Ludum Dareの準備をして、ピクセルシェーダーを使用した単純なゲームを作成したことがあります(他はPhaserエンジンに持ち込まれませんでした)。
シェーダーは、グラフィックカードで実行されるGLSL Cのようなプログラムです。 シェーダーには2つのタイプがあります。この記事では、ピクセルシェーダー(「フラグメント」、フラグメントシェーダーでもあります)について説明します。
color = pixelShader(x, y, ...other attributes)
つまり 出力画像の各ピクセルに対してシェーダーが実行され、その色が決定または調整されます。
ハブの別の記事( https://habr.com/post/333002/)で紹介記事を読むことができます。
テスト後、私はリンクを友人に投げ、彼から「これは普通ですか?」という質問のスクリーンショットを受け取りました。
いいえ、それは正常ではありませんでした。 シェーダーコードを注意深く調べたところ、計算エラーが見つかりました。
if (t < M) { realColor = mix(color1,color2, pow(1. - t / R1, 0.5)); }
なぜなら R1はMより小さいため、場合によっては、powの最初の引数で、ゼロより小さい数値が取得されました。 負の数の平方根は、少なくともGLSL規格にとっては不思議なことです。 私のビデオカードは混乱せず、どういうわけかこの位置から抜け出しました(パウ0から戻したようです)が、友人にとっては読みやすいことがわかりました。
そして、私は考えました:将来私はそのような問題を避けることができますか? 間違い、特にローカルで再現されていない間違いから安全な人はいません。 GLSLの単体テストは作成できません。 同時に、シェーダー内の変換は非常に単純です-乗算、除算、正弦、余弦...各変数の値を追跡し、どのような状況でも許容値を超えないようにすることは本当に不可能ですか?
そこで、GLSLの静的分析を試みることにしました。 それの由来-あなたはカットの下でそれを読むことができます。
すぐに警告します。完成品は入手できませんでした。教育用のプロトタイプのみです。
予備分析
このトピックに関する既存の記事を少し調べて(そして、そのトピックがValue Range Analysisと呼ばれることを同時に発見しました)、GLSLがあり、他の言語がなかったことを嬉しく思いました。 自分で判断する:
- 「ダイナミクス」なし-関数、インターフェース、自動的に推測される型などへの参照
- 直接メモリ処理なし
- モジュールなし、リンク、遅延バインディング-シェーダーソースコード全体が完全に利用可能
入力値の範囲は一般的によく知られています - いくつかのデータ型、およびそれらはフロートを中心に展開します。 int / boolはめったに使用されず、それらに従うことはそれほど重要ではありません
- ifsとloopsはめったに使用されません(パフォーマンスの問題のため)。 ループを使用する場合、多くの場合、配列を通過したり、特定の効果を数回繰り返したりするための単純なカウンターです。 誰もGLSLでそのような恐怖を書かないでしょう(私は願っています)。
// - https://homepages.dcc.ufmg.br/~fernando/classes/dcc888/ementa/slides/RangeAnalysis.pdf k = 0 while k < 100: i = 0 j = k while i < j: i = i + 1 j = j – 1 k = k + 1
一般に、GLSLの制限を考えると、タスクは解決可能と思われます。 主なアルゴリズムは次のとおりです。
- シェーダーコードを解析し、変数の値を変更する一連のコマンドを作成します
- 変数の初期範囲を把握し、シーケンスを実行し、変数が変更されたときに範囲を更新する
- 範囲が特定の境界に違反している場合(たとえば、負の数が入力される場合、または1より大きい値が赤のコンポーネントの「出力色」gl_FragColorになる場合)、警告を表示する必要があります
使用技術
ここで私は長く辛い選択をしました。 一方で、私の主なスコープはWebGLシェーダーをチェックすることなので、開発中にブラウザーですべてを実行するためにjavascriptを使用しないのはなぜですか。 一方、私は長い間Phaserを降りて、UnityやLibGDXのような別のエンジンを試すことを計画しています。 シェーダーもありますが、javascriptはなくなります。
そして第三に、仕事は主に娯楽のために行われました。 そして、世界で最高のエンターテイメントは動物園です。 したがって:
- JavaScriptで行われるGLSLコードの解析。 ASTでGLSLを解析するためのライブラリがすぐに見つかり、テストUIがWebベースであることに慣れているようです。 ASTは一連のコマンドに変わり、...
