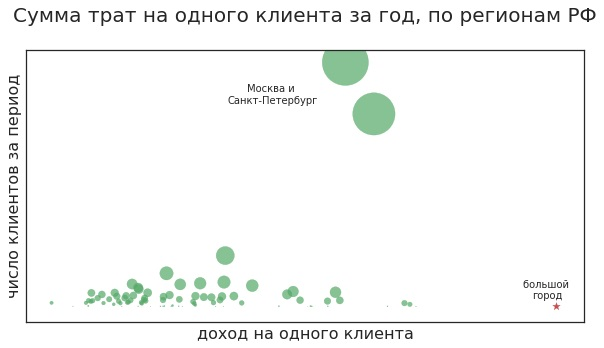
どんな質問ですか? たとえば、クライアントは離れますか? 店舗に適切な製品がない場合、多くの場合、顧客は去ります。 たとえば、女性は毎月1万ルーブルの特別なクリームを購入し、2つの化粧品店から選択できます。 そのうちの1つでは、必要な製品が欠落していることが多く、2つ目では可用性に問題はありません。 おそらくもう少し高価ですが、彼女は常に2番目に購入します。
別の差し迫った質問:スタッフの仕事を最適化する方法は? たとえば、レジ係や営業コンサルタントの勤務シフトを計画する必要があります。 1つの方法は、統計分析を使用することです。 アナリストは、曜日に応じてクライアントのアクティビティを推定し、土曜日に最も多く購入し、金曜日と日曜日に少し少なくなることを確認しています。 この仮説は統計的検定によって確認され、結論は経営陣に伝えられます。
ただし、このような分析では、要因の多くの組み合わせが考慮されない場合があります。 たとえば、3月7日が水曜日の場合、金曜日よりもこの日に多く購入します(通常、金曜日は他の平日よりも人気のある日です)。 そして卒業? それとも地元の休日? 要因が多ければ多いほど、単純なルールの助けを借りてそれらすべてを考慮することは難しくなります。 また、ルールを無限に複雑化する代わりに、特定の日の需要を予測するモデルを構築できます。
非食品小売業のプロジェクト
この場合、顧客ベース(約250万人)を分析し、次の2週間でどれが店舗に戻るかを予測する必要がありました。 CatBoostライブラリの2つの方法、CatBoostClassifierとCatBoostRegressorを使用して、最初の方法で聴衆の構成を予測し、2番目の方法で次の2週間で最も人気のある製品を選択しました。 CatBoostは、プロジェクトの最初の段階で登場しました。カテゴリ属性を操作するための新しいアプローチでした。 また、お客様の製品範囲には多くのカテゴリ機能が含まれているため、喜んで新製品を試してみました。 パラメーターを選択すると、モデルはすぐに正確な予測で期待に応えました。 CatBoostが今日最も人気のある勾配ブースティングモデルの1つであるのも不思議ではありません。
モデルでは、2017年の統計を取りました。
- 小切手:小切手から誰がボーナスカードを所有しているのか、購入が行われたとき、購入したもの、サイズを割引する、購入する、または払い戻す。
- 人口統計:クライアントの居住地と都市、生年月日と性別、電話または郵便による郵送への同意。
- 商品:どのカテゴリまたはセグメントに購入、スコープなどが含まれるか
ノイズのデータ(販売者のカード、返品、商品ではなくサービスの購入)をクリーンアップし、必要な基準(割引率、年齢)を計算しました。 その後、各顧客の最大および最小のチェック、平均、中央値、最大値引、入店回数、購入したカテゴリの商品数を計算しました。 これらのパラメーターは、先週、2週間、1か月、3か月の間隔でカウントされました。 このような綿密な作業により、高い予測精度でモデルを構築することが可能になりました。
