はいの場合-あなたはすでにあなたがこのような何かを書く必要があると想像しています
SELECT hour(datetime), somename, count(*), sum(somemetric) from table where datetime > :monthAgo group by 1, 2 order by 1 desc, 2
随時、さまざまな類似のリクエストが表示され始めます。そして、一度耐えて助けていただければ、残念ながら、将来的にアピールするでしょう。
しかし、そのような要求は実行時にシステムリソースを十分に消費し、そのような要求のレプリカでさえ残念な(そしてその時間)データになる可能性があるという点で悪いです。
しかし、上記のように、PostgreSQLで、同じようなクエリで新しい受信データのみを考慮に入れるビューを作成できるとしたらどうでしょうか。
だから-それは拡張PipelineDBを行うことができます
サイトのデモの仕組み 
PipelineDBは以前は別個のプロジェクトでしたが、PG 10.1以降の拡張機能として利用できるようになりました。
また、提供される機会は、リアルタイムメトリックを収集するために特別に設計された他の製品に長い間存在していましたが、PipelineDBには大きなプラスがあります。
おそらくそれは必須ではありません。 個人的には、特定の問題を解決するのに適していると思われるすべてを試すのは面倒ではありませんが、すべての場合にすぐに1つの新しいソリューションを使用することはしません。 したがって、この記事では、すべてをドロップしてPipelineDBをすぐにインストールすることをお勧めしません。これは、主な機能の概要です。 物事は私には興味津々のようでした。
それで、一般的に、彼らは良いドキュメントを持っていますが、実際にこのプラクティスを試し、Grafanaに結果をもたらす方法に関する私の経験を共有したいと思います。
ローカルマシンを散らかさないように、すべてをdockerにデプロイします。
使用画像:
postgres:latest
、
grafana/grafana
PipegreDBをPostgresにインストールする
postgresを搭載したマシンで、順番に実行します。
-
apt update
-
apt install curl
-
curl -s http://download.pipelinedb.com/apt.sh | bash
-
apt install pipelinedb-postgresql-11
-
cd /var/lib/postgresql/data
- 任意のエディターで
postgresql.conf
ファイルを開きます -
shared_preload_libraries
キーを見つけ、コメントを外して、pipelinedb
値を設定します - キー
max_worker_processes
は128に設定されています(推奨ドック) - サーバーを再起動
PipelineDBでストリームとビューを作成する