- ... 2番目の部分は、C ++で記述され、WebAssemblyにコンパイルされます。 私はこの方法を決めました:C ++ライブラリを使用してこのアナライザーを突然他のエンジンに固定したい場合は、これを最も簡単に行う必要があります。
- Visual Studio CodeをメインIDEとして使用し、一般的には満足しています。 幸福のために何かが必要です-主なことは、Ctrl +クリックが機能し、入力時にオートコンプリートする必要があることです。 どちらの関数もC ++とJSの両方で正常に機能します。 まあ、異なるIDEを相互に切り替えないことも素晴らしいです。
- C ++をコンパイルするために、WebAssemblyはcheerpツールを使用します(有料ですが、オープンソースプロジェクトでは無料です)。 コードの最適化以外の問題を除いて、その使用に関して問題は発生しませんでしたが、ここで誰のせいなのかわかりません-cheerp自体またはそれによって使用されるclangコンパイラー。
- C ++での単体テストでは、古き良きgtestを使いました
- バンドルでjsをビルドするには、いくつかのマイクロバンドルが必要でした。 彼は「1 npmパッケージといくつかのコマンドラインフラグが必要」という私の要件を満たしていましたが、同時に問題もありませんでした。 受信したjavascriptをメッセージ
[Object object]
で解析中にエラーが発生すると、時計がクラッシュするとしましょう。これはあまり役に立ちません。
すべて、今、あなたは行くことができます。
モデルについて簡単に
アナライザーは、シェーダーで検出された変数のリストをメモリーに保持し、それぞれについて、現在可能な値の範囲( [0,1]
または[1,∞)
)を保存します。
アナライザーは、次のようなワークフローを受け取ります。
cmdId: 10 opCode: sin arguments: [1,2,-,-,3,4,-,-]
ここで、sin関数が呼び出され、id = 3および4の変数がそれに入力され、結果が変数1および2に書き込まれます。この呼び出しはGLSL番目に対応します。
vec2 a = sin(b);
空の引数(「-」としてマーク)に注意してください。 GLSLでは、ほとんどすべての組み込み関数がさまざまな入力タイプのセットに対してオーバーロードされています。 sin(float)
、 sin(vec2)
、 sin(vec3)
、 sin(vec4)
ます。 便宜上、オーバーロードされたすべてのバージョンを1つの形式sin(vec4)
この場合はsin(vec4)
ます。
アナライザは、次のように各変数の変更のリストを出力します
cmdId: 10 branchId: 1 variable: 2 range: [-1,1]
これは、「ブランチ1の10行目の変数2の範囲は-1から1までの範囲にある」ことを意味します(後で説明するブランチ)。 これで、ソースコードの値の範囲を美しくハイライトできます。
良いスタート
