光学式文字認識(OCR)は、デジタル形式で印刷されたテキストを取得するプロセスです。 デジタルデバイスで古典的な小説を読んだり、病院のコンピューターシステムから古い医療記録をピックアップするように医師に依頼した場合は、おそらくOCRを使用したでしょう。
OCRは、以前は静的なコンテンツを編集可能、検索可能、および共有可能にしました。 しかし、デジタル化が必要な多くのドキュメントには、コーヒーの染み、角が丸まったページ、および印刷されたドキュメントの一部がデジタル化されていないしわが多く含まれています。
誰もが、ストレージに保存されている何百万もの古い本があることを長い間知っています。 これらの本の使用は老朽化と衰退のため禁止されており、したがってこれらの本のデジタル化は非常に重要です。
この論文では、ノイズからテキストをクリアし、画像内のテキストを認識し、テキスト形式に変換するタスクを検討しています。

トレーニングには、144枚の写真が使用されました。 サイズは異なる場合がありますが、合理的な範囲内であることが望ましいです。 画像はPNG形式である必要があります。 画像を読み取った後、二値化が使用されます-カラー画像を白黒に変換するプロセス。つまり、各ピクセルは0〜255の範囲に正規化されます。0は黒、255は白です。
たたみ込みネットワークをトレーニングするには、現在よりも多くの画像が必要です。 画像を部分に分割することが決定されました。 トレーニングセットはさまざまなサイズの画像で構成されているため、各画像は448x448ピクセルに圧縮されました。 結果は、448x448ピクセルの解像度で144枚の画像でした。 次に、それらすべてをサイズが112x112ピクセルの重複しないウィンドウにカットしました。

したがって、144個の初期画像のうち、トレーニングセット内の約2304個の画像が取得されました。 しかし、これでは十分ではありませんでした。 優れた畳み込みネットワークのトレーニングには、さらに多くの例が必要です。 この結果、最良のオプションは、写真を90度回転してから、180度と270度回転することでした。 その結果、サイズ[16,112,112,1]の配列がネットワーク入力に提供されます。 16は画像の数、112は各画像の幅と高さ、1はカラーチャンネルです。 トレーニング用の9216の例が判明しました。 これは畳み込みネットワークを訓練するのに十分です。
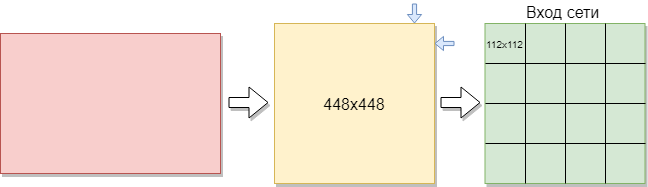
各画像のサイズは112x112ピクセルです。 サイズが大きすぎると、計算の複雑さが増し、それに応じて、応答速度の制限に違反することになり、この問題のサイズの決定は選択方法によって解決されます。 選択したサイズが小さすぎると、ネットワークはキーサインを識別できなくなります。 各画像は白黒形式であるため、1つのチャネルに分割されます。 カラー画像は、赤、青、緑の3つのチャネルに分かれています。 白黒の画像があるため、各画像のサイズは112x122x1ピクセルです。