モデルの集計データと開始された計算。 最初のモデルでは、次の2週間でどの購入者が来るかを予測し、2番目のモデルでは、特定の人が購入する製品(記事のレベルまで)を推奨しました。 ちなみに、特定の記事の人気を予測するための要件は、タスクを非常に複雑にしました(通常、ビジネスのニーズ予測は、位置ではなく商品のカテゴリと名前に基づいています)。
モデルがターゲットメーリング用に推奨するクライアントは、1回の訪問で中央値チェックが大きく、分析期間中、他のクライアントよりも高い金額を購入しました。
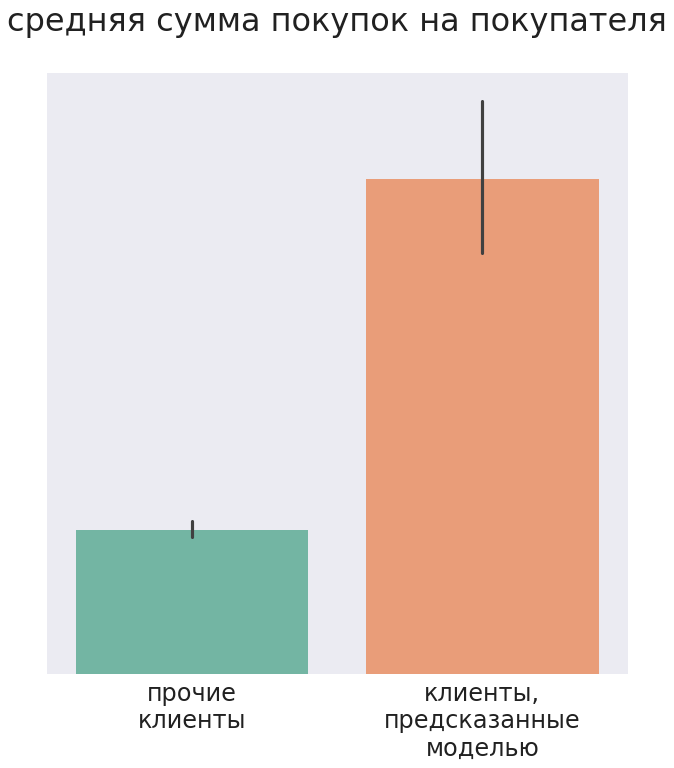
その結果、郵送後、顧客の約30%がモデルで予測された3つの製品のうち少なくとも1つを購入しました。
これで、会社は販売をより正確に予測できるようになります。小売業者は、近い将来誰が彼に来て、何を買うかを知っています。 これは、ロジスティクスを最適化するだけでなく、関連コストを削減するのにも役立ちます。 たとえば、特定のクライアントが通常冬に何も買わない場合、1月にSMSを送信する必要はありません。 また、モデルは郵送を最適化します。予測に基づいた専門家は、誰が電子メールを送信すべきか、誰に緊急SMSかをすぐに理解します。
落とし穴
それらはMLタスクにあります-それらは私たちのものでした。 たとえば、製品の推奨メールが売上の増加に役立つかどうかをテストしました。 このため、予測された顧客セグメントは3つのグループに分けられました。
- コントロール-ニュースレターを受信しませんでした。
- アラーム付きグループ-ストアから一般的なテキストを受け取りました。
- 推奨事項を含むグループ-モデルによって予測された3つの特定の製品を含むSMSを受信しました。
推奨事項を受け取った人は、ニュースレターを受け取っていない顧客よりも少ない金額で購入したことがわかりました。 平均請求額と購入した商品の量は少なかった。 T検定では、差が統計的に有意であることが示されました(pvalue = 0.017)。
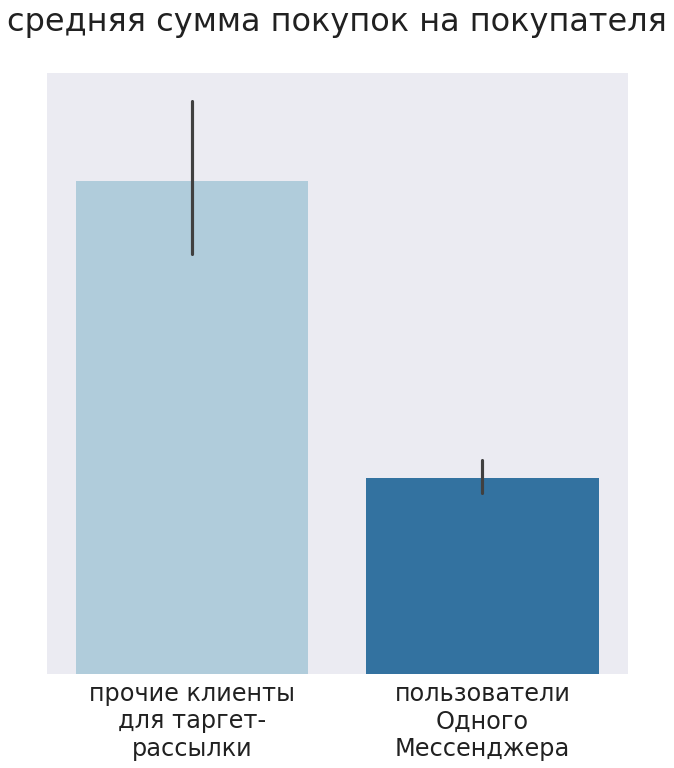
控えめに言っても、そのような結果は誰もがやる気をなくさせます。 彼らは理由を探し始め、店舗が特定のメッセンジャーの顧客にメッセージを送信し、私たちのセグメントのそのユーザーは最初に他の顧客よりも少ないものを購入したことがわかりました。 顧客のマーケターでさえこれを知りませんでした。 そのため、実験は不正確であることが判明しましたが、その結果に応じて、パラメーター「メッセンジャーユーザー」をモデルに追加しました。 このケースは、顧客とのコミュニケーションのためにチャネルを慎重に選択する方法を示しています。
他にどんな結論を引き出すことができますか?
