるため、このような例を簡単に選択できますが、実際には、この検証は頻繁に行われません。 レイモンド・ヘッティンガーは、最後の比較操作を単純なtrueの戻り値に変更してインタープリターを組み立てました。 つまり ハッシュが等しい場合、インタープリターはオブジェクトが等しいと見なしました。 その後、彼はこのインタプリタで人気のある多くのプロジェクトの自動テストを設定し、正常に終了しました。 ハッシュが等しいオブジェクトを考慮し、その内容をさらにチェックせず、ハッシュのみに完全に依存するのは奇妙に思えるかもしれませんが、gitまたはtorrentプロトコルを使用する場合は定期的にこれを行います。 ハッシュが等しい場合、ファイル(ファイルブロック)は等しいと見なされ、エラーにつながる可能性がありますが、作成者(および私たち全員)は、衝突の可能性が非常に小さいことは注目に値します。
これで、次のような辞書の構造を最終的に理解できるはずです。
typedef struct { PyObject_HEAD /* Number of items in the dictionary */ Py_ssize_t ma_used; /* Dictionary version: globally unique, value change each time the dictionary is modified */ uint64_t ma_version_tag; PyDictKeysObject *ma_keys; /* If ma_values is NULL, the table is "combined": keys and values are stored in ma_keys. If ma_values is not NULL, the table is splitted: keys are stored in ma_keys and values are stored in ma_values */ PyObject **ma_values; } PyDictObject;
今後の変化
前の章では、すでに実装されており、作業中のすべての人が使用できるものを検討しましたが、もちろん、改善は以下に限定されません:バージョン3.8の計画には、逆辞書のサポートが含まれます。 実際、要素の配列の先頭から繰り返し、インデックスを増やし、最後から始めてインデックスを減らしていくことを妨げるものはありません。
追加資料
トピックをより深く理解するには、次の資料に精通することをお勧めします。
- 記事の冒頭のレポートの記録
- 辞書の新しい実装の提案
- CPythonの辞書ソースコード