再起動後pg-そのようなことがあるようにログを監視します 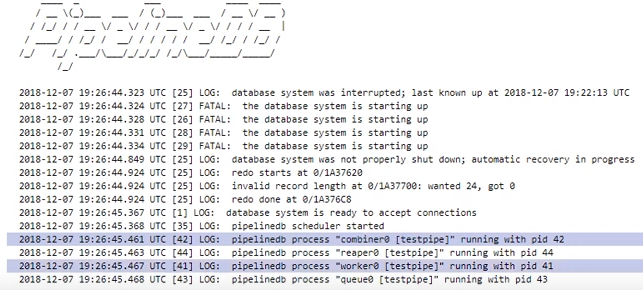
- 作業するデータベース:
CREATE DATABASE testpipe;
- 拡張機能の作成:
CREATE EXTENSION pipelinedb;
- 今、最も興味深いのはストリームを作成することです。 その中で、さらに処理するためにデータを追加する必要があります。
CREATE FOREIGN TABLE flow_stream ( dtmsk timestamp without time zone, action text, duration smallint ) SERVER pipelinedb;
実際、通常のテーブルを作成するのと非常によく似ていselect
単純なselect
このストリームからデータを取得することはできません-ビューが必要です - 実際にそれを作成する方法:
CREATE VIEW viewflow WITH (ttl = '3 month', ttl_column = 'm') AS select minute(dtmsk) m, action, count(*), avg(duration)::smallint, min(duration), max(duration) from flow_stream group by 1, 2;
これらは連続ビューと呼ばれ、デフォルトで具体化されます。 状態の保存。
WITH
は追加のパラメーターを渡します。
私の場合、ttl = '3 month'
は、過去3か月間のデータのみを保存し、M
列から日付/時刻を取得する必要があることを意味しますM
バックグラウンドreaper
プロセスreaper
、古いデータをreaper
して削除します。
知らない人のために、minute
関数は秒なしで日付/時刻を返します。 したがって、1分間に発生したすべてのイベントは、集約の結果として同じ時間になります。 - 多くのデータが保存されている場合、サンプリングの日付によるインデックスが役立つため、このようなビューはほとんどテーブルです
create index on viewflow (m desc, action);
PipelineDBを使用する
要確認:データをストリームに挿入し、サブスクライブしているビューから読み取ります
insert into flow_stream VALUES (now(), 'act1', 21); insert into flow_stream VALUES (now(), 'act2', 33); select * from viewflow order by m desc, action limit 4; select now()
リクエストを手動で実行します 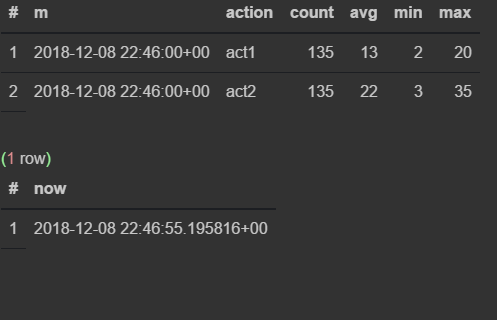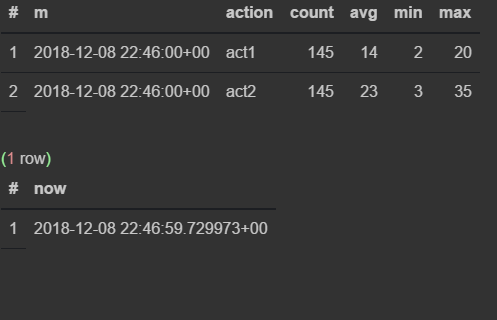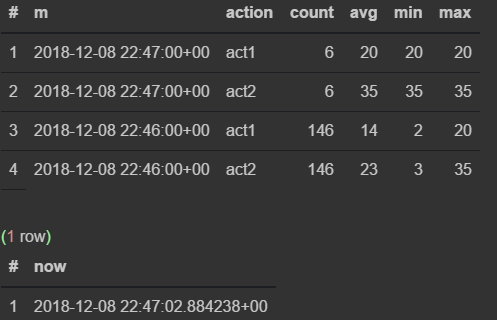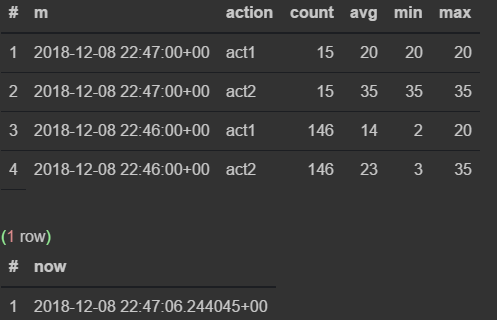