まず第一に、準備され処理された画像上で畳み込みニューラルネットワークを訓練する必要があります。 このタスクでは、U-Netアーキテクチャが選択されました。
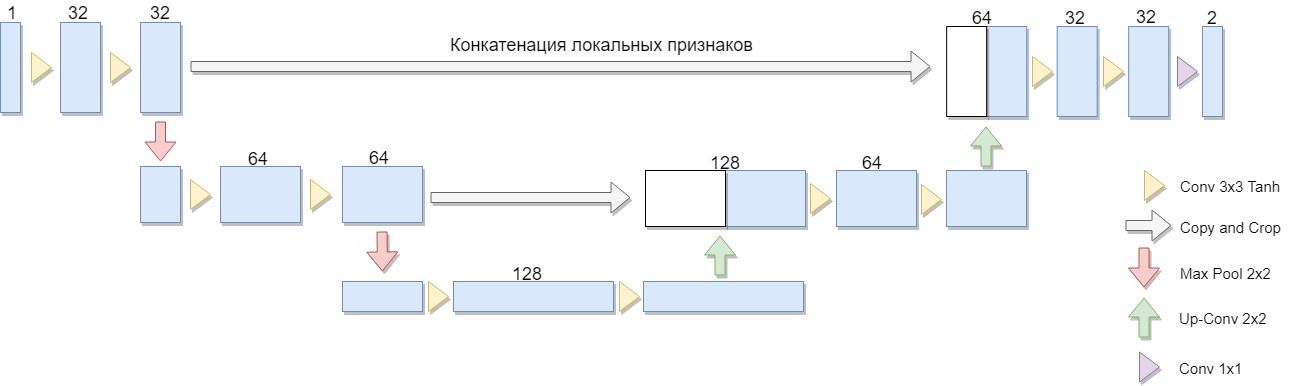
アーキテクチャの縮小バージョンが選択され、2つのブロックのみで構成されました(4つのオリジナルバージョン)。 重要な考慮事項は、このようなアーキテクチャまたは類似のアーキテクチャで、よく知られた二値化アルゴリズムの大規模なクラスが明示的に表現されるという事実でした(例として、標準偏差を平均偏差モジュールに置き換えることでNiblackアルゴリズムを変更できます。この場合、ネットワークは特に簡単に構築されます)。
このアーキテクチャの利点は、ネットワークをトレーニングするために、少数のソースイメージから十分な量のトレーニングデータを作成できることです。 さらに、ネットワークの畳み込みアーキテクチャにより、重みの数は比較的少ない。 しかし、いくつかのニュアンスがあります。 特に、使用される人工ニューラルネットワークは、厳密に言えば、2値化の問題を解決しません:元の画像の各ピクセルに対して、0から1の数値を関連付けます。これは、このピクセルがクラス(意味のある塗りつぶしまたは背景)の1つに属し、必要な度合いを特徴付けますそれでも最終的なバイナリ回答に変換します。 [1]
U-Netは、圧縮および解凍パスとそれらの間の「転送」で構成されます。 このアーキテクチャの圧縮パスは、2つのブロックで構成されます(4つのオリジナルバージョン)。 各ブロックには、3x3フィルターを使用した2つの畳み込み(畳み込み後にTanhアクティベーション関数を使用)と2x2のフィルターサイズを使用した2段階のプーリングがあります。各ステップダウンのチャンネル数は2倍になります。
スクイージングパスも2つのブロックで構成されます。 これらはそれぞれ、フィルターサイズが2x2の「スイープ」、チャネル数を半分にする、圧縮パスからの対応するクリップされた機能マップとの連結(「転送」)、および3x3フィルターによる2つの畳み込み(畳み込み後にTanhアクティベーション関数を使用)で構成されます。 次に、最後のレイヤーで1x1コンボリューション(Sigmoidアクティベーション関数を使用)を実行して、出力のフラットイメージを取得します。 畳み込みごとに境界ピクセルが失われるため、連結中にフィーチャマップをトリミングすることが不可欠であることに注意してください。 Adamは確率的最適化の方法として選ばれました。