ASTツリーがすでにコマンドのリストに変わり始めたら、標準の関数とメソッドを実装するときが来ました。 それらは非常に多くあります(また、私が上で書いたように、それらには多数のオーバーロードがあります)が、一般に、予測可能な範囲変換があります。 このような例では、すべてが明らかになるとしましょう。
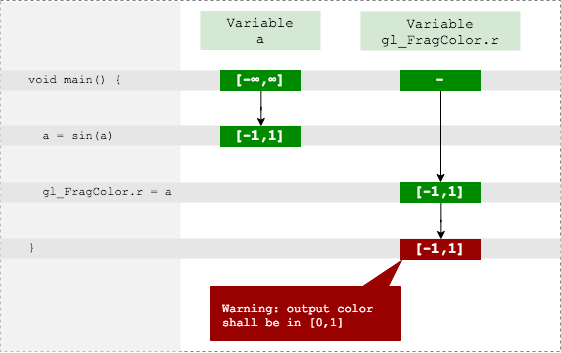
uniform float angle; // -> (-∞,∞) //... float y = sin(angle); // -> [-1,1] float ynorm = 1 + y; // -> [0,2] gl_FragColor.r = ynorm / 2.; // -> [0,1]
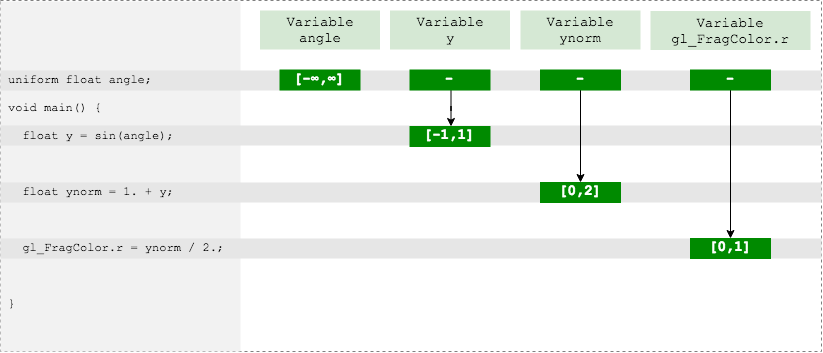
出力色の赤チャネルは許容範囲内であり、エラーはありません。
より多くの組み込み関数をカバーする場合、シェーダーの半分については、このような分析で十分です。 しかし、後半はどうですか?条件、ループ、関数についてはどうでしょうか?
枝
シェーダーを例にとってみましょう。
uniform sampler2D uSampler; uniform vec2 uv; // [0,1] void main() { float a = texture2D(uSampler, uv).a; // -> [0,1] float k; // -> ? if (a < 0.5) { k = a * 2.; } else { k = 1. - a; } gl_FragColor = vec4(1.) * k; }
変数a
はテクスチャから取得されるため、この変数の値は0〜1になります。しかし、 k
はどの値を取ることができますか?
簡単な方法で「ブランチを統一する」ことができます-各ケースの範囲を計算し、合計を出します。 if分岐については、 k = [0,2]
を取得し、else分岐については、 k = [0,1]
を取得します。 組み合わせると[0,2]
になり、エラーを出す必要があります。なぜなら 1より大きい値はgl_FragColor
出力色にgl_FragColor
ます。
ただし、これは明らかな誤報であり、静的アナライザーの場合は誤検知よりも悪いことはありません。「オオカミ」の最初の叫びの後、そして確実に10回後にオフにされない場合。
したがって、両方のブランチを別々に処理する必要があり、両方のブランチで変数a
範囲を明確にする必要があります(正式には変更されていませんが)。 これは次のようなものです。
ブランチ1:
if (a < 0.5) { //a = [0, 0.5) k = a * 2.; //k = [0, 1) gl_FragColor = vec4(1.) * k; }
ブランチ2:
if (a >= 0.5) { //a = [0.5, 1] k = 1. - a; //k = [0, 0.5] gl_FragColor = vec4(1.) * k; }
したがって、アナライザーは、範囲に応じて異なる動作をする特定の条件に遭遇すると、ケースごとにブランチ(ブランチ)を作成します。 いずれの場合も、彼はソース変数の範囲を絞り込み、コマンドのリストに進みます。