最初に、46分でデータがどのように変化するかを見る
47が来るとすぐに、前のものが更新を停止し、現在の分が刻々と過ぎ始めます。
クエリプランに注意を払うと、元のテーブルにデータが表示されます
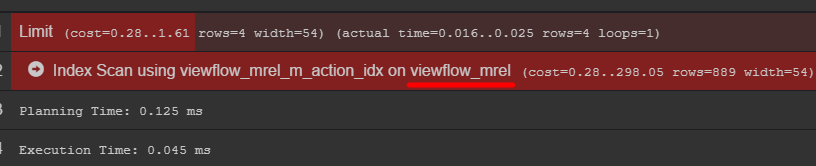
実際にデータを保存する方法を確認することをお勧めします
C#イベントジェネレーター
using Npgsql; using System; using System.Threading; namespace PipelineDbLogGenerator { class Program { private static Random _rnd = new Random(); private static string[] _actions = new string[] { "foo", "bar", "yep", "goal", "ano" }; static void Main(string[] args) { var connString = "Host=localhost;port=5432;Username=postgres;Database=testpipe"; using (var conn = new NpgsqlConnection(connString)) { conn.Open(); while (true) { var dt = DateTime.UtcNow; using (var cmd = new NpgsqlCommand()) { var act = GetAction(); cmd.Connection = conn; cmd.CommandText = "INSERT INTO flow_stream VALUES (@dtmsk, @action, @duration)"; cmd.Parameters.AddWithValue("dtmsk", dt); cmd.Parameters.AddWithValue("action", act); cmd.Parameters.AddWithValue("duration", GetDuration(act)); var res = cmd.ExecuteNonQuery(); Console.WriteLine($"{res} {dt}"); } Thread.Sleep(_rnd.Next(50, 230)); } } } private static int GetDuration(string act) { var c = 0; for (int i = 0; i < act.Length; i++) { c += act[i]; } return _rnd.Next(c); } private static string GetAction() { return _actions[_rnd.Next(_actions.Length)]; } } }
Grafanaでの結論
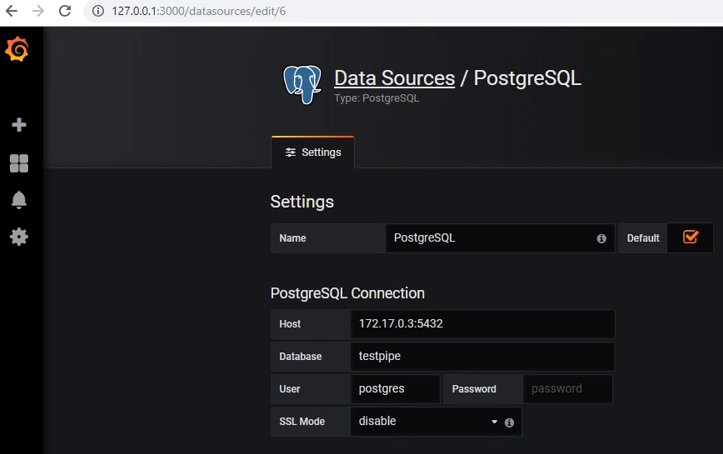