- データはあまりありません。
- アナリストの側からの見方が新鮮なアイデアにつながることもあります。
顧客のセグメンテーション
データ分析を使用すると、以前利用可能な情報に隠されていたパターンを検出できます。 良い例は、RFMセグメンテーション(Recency Frequency Monetary)を使用した顧客グループとMLアルゴリズムを使用したセグメンテーションの比較です。
RFMセグメンテーションでは、3つの主要な指標を使用します。
- 最後の購入の処方箋
- 期間の購入頻度
- クライアントが費やした金額。
これらのデータに基づいて、主なグループは区別されます:「スクワンダー」、「忠実な顧客」、「ほとんど失われた顧客」など。 また、マーケティング担当者は、特定のニュースレターに目的のターゲットグループを既に含めているか、このグループ専用のオファーを行っています。
たとえば、RFMセグメンテーションを使用して、顧客セグメントを選択し、3次元空間のポイントとして表すことができます。
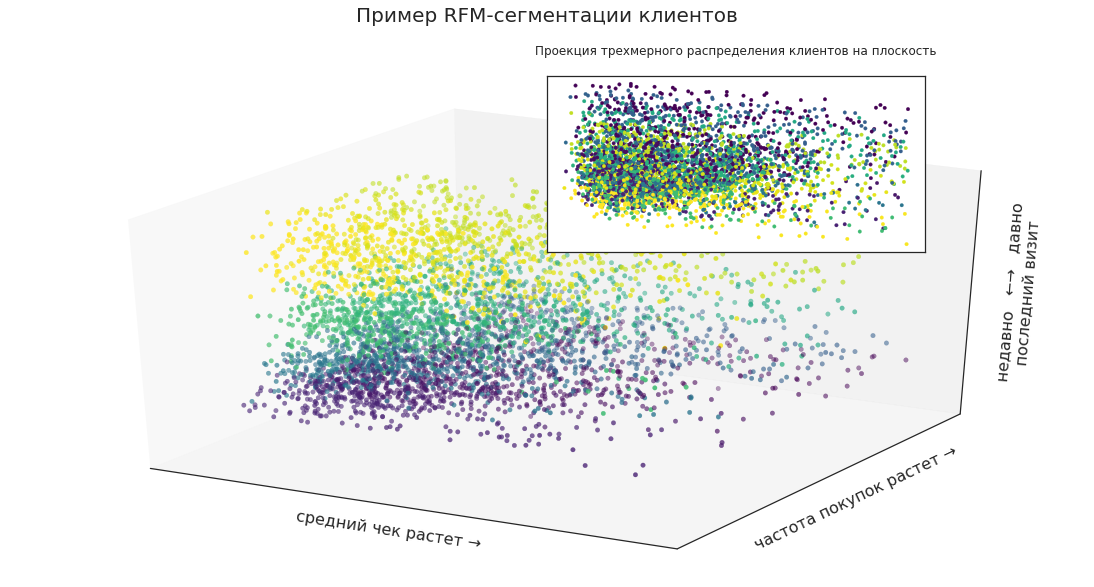
これにより、顧客の総質量における特定のグループの位置、その割合、および変化のダイナミクスを視覚的に確認できます。
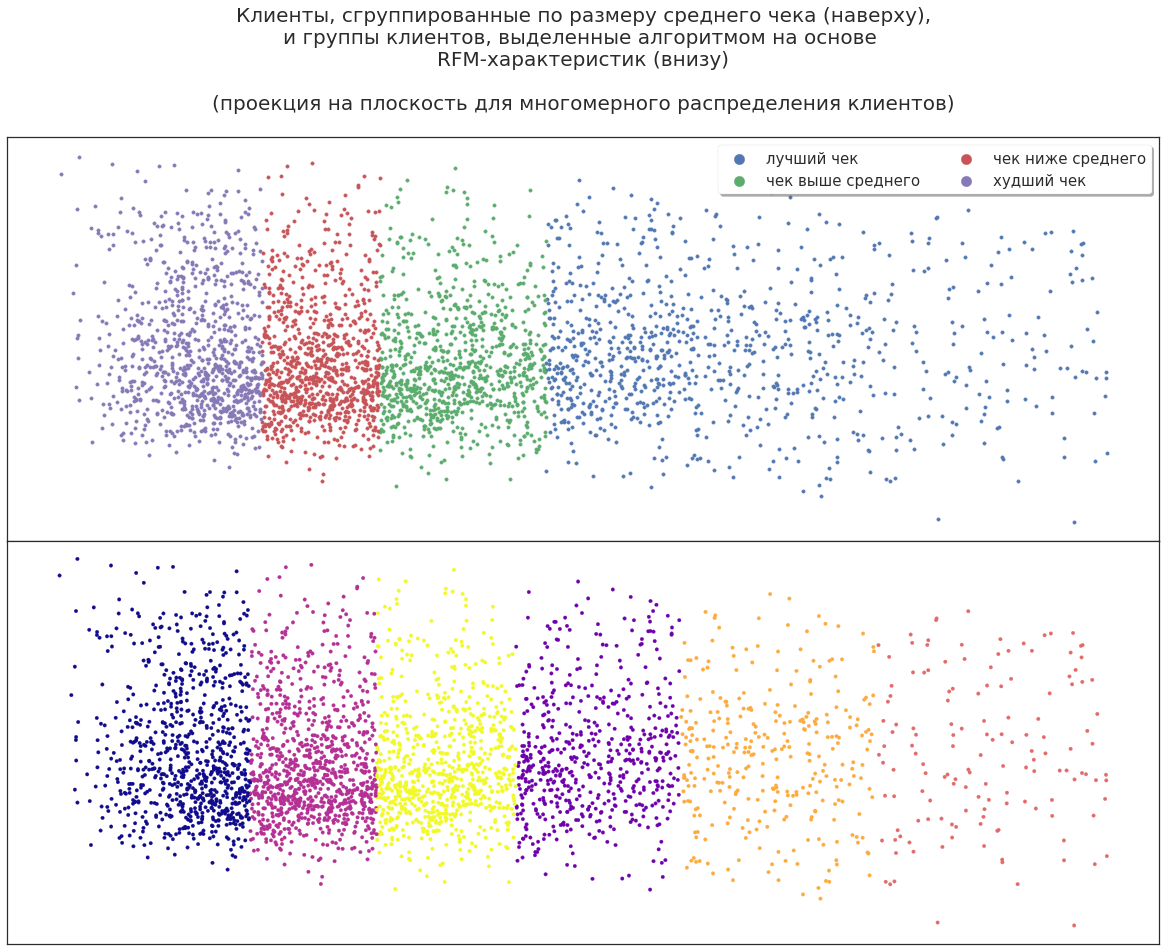