この場合の分岐は、if-else構造に関連していないことを明確にする価値があります。 変数の範囲がサブ範囲に分割されると、ブランチが作成されます。原因は、オプションの条件ステートメントである可能性があります。 たとえば、step関数はブランチも作成します。 次のGLSLシェーダーは前のシェーダーと同じことを行いますが、分岐を使用しません(これは、パフォーマンスの点で優れています)。
float a = texture2D(uSampler, uv).a; float k = mix(a * 2., 1. - a, step(0.5, a)); gl_FragColor = vec4(1.) * k;
ステップ関数は、<0.5の場合は0を返し、そうでない場合は1を返します。 したがって、ここでもブランチが作成されます-前の例と同様です。
他の変数の改良
少し変更された前の例を考えてみましょう
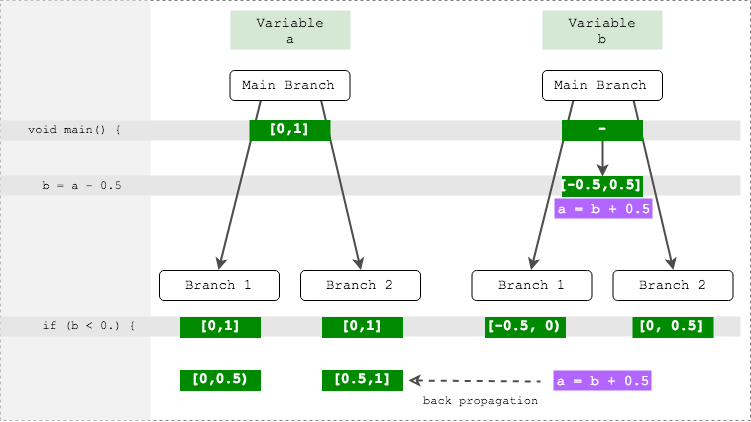
float a = texture2D(uSampler, uv).a; // -> [0,1] float b = a - 0.5; // -> [-0.5, 0.5] if (b < 0.) { k = a * 2.; // k,a -> ? } else { k = 1. - a; }
ここで、ニュアンスは次のとおりです。変数b
に関して分岐が発生し、変数b
を使用して計算が発生します。 つまり、各ブランチ内には範囲b
正しい値がありますが、完全に不必要であり、範囲b
の元の値は完全に正しくありません。
ただし、アナライザーは、 b
から計算することによって範囲b
が取得されたことを確認しましa
。 この情報を覚えていれば、分岐時にアナライザーはすべてのソース変数を調べて、逆計算を実行して範囲を絞り込むことができます。
関数とループ
GLSLには仮想メソッド、関数ポインター、または再帰呼び出しさえないため、すべての関数呼び出しは一意です。 したがって、関数の本体を呼び出しの場所(つまりインライン)に挿入するのが最も簡単です。 これは、コマンドのシーケンスと完全に一致します。
サイクルではもっと複雑です 正式には、GLSLはCのようなforループを完全にサポートしています。 ただし、ほとんどの場合、ループは次のように最も単純な形式で使用されます。
for (int i = 0; i < 12; i++) {}
このようなサイクルは簡単に「展開」できます。 ループの本体を次々に12回挿入します。 その結果、私はこれまで、そのようなオプションのみをサポートすることにしました。
このアプローチの利点は、さらに再利用するためにフラグメント(関数本体やループなど)を記憶する必要なく、アナライザーにストリームでコマンドを発行できることです。
問題をポップアップ
問題#1:明確化が困難または不可能
上記では、ある変数の値を精製するときに、別の変数の値について結論を引き出した場合を検討しました。 そして、この問題は、加算/減算などの演算が関係するときに解決されます。 しかし、たとえば、三角法をどうするか? たとえば、次のような条件:
float a = getSomeValue(); if (sin(a) > 0.) { // a? }
内側の範囲の計算方法は? 円周率のステップを持つ無限の範囲のセットが判明しますが、これは作業するのに非常に不便です。
そして、そのような状況があるかもしれません:
float a = getSomeValue(); // [-10,10] float b = getAnotherValue(); //[-20, 30] float k = a + b; if (k > 0) { //a? b? }
一般的な場合の範囲a
とb
明確化は非現実的です。 したがって、誤検知が発生する可能性があります。

問題#2:依存範囲
この例を考えてみましょう:
uniform float value //-> [0,1]; void main() { float val2 = value - 1.; gl_FragColor = vec4(value - val2); }

はじめに、アナライザーは変数val2
範囲を考慮します- [0,1] - 1 == [-1, 0]
ただし、 value - val2
考慮すると、アナライザーはval2
がvalue
から取得されたことを考慮せず、範囲が互いに独立しているように機能します。 [0,1] - [-1,0] = [0,2]
取得し、エラーを報告します。 実際には、彼は一定の1を持っているべきでした。
考えられる解決策:各変数について、範囲の履歴だけでなく、「家系図」全体も保存する-どの変数が依存していたか、どの操作などを保存するか。 別のことは、この血統を「広げる」ことは容易ではないということです。

問題#3:暗黙的に依存する範囲
以下に例を示します。
float k = sin(a) + cos(a);
ここで、アナライザはk = [-1,1] + [-1,1] = [-2,2]
の範囲を想定します。 間違っている、なぜなら sin(a) + cos(a)
はa
の範囲[-√2, √2]
ます。
sin(a)
の計算結果はsin(a)
正式にはcos(a)
計算結果に依存しません。 ただし、それらは同じ範囲のa
に依存します。
まとめと結論
結局のところ、GLSLのような単純で高度に専門化された言語であっても、値の範囲分析を行うことは簡単な作業ではありません。 言語機能の適用範囲をさらに強化できます。配列、マトリックス、およびすべての組み込み操作のサポートは、単に時間のかかる純粋に技術的なタスクです。 しかし、変数間の依存関係がある状況をどのように解決するか-質問は私にはまだ明確ではありません。 これらの問題を解決しないと、誤検知は避けられず、最終的に静的ノイズ解析の利点を上回るノイズが発生します。
私が出会ったことを考えると、他の言語での値範囲分析のためのいくつかの有名なツールがないことに特に驚きはしません-比較的単純なGLSLよりも明らかに多くの問題があります。 同時に、他の言語では少なくとも単体テストを書くことができますが、ここではできません。