一般に、アーキテクチャとは、画像の空間解像度を下げる畳み込み+プーリングレイヤーのシーケンスであり、事前に画像データと組み合わせて畳み込みの他のレイヤーを通過させることで画像を増やします。 したがって、ネットワークは一種のフィルターとして機能します。 [2]
テストサンプルは類似の画像で構成され、違いはノイズテクスチャとテキストのみでした。 このイメージでネットワークテストが行われました。

畳み込みニューラルネットワークの出力では、サイズが[16,112,112,1]の数値の配列が取得されます。 各数値は、ネットワークによって処理される個別のピクセルです。 画像は、以前と同様に112x112ピクセルの形式で、断片に分割されています。 彼女は元の外観を裏切る必要があります。 取得した画像を1つの部分に結合します。その結果、画像のフォーマットは448x448になります。 次に、配列の各数値に255を掛けて、0〜255の範囲を取得します。0は黒、255は白です。 画像を元のサイズに戻します。以前のように、圧縮されていました。 結果は、図の下の写真です。

この例では、畳み込みネットワークがほとんどのノイズに対処し、効率的であることが証明されています。 しかし、写真がより曇っていて、見逃したノイズが見えることがはっきりと見えます。 将来、これはテキスト認識の精度に影響を与える可能性があります。
この事実に基づいて、別のニューラルネットワーク-多層パーセプトロンを使用することが決定されました。 予想される結果では、ネットワークは画像内のテキストをより明確にし、畳み込みニューラルネットワークから欠落しているノイズを除去する必要があります。
畳み込みネットワークによって既に処理された画像は、多層パーセプトロンの入力に送信されます。 この場合、ネットワークは画像の処理方法が異なるため、このネットワークのトレーニングサンプルは畳み込みネットワークのサンプルとは異なります。 畳み込みネットワークはメインネットワークと見なされ、画像内のノイズのほとんどを除去しますが、多層パーセプトロンは畳み込みネットワークが実行できなかった処理を行います。
以下に、多層パーセプトロンのトレーニングセットの例をいくつか示します。

画像データは、畳み込みネットワークのトレーニングサンプルを多層パーセプトロンで処理することにより取得されました。 同時に、パーセプトロンは同じサンプルでトレーニングされましたが、少数の例と少数の時代でトレーニングされました。
パーセプトロンのトレーニングでは、36枚の画像が処理されました。 ネットワークはピクセルごとにトレーニングされます。つまり、画像の1ピクセルがネットワーク入力に送信されます。 ネットワークの出力では、1つの出力ニューロン、つまり1つのピクセル、つまりネットワーク応答も取得します。 処理の精度を高めるために、29個の入力ニューロンが作成されました。 また、畳み込みネットワークによる処理後に得られた画像には、28個のフィルターが重ねられています。 結果は、異なるフィルターを持つ29枚の画像です。 各29画像から1つのピクセルをネットワーク入力に送信し、ネットワーク出力、つまりネットワーク応答では1つのピクセルのみを受信します。