次に、平面上のセグメントの3次元分布を投影します。 クライアントは、会社がもたらした収入で割って、最も収益性の高いものをマーケティングキャンペーンに含めることができますが、これは効果的な計画に十分ですか?
そのようなデータであっても、機械学習アルゴリズムは追加の可能性を見つけます。顧客を新しい大規模なグループに分割します。 このパーティションを分析して、アルゴリズムがこのようにクライアントを分割した理由を見つけることができます。 たとえば、収益性の高い顧客の中には、買い物に同行して割引カードを使用する専門家がいます。 カードを友人や知人と積極的に共有する人もいます。 つまり、MLを最初に使用した後、すべて同じデータに基づいて顧客に関する追加情報を取得できます。
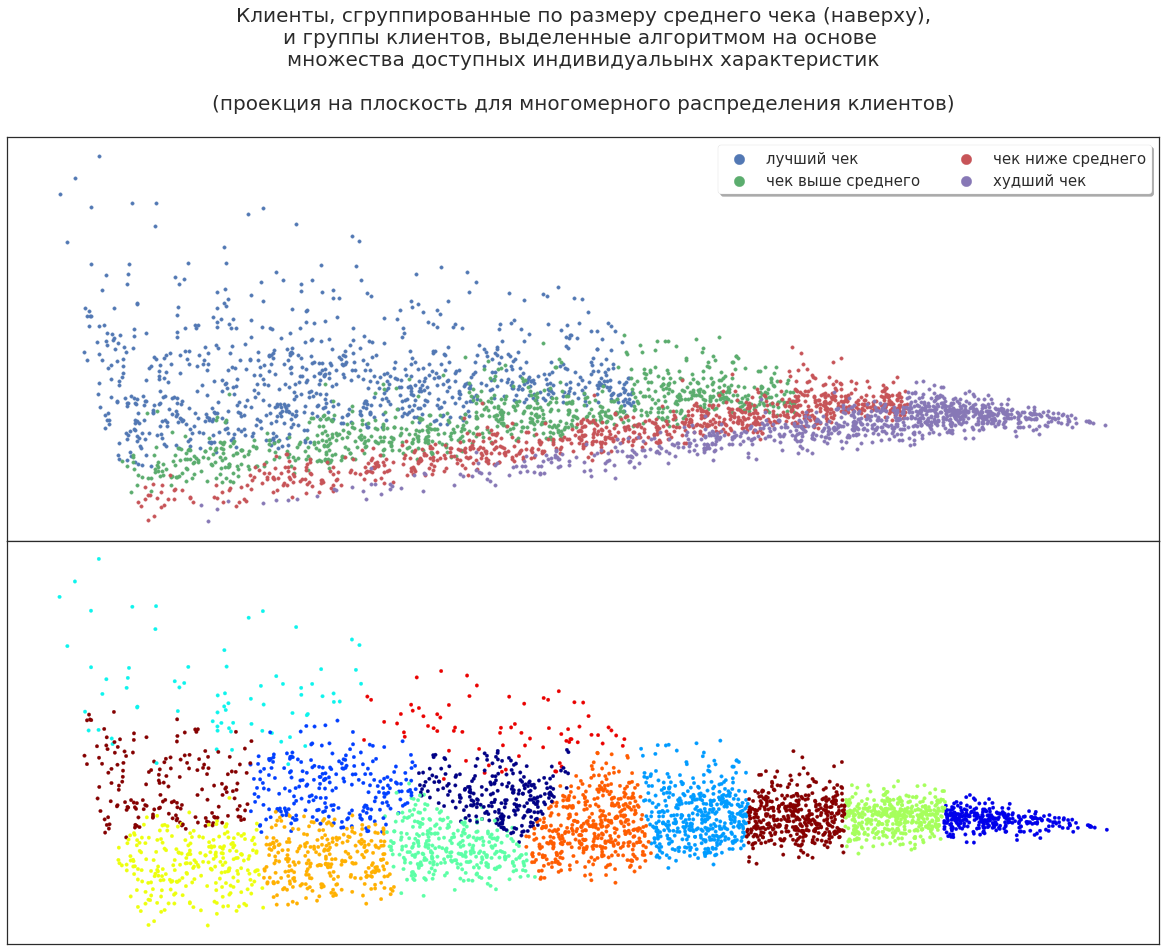
顧客の特性セットを拡張しましょう:性別、年齢、行動などを追加します。 アルゴリズムはどのようにバイヤーを配布しますか?
たとえば、最高の顧客(最も収益性の高い)と彼らの「隣人」の両方をカバーするグループがあり、利益が少なくなります。 アルゴリズムがこのグループを割り当てた理由は、アナリストの疑問です。 おそらく、追加の刺激を与えられたこれらのクライアントは、より大きな収益性を示すでしょう。 または、逆に、これらのクライアントは特に有望ではなく、収益性の増加は偶然の逸脱でした-それらを刺激することはさらに無意味です。 さまざまな理論を提唱できますが、実験的に検証する必要があります。
倉庫計画-販売予測
さらに、プロジェクトにはいくつかの開発オプションがあります。 たとえば、次の期間の特定の店舗での購入を予測できます。 その後、店舗管理者は、中央倉庫から必要な商品を時間通りに注文できるようになります。
特定のアウトレットでの購入の分析は、ディスプレイウィンドウでの商品の表示を策定するのに役立ちます。 たとえば、多くの男性バイヤーが店に来た場合、男性製品を扱う部門は遠い角に置かないでください。
いわゆる店舗の共食いを忘れないでください。 つまり、同じネットワークの2つの販売ポイントが近くにある場合(たとえば、同じ通りの異なる端にある場合)、1つは顧客を引き離し、2つ目はアイドル状態になります。 このような現象を追跡し、それに関するシグナルを送るモデルを作成できます。
***
要するに、機械学習は多くのことができる強力なツールです。 多くの場合、モデルを構築するときに、ビジネスユーザーでさえも知らなかった明白でないパターンが明らかになります。 ただし、モデルの品質はデータの品質と量に大きく依存します。
ソフトウェア、Jet Infosystemsの開発および実装のための総局のアナリスト