postgresからデータを取得するには、適切なデータソースを追加する必要があります。
新しいダッシュボードを作成し、グラフタイプのパネルを追加します。その後、パネルの編集に進む必要があります。
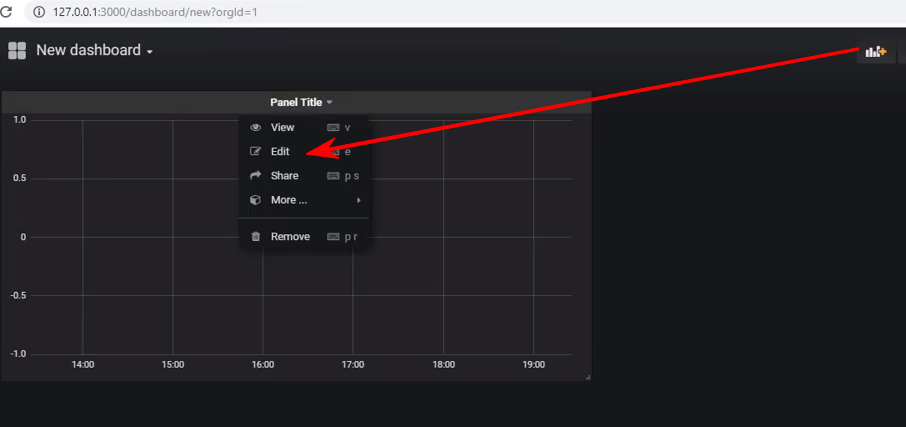
次-データソースを選択し、sql-query writingモードに切り替えて、これを入力します:
select m as time, -- Grafana time count, action from viewflow where $__timeFilter(m) -- , , col between :startdate and :enddate order by m desc, action;
そして、イベントジェネレーターを開始した場合、もちろん通常のスケジュールを取得します
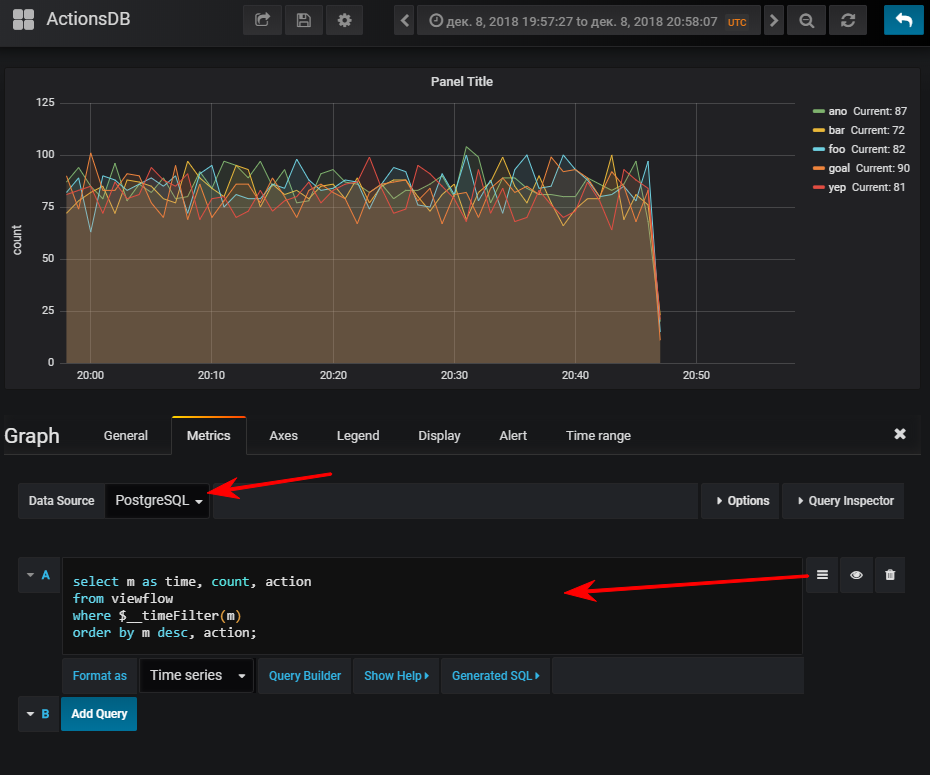
参考までに、インデックスを作成することは非常に重要です。 その使用は、結果のテーブルのボリュームに依存しますが。 短い時間で少数の行を格納する場合、seqスキャンの方が安くなり、インデックスが追加されるだけであることが非常に簡単にわかります。 値を更新するときにロードする
複数のビューを1つのストリームにサブスクライブできます。
パーセンタイルによって実行されるAPIメソッドの数を確認したいとします
CREATE VIEW viewflow_per WITH (ttl = '3 d', ttl_column = 'm') AS select minute(dtmsk) m, action, percentile_cont(0.50) WITHIN GROUP (ORDER BY duration)::smallint p50, percentile_cont(0.95) WITHIN GROUP (ORDER BY duration)::smallint p95, percentile_cont(0.99) WITHIN GROUP (ORDER BY duration)::smallint p99 from flow_stream group by 1, 2; create index on viewflow_per (m desc);
私はgrafanaで同じトリックを行い、以下を取得します。 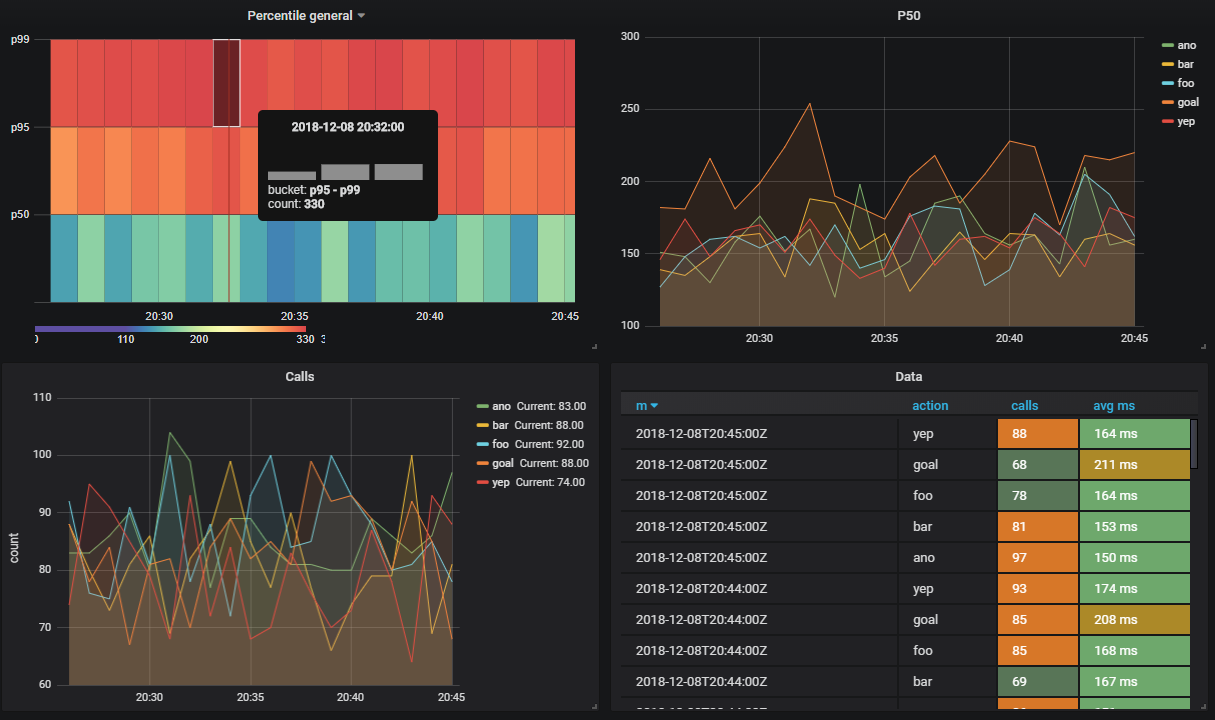
合計
一般的に、問題は機能しており、問題なく動作します。 Dockerの下ではありますが、デモデータベースをアーカイブ(2.3 GB)にダウンロードするのに少し時間がかかりました。
私は注意したい-私はストレステストを行っていません。
公式文書
面白いかもしれません
- Apache Kafkaからストリームへのデータのダウンロードのサポート
- Amazon Kinesisに類似
- ビューは、データ変換のみのために作成できます(ストレージなし)
- PipelineDBクラスター -商用バージョンがあります。 その中で、シャード間でビューを分散できます。 クラスター決定ドックの詳細