別の解決策は、他の言語からGLSLにコンパイルすることです 。ここ最近、kotlinからのコンパイルに関する記事がありました 。 その後、ソースコードの単体テストを記述し、すべての境界条件をカバーできます。 または、元のkotlinコードを介してシェーダーに送られるデータと同じデータを実行し、起こりうる問題について警告する「ダイナミックアナライザー」を作成します。
そのため、この時点で停止しました。 残念ながら、ライブラリは機能しませんでしたが、おそらくこのプロトタイプは誰かに役立つでしょう。
レビュー用のgithubのリポジトリ:
試すには:
ボーナス:異なるコンパイラフラグを使用したWebアセンブリ機能
最初は、stdlibを使用せずにアナライザーを実行しました。これは、配列とポインターを使用した昔ながらの方法です。 そのとき、出力wasmファイルのサイズが非常に心配でしたので、サイズを小さくしたかったのです。 しかし、ある時点から不快感を感じるようになったため、すべてをstdlibに転送することにしました。スマートポインター、通常のコレクション、それだけです。
したがって、私はライブラリの2つのバージョンのアセンブリの結果を比較する機会を得ました-stdlibの有無。 さて、また、良い/悪いcheerp(およびそれによって使用されるclang)がコードを最適化する方法も確認してください。
したがって、異なる最適化フラグのセット( -O0
、 -O1
、 -O2
、 -O3
、 -Os
、および-Oz
)を使用して両方のバージョンを-Os
し、これらのバージョンの一部について、1,000ブランチで3,000オペレーションの分析速度を測定しました。 私は同意しますが、最大の例ではありませんが、比較分析には私見で十分です。
wasmファイルのサイズに応じて何が起こったのか:
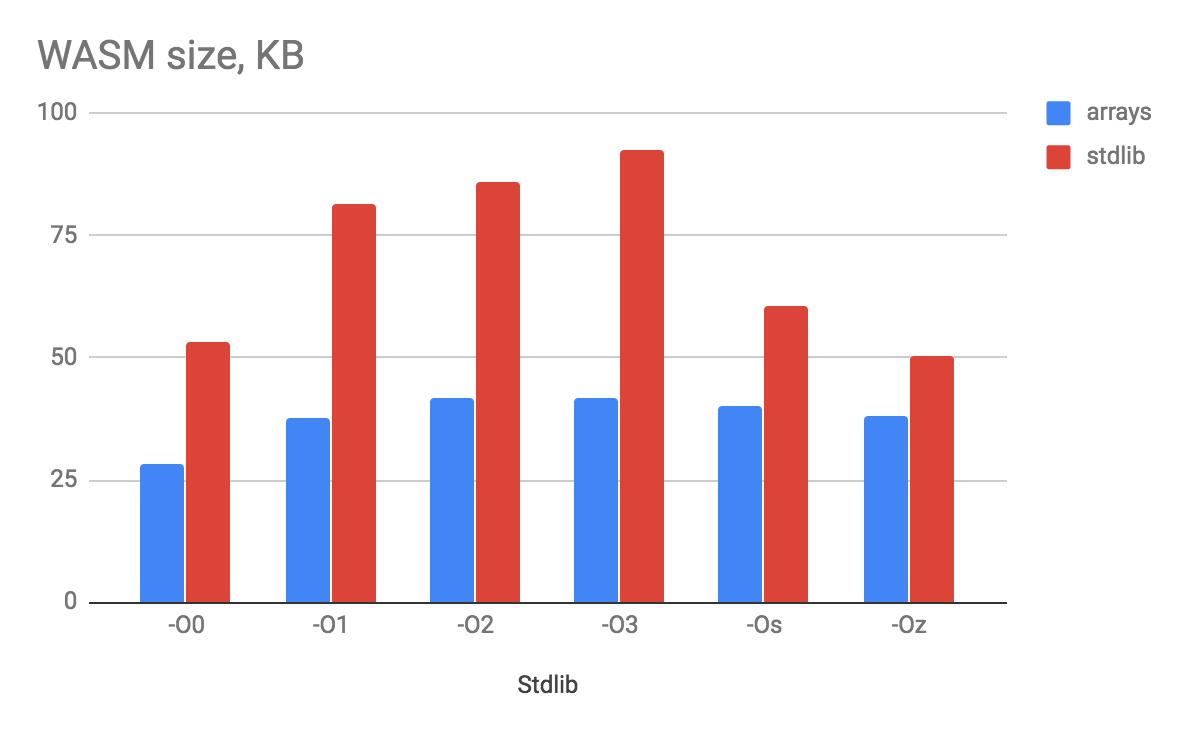
驚くべきことに、「ゼロ」最適化のサイズオプションは、他のほとんどすべてのオプションよりも優れています。 O3
は、世界中のあらゆるものの積極的なインライン化があり、それによってバイナリが膨張すると想定します。 stdlibなしの予想されるバージョンはよりコンパクトですが、それほど多くありません そのような屈辱に耐える 便利なコレクションを扱う喜びを自分自身から奪うこと。
実行速度別:

-O0
と比較すると、 -O3
パンを食べても無駄で-O3
ないことがわかり-O3
。 同時に、stdlibを使用したバージョンと使用しないバージョンの違いは実質的にありません(10回測定しましたが、数字を大きくすると違いは完全になくなると思います)。
2つの点に注目する価値があります。
- グラフは分析の連続した10回の実行からの平均値を示していますが、すべてのテストで最初の分析は残りの分析よりも2倍長く続きました(つまり、120ミリ秒、次は既に60ミリ秒前後)。 WebAssemblyの初期化がおそらく行われました。
-
-O3
フラグを使用して、他のフラグではキャッチしなかったひどく奇妙なバグをいくつか取得しました。 たとえば、minおよびmax関数は、minと同じように突然同じように機能し始めました。
おわりに
ご清聴ありがとうございました。
変数の値が境界を超えないようにします。
そしてここに行きます。