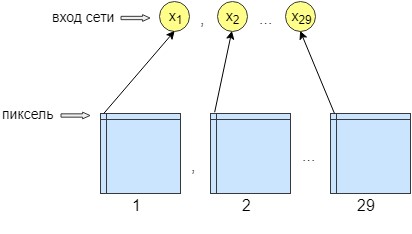
これは、より良いトレーニングとネットワーキングのために行われました。 その後、ネットワークは画像の精度とコントラストを向上させ始めました。 また、畳み込みネットワークをクリアできなかった小さなエラーをクリーンアップします。
その結果、ニューラルネットワークには29個の入力ニューロンがあり、各画像から1ピクセルずつです。 実験の後、必要な隠れ層は1つだけで、その中に500個のニューロンがあることがわかりました。 ネットワークから出る方法は1つしかありません。 トレーニングはピクセルごとに行われたため、ネットワークはn * m回アクセスされました。nはそれぞれ画像の幅で、mは高さです。

2つのニューラルネットワークで画像を順次処理した後、残っている主なことはテキストを認識することです。 このため、既製のソリューション、つまりPythonライブラリPytesseractが採用されました。 Pytesseractは、真のPythonバインディングを提供しません。 むしろ、tesseractバイナリの単純なラッパーです。 この場合、tesseractはコンピューターに個別にインストールされます。 Pytesseractはイメージをディスク上の一時ファイルに保存してから、tesseractバイナリファイルを呼び出し、結果をファイルに書き込みます。
このラッパーはGoogleによって開発されたもので、無料で使用できます。 独自の目的と商用目的の両方で使用できます。 このライブラリは、インターネットに接続せずに動作し、認識のために多くの言語をサポートし、その速度に感心します。 そのアプリケーションは、さまざまな一般的なアプリケーションで見つけることができます。
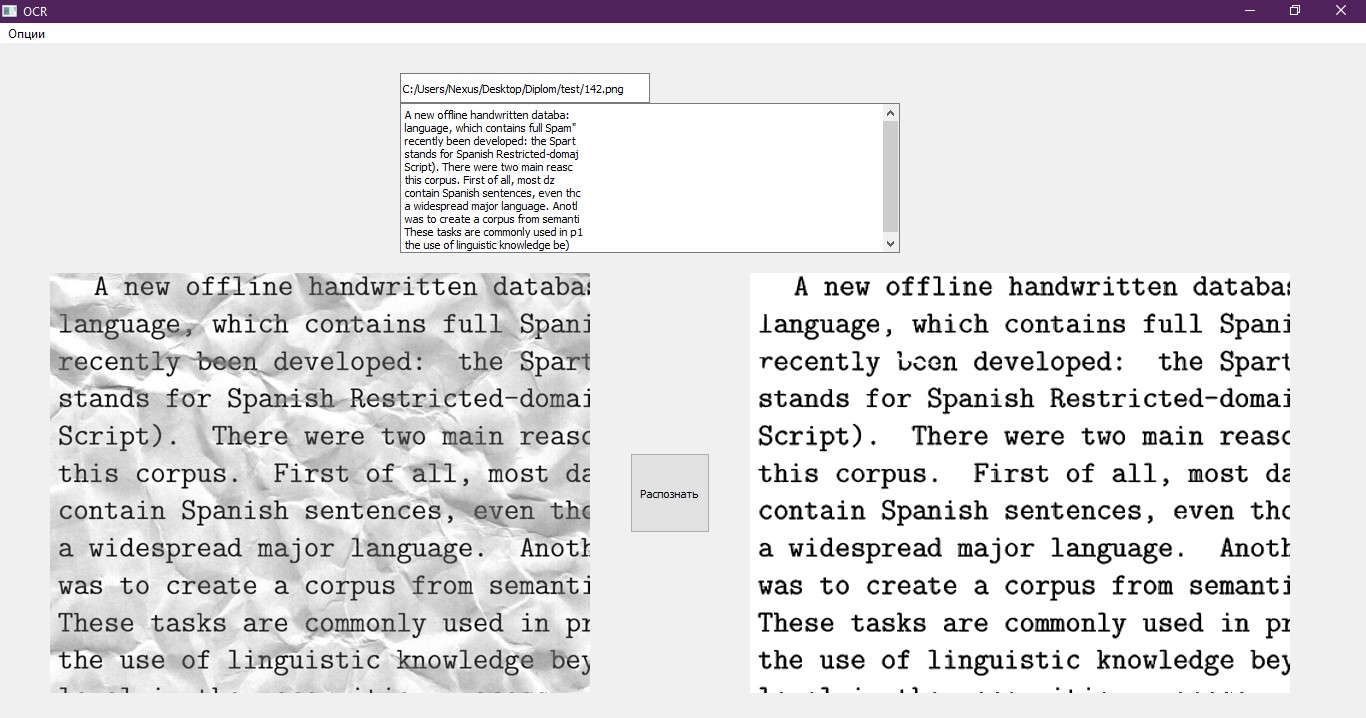
残っている最後の項目は、認識されたテキストを、処理に適した形式でファイルに書き込むことです。 これには、プログラムが終了した後に開く通常のノートブックを使用します。 また、テキストはテストインターフェイスに表示されます。 インターフェイスの良い例。
参照:
- SmartEngines [電子リソース]のチームのドキュメントを承認するための国際競争での勝利の物語。 アクセスモード: https : //habr.com/company/smartengines/blog/344550/
- ニューラルネットワークを使用した画像のセグメンテーション:U-Net [電子リソース]。 アクセスモード: http : //robocraft.ru/blog/machinelearning/